中文大模型比英文更烧钱,这居然是AI底层原理决定的?
ChatGPT等AI工具的使用正越来越普遍。在与AI交互时,我们知道,输入的提示词差异会对输出结果产生影响。那么,如果相同意思的提示词,用不同语言分别表述,结果差异是否较大?另外,提示词的输入和输出是和模型背后的计算量直接挂钩的。因此,不同语言之间在AI输出和成本消耗方面是不是有着天然的差异性或者说是“不公平性”?这种“不公平性”又是如何产生的呢?
据了解,提示词背后其实对应的不是文字,而是token。当接收到用户输入的提示词之后,模型会将输入转换为token列表进行处理和预测,同时将预测的token转换为我们在输出中看到的单词。也就是,token是语言模型处理和生成文本或代码的基本单位。可以关注到,各家厂商会宣称自家模型支持多少token的上下文,而不是说支持的单词或汉字的数量。
影响Token计算的因素
首先,一个token并不对应一个英文单词或一个汉字,token跟单词之间没有具体的换算关系。比如,根据OpenAI发布的token计算工具,hamburger一词被分解为ham、bur和ger,共计 3 个token。另外,同一个词语,如果在两句话中的结构不同,会被记作不同数目的token。
具体token如何计算主要取决于厂商使用的标记化(tokenization)方法。标记化是将输入和输出文本拆分为可由语言模型处理的token的过程。该过程可以帮助模型处理不同的语言、词汇表和格式。而ChatGPT背后采用的是一种称为“字节对编码”(Byte-Pair Encoding,BPE)的标记化方法。
目前来看,一个单词被分解成多少token,跟它的发音和在句子中的结构有关。而不同语言之间的计算差异似乎较大。
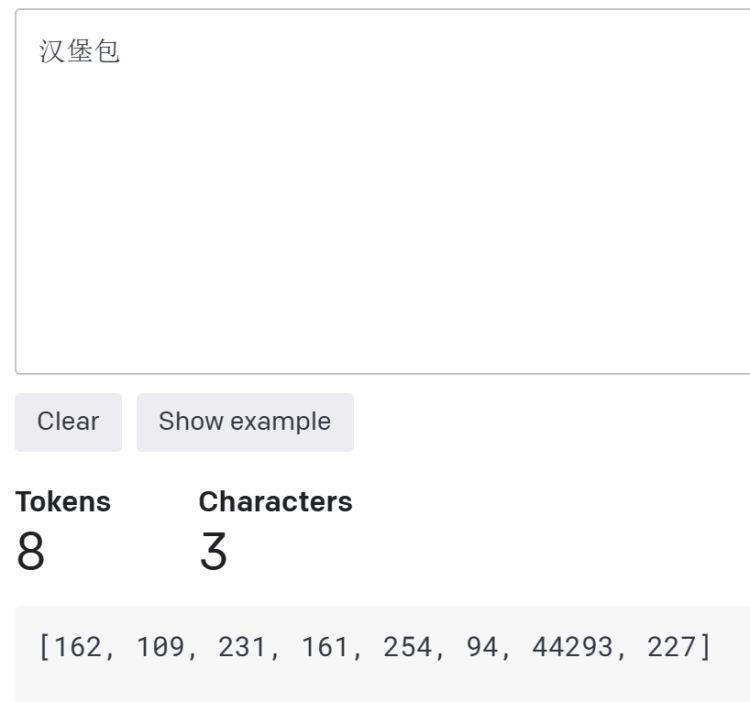
拿“hamburger”对应的中文“汉堡包”来说,这三个汉字被计作 8 个token,也就是被分解成了 8 部分。
再拿一段话来进行中英文语言token计算的“不公平性”对比。
下面是OpenAI官网的一句话:You can use the tool below to understand how a piece of text would be tokenized by the API, and the total count of tokens in that piece of text.这段话共计 33 个token。

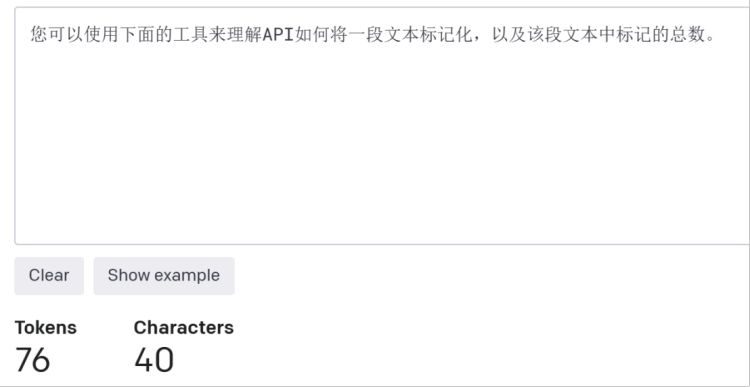
对应的中文为:您可以使用下面的工具来理解API如何将一段文本标记化,以及该段文本中标记的总数。共计76token。
中英文语言在AI上存在天然“不公平”
可以看到,相同意思的中文token数是英文的两倍多。中文和英文在训练和推理上的“不公平性”,也许是因为中文通常一个词汇可以表达多种含义,语言组成较为灵活,中文还有着深厚的文化内涵,具有丰富的语境意义,这极大增加了语言的歧义性和处理难度;英语语法结构较为简单,这使得英语在一些自然语言任务上比中文更容易被处理和理解。
