最新Claude 200K严重「虚标」?大神壕掷1016美元实测,90K后性能急剧下降
【新智元导读】月初刚测了GPT-4Turbo上下文真实实力的大神Greg Kamradt又盯上了Anthropic刚更新的Claude2.1。他自己花了1016刀测完之后显示,Claude2.1在上下文长度达到90K后,性能就会出现明显下降。
OpenAI正忙着政变的时候,他们在硅谷最大的竞争对手Anthropic,则悄悄地搞了个大新闻——发布了支持200K上下文的Claude2.1。

看得出来,Claude2.1最大的升级就是将本就很强大的100K上下文能力,又提升了一倍!
200K的上下文不仅可以让用户更方便的处理更多的文档,而且模型出现幻觉的概率也缩小了2倍。同时,还支持系统提示词,以及小工具的使用等等。
而对于大多数普通用户来说,Claude最大的价值就是比GPT-4还强的上下文能力——可以很方便地把一些超过GPT-4上下文长度的长文档丢给Claude处理。
这样使得Claude不再是ChatGPT的下位选择,而成为了能力上和ChatGPT有所互补的另一个强大工具。
所以,Claude2.1一发布,就网友上手实测,看看官方宣称的「200K」上下文能力到底有多强。
Claude2.1200K上下文大考:头尾最清楚,中间几乎记不住
本月初,当OpenAI发布了GPT-4turbo的时候,技术大佬Greg Kamradt就对OpenAI的新模型进行了各方面的测试。
他把YC创始人Paul Graham文章的各个部位都添加了标记性的语句后喂给模型,然后来测试它读取这些语句的能力。
用几乎同样的方法,他对Claude2.1也进行了上下文能力的压力测试。
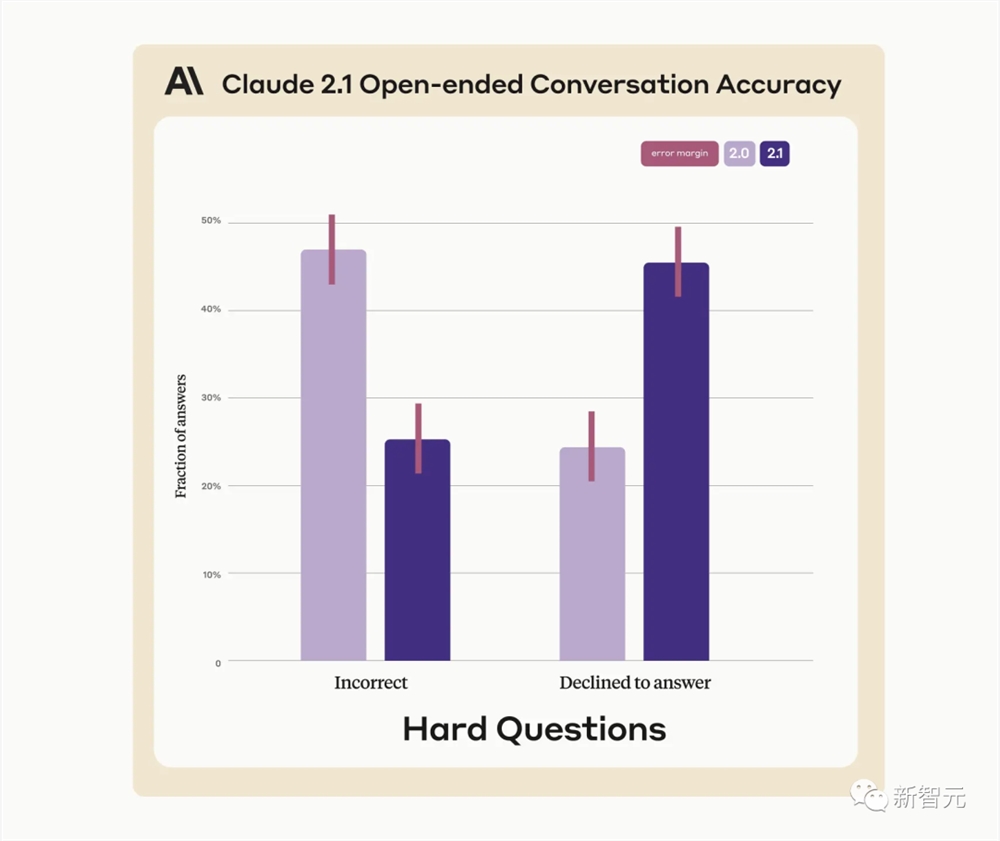
2天时间全网阅读量超过110万
测试结果显示:
在官方标称的极限长度200K下,Claude2.1确实有能力提取出标记性的语句。
位于文档开头的标记性内容,几乎都能被完整的获取到。
但和GPT-4Turbo的情况类似,模型对文档开头内容的获取效果不如对文档底部内容的获取内容。

从90K长度开始,模型对文档底部标记性内容的获取能力就开始下降了。
从图中我们能看到,与GPT-4128K测试结果相比,Claude2.1200K上下文长度,仅仅只是「在200K长度的文章中能读取到信息」。
而GPT-4128K的情况是「在128K长度后出现明显下降」。

如果按照GPT-4128K的质量标准,可能Claude2.1大概只能宣称90K的上下文长度。
按照测试大神Greg说法,的这些测试结果表明:
用户在需要专门设计提示词,或者进行多次测试来衡量上下文检索的准确性。
应用开发者不能直接假设在这些上下文范围内的信息都能被检索到。
更少上下文长度的内容一般来说就代表着更高的检索能力,如果对检索质量要求比较高,就尽量减少喂给模型的上下文长度。
关键信息的位置很重要,开头结尾的信息更容易被记住。
而他也进一步解释了自己做这个对比测试的原因:
他不是为了黑Anthropic,他们的产品真的很棒,正在为所有人构建强大的AI工具。
他作为LLM从业人员,需要对模型的工作原理,优势和局限性有更多的了解和理解。
这些测试肯定也有不周到的地方,但可以帮中使用模型的用户更好的构建基于模型的服务,或者更加有效地使用模型能力。
而在做测试的过程中他还发现了一些细节:
模型能够回忆出的标记事实量很重要,模型在执行多个事实检索任务或综合推理步骤时会降低回忆事实的体量。
更改提示词,问题,以及要回忆的事实和背景上下文都会影响回忆的质量。
Anthropic团队在测试过程中也提供了很多帮助和建议,但这次测试调用API还是花了作者本人1016美元(每100万token的成本为8美元)。
自掏200刀,首测GPT-4128K
在这个月初,OpenAI在开发者大会上发布GPT-4Turbo时,也宣称扩大了上下文能力到128K。
当时,Greg Kamradt直接自掏200刀测了一波(单次输入128K token的成本为1.28美元)。
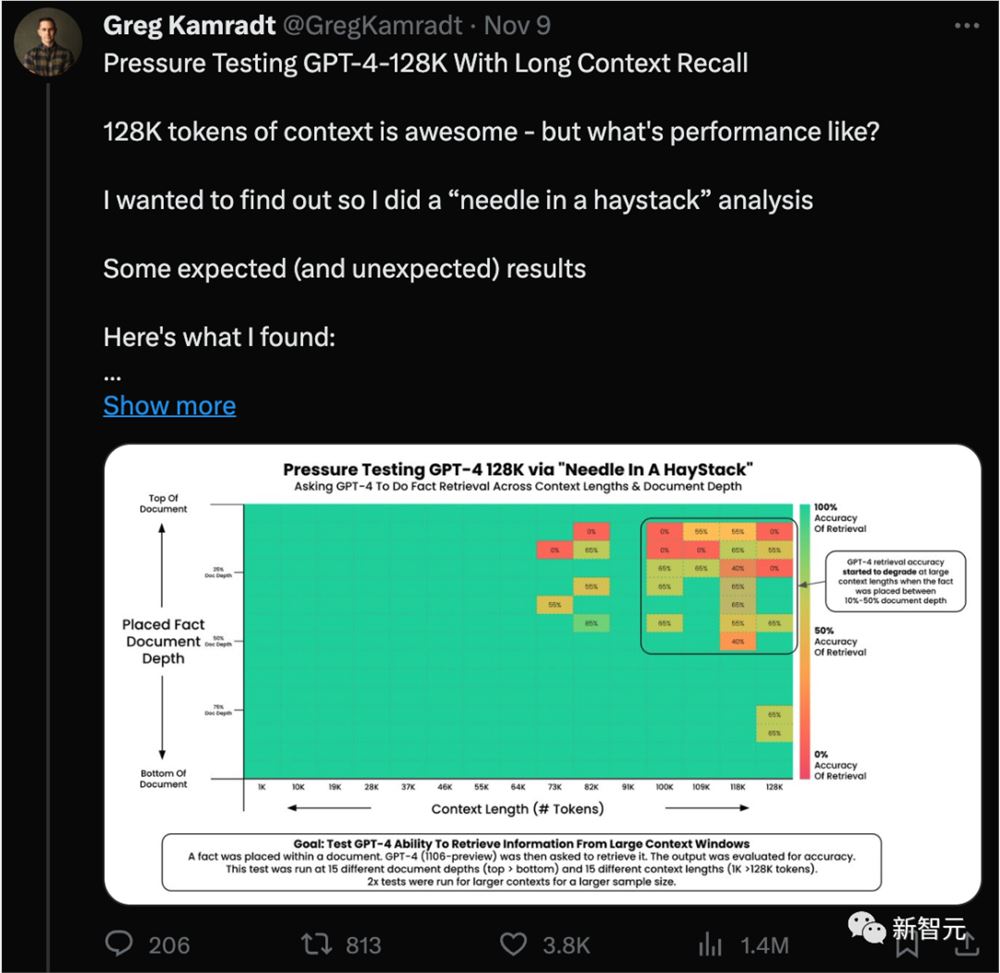
从趋势来看,和这次Anthropic的结果差不多:
当上下文超过73K token时,GPT-4的记忆性能开始下降。
如果需要回忆的事实位于文档的7%到50%深度之间,回忆效果通常较差。
如果事实位于文档开头,无论上下文长度如何,通常都能被成功回忆出来。
而整个测试的详细步骤包括:
利用Paul Graham的文章作为「背景」token。用了他的218篇文章,轻松达到200K token(重复使用了一些文章)。
在文档的不同深度插入一个随机陈述,称述的事实是:「在旧金山最棒的活动是在阳光灿烂的日子里,在多洛雷斯公园享用三明治。」
让GPT-4仅依靠提供的上下文来回答这个问题。
使用另一个模型(同样是 GPT-4)和@LangChainAI 的评估方法来评价GPT-4的回答。
针对15种不同的文档深度(从文档顶部的0%到底部的100%)和15种不同的上下文长度(从1K token到128K token),重复上述步骤。
参考资料:
https://twitter.com/GregKamradt/status/1727018183608193393