中文需要处理的token更多,模型所消耗的内存和计算资源也就越多,当然所需要的成本也就越大。
同时,ChatGPT虽然可以识别包括中文在内的多种语言,但它训练使用的数据集大都为英文文本,在处理非英语语言时,可能面临语言结构、语法等方面的挑战,进而影响输出效果。近日的一篇题为《多语言语言模型在英语中表现得更好吗?》(Do Multilingual Language Models Think Better in English?)的论文中提到,当将非英文语言翻译成英文后输出的结果,要好于直接使用非英文语言作为提示词的结果。
对中文用户来说,似乎先将中文翻译成英文,然后再与AI交互,似乎效果更好,也更划算。毕竟使用OpenAI的GPT- 4 模型API,每输入 1 千token至少要收费0. 03 美元。
那由于中文语言的复杂性,AI模型在使用中文数据进行准确训练和推理方面可能面临挑战,并增加了中文模型应用和维护的难度。同时,对开发大模型的公司来说,做中文大模型由于需要额外的资源,或许要承担更大的成本。
请查收你的PS5版五一假期“居家旅游”指南
五一假期快到了,又有小伙伴问我“假期打算去哪玩呀?”经过深思熟虑后我告诉他:“我要居家旅行!”小伙伴非常疑惑,如何居家旅行?相信各位看官也想知道居家旅行要怎么实现?那么我告诉你,如果你有一台PS5的话,在即将到来的五一假期期间,你将获得一份全新的假期旅行方式,足不出户也能体验到世界各地的风土人情!也就是我所说的“居家旅行”。站长网2023-05-12 20:29:140000苹果或将于9月13日举行秋季发布会 iPhone15或可9月中旬预定
据彭博社的马克·格尔曼在最新一期的时事通讯中报道,苹果公司的年度iPhone活动预计将于今年9月12日星期二或9月13日星期三举行。按照苹果公司的惯例,新款iPhone的预订将在几天后的9月15日星期五开始,而发售日期则在一周后的9月22日。站长网2023-08-07 10:08:4700002022年创业公司CEO薪酬报告:不如打工人
“你以为CEO的薪资多吗?是你想多了。”作者|王王编辑|蔓蔓周首图来源:tnwcdn创业公司的CEO能拿多少薪水?这个问题不光员工关心、VC关心,广大正在创业和想要创业的人也关心。美国一家咨询机构KruzeConsulting对超过250家多个行业的创业公司进行了调研,发布《2022创业公司CEO薪酬报告》,发现了许多有趣的趋势。站长网2023-04-17 18:34:260002英国学生使用人工智能制作不当儿童图像引发警示
**划重点:**1.🤖学生使用人工智能制作涉嫌儿童性虐待图像。2.😨图像逼真程度令人震惊,有专家呼吁采取紧急行动。3.🚫专业机构建议学校紧急采取措施阻止儿童性虐待材料的传播。近日,英国一组关注儿童虐待和技术的专家警告称,英国学生正在利用人工智能(AI)制作不当儿童图像。站长网2023-11-27 15:04:540000