https://twitter.com/GregKamradt/status/1722386725635580292
https://the-decoder.com/anthropics-best-claude-2-1-feature-suffers-the-same-fate-as-gpt-4-turbo/
尽管需求激增,过去一年只有 13% 的员工接受AI培训
文章概要:-最新调查显示,尽管员工渴望接受人工智能(AI)培训,但企业在此方面进展缓慢。-Randstad的调查发现,全球范围内有20倍增长的AI技能需求,但仅有13%的员工在过去一年中接受了雇主提供的AI培训。-尽管员工对AI充满期待,但企业却未能提供足够的支持,导致技能需求与培训机会之间存在不平衡。站长网2023-09-07 12:00:510000中文大模型比英文更烧钱,这居然是AI底层原理决定的?
ChatGPT等AI工具的使用正越来越普遍。在与AI交互时,我们知道,输入的提示词差异会对输出结果产生影响。那么,如果相同意思的提示词,用不同语言分别表述,结果差异是否较大?另外,提示词的输入和输出是和模型背后的计算量直接挂钩的。因此,不同语言之间在AI输出和成本消耗方面是不是有着天然的差异性或者说是“不公平性”?这种“不公平性”又是如何产生的呢?站长网2023-09-07 09:01:330000云从科技发布国内首款AI原生数据分析产品DataGPT
今日,云从科技发布了国内首款AI原生数据分析产品——DataGPT。该产品基于云从自主研发的从容多模态大模型,采用新颖的“对话即分析”交互模式,改变了企业对复杂数据的认知和应用方式,使数据解析变得简单自然。DataGPT具备以下六大亮点:1.领先的大模型驱动:运用从容大模型的领先技术,确保数据分析的高效与准确性,能够及时准确地回答任何复杂的统计需求。站长网2024-02-01 17:30:080000网易云十年听歌报告上线 可查看最钟爱的艺人
今日,网易云音乐十年关注报告正式上线,用户在网易云音乐APP搜索“关注报告”即可查询。报告将展示2013年至今的十年间,用户关注最久的艺人、播放时长最长的艺人等信息。站长网2023-07-04 17:12:150000英伟达第四季度营收221亿美元 CEO:人工智能活动“显着加速”
划重点:💰Nvidia第四季度报告营收暴涨265%,净收入激增769%。🚀JensenHuang宣布NvidiaAI作为服务,将由主要云服务提供商托管。💻NvidiaAI超级计算机DGX通过浏览器访问,已在OracleCloud、MicrosoftAzure和GoogleCloud上提供。站长网2024-02-22 10:15:010000