南开大学与字节跳动研究人员推出开源AI工具ChatAnything:用文本描述生成虚拟角色
划重点:
1. 🎭 **ChatAnything框架介绍**:南开大学与字节跳动研究人员合作推出一种名为ChatAnything的新型框架,旨在以在线方式生成基于大型语言模型(LLM)的角色的拟人化形象。
2. 🗣️ **MoV和MoD创新概念**:研究团队提出了两个创新概念,即“混合声音”(MoV)和“扩散混合”(MoD),用于实现声音和外观的多样生成。MoV利用文本到语音算法生成预定义音调,而MoD结合文本到图像生成技术和说话头算法简化生成交互式对象的过程。
3. 🧠 **ChatAnything框架的挑战与解决方案**:研究人员在使用当前模型生成的拟人化对象时遇到了检测困难,提出通过像素级引导注入人脸关键点以增加检测率。他们还介绍了ChatAnything框架的四个主要模块,包括LLM控制模块、肖像初始化器、文本到语音模块混合和动作生成模块。
南开大学与字节跳动研究人员合作推出了一项引人注目的研究,发布了一种名为ChatAnything的全新AI框架。该框架专注于通过在线方式生成基于大型语言模型(LLM)的角色的拟人化形象,从而创造具有定制视觉外观、个性和语调的人物。
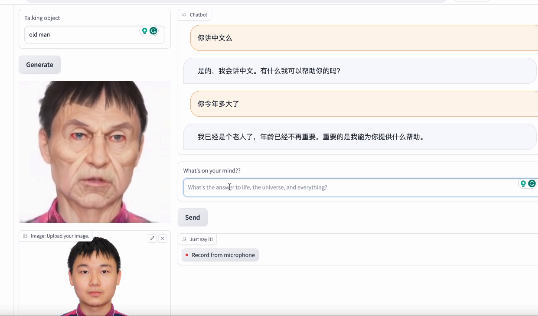
简答的说,ChatAnything是一个创新的产品,利用语言模型技术为LLM角色创建具有视觉外观、个性和语调的拟人化角色。通过混合语音和外观生成概念,用户只需几个文本输入即可定制角色。该产品采用面部标志控制和评估数据集,通过像素级引导实现更高的人类面部特征生成率。ChatAnything支持文本和图像输入,为用户提供创造独特虚拟角色的自由度。

研究团队充分利用了LLMs的上下文学习能力,通过精心设计的系统提示生成具有个性的拟人化形象。他们提出了两个创新概念:混合声音(MoV)和扩散混合(MoD),以实现声音和外观的多样生成。MoV使用文本到语音(TTS)算法生成预定义音调,根据用户提供的文本描述选择最匹配的音调。而MoD则结合了文本到图像生成技术和说话头算法,简化了生成交互式对象的过程。
然而,研究人员在使用当前模型生成的拟人化对象时遇到了一个挑战,即这些对象通常无法被预先训练的面部关键点检测器检测到,导致面部运动生成失败。为了解决这个问题,他们在图像生成过程中引入了像素级的引导,注入人脸关键点,显著提高了面部关键点检测率,从而实现了基于生成的语音内容的自动面部动画。
研究人员在论文中详细讨论了大型语言模型(LLMs)的最新进展以及它们在上下文学习方面的能力,将它们置于学术讨论的前沿。他们强调了需要一个能够生成具有定制个性、语音和视觉外观的LLM增强人物的框架的重要性。对于个性生成,他们利用LLMs的上下文学习能力,使用文本到语音(TTS)API创建了一个声音模块池,MoV模块根据用户文本输入选择音调。
研究人员进一步介绍了ChatAnything框架的四个主要模块,包括LLM控制模块、肖像初始化器、文本到语音模块混合和动作生成模块。他们通过引入扩散模型、语音变换器和结构控制,创建了一个模块化和灵活的系统。为了验证引导扩散的有效性,研究人员创建了一个包含不同类别提示的验证数据集,并使用预训练的面部关键点检测器评估了面部关键点检测率,展示了他们提出的方法的影响。
ChatAnything框架为生成具有拟人特征的LLM增强人物提供了全面的解决方案。研究人员在解决面部关键点检测方面提出了创新性的解决方案,并在验证数据集中取得了令人鼓舞的结果。这项工作为将生成模型与说话头算法相结合以及改善数据分布的对齐提供了未来研究的可能性。
项目地址:https://chatanything.github.io
相关论文:https://arxiv.org/abs/2311.06772作者:AI_Fox https://www.bilibili.com/read/cv27716378/?jump_opus=1出处:bilibili
实测学而思MathGPT大模型:中小学数学解题正确率有望在全球范围内创造新 SOTA
国内首个数学大模型MathGPT开放内测了,不上手试试怎么行?第一印象上,最明显的就是:啪的一下,很快啊~题目识别到对话框,结果不光答案准确,还就给出了具体的公式步骤、详细解析。并且支持公式输入和修改。这着实是数理爱好者福音了!要知道市面上GPT-4在内的通用大模型,都无法实现这一点。站长网2023-08-30 18:11:330000免费使用,媲美Midjourney!微软在Bing Chat等提供—DALL-E 3
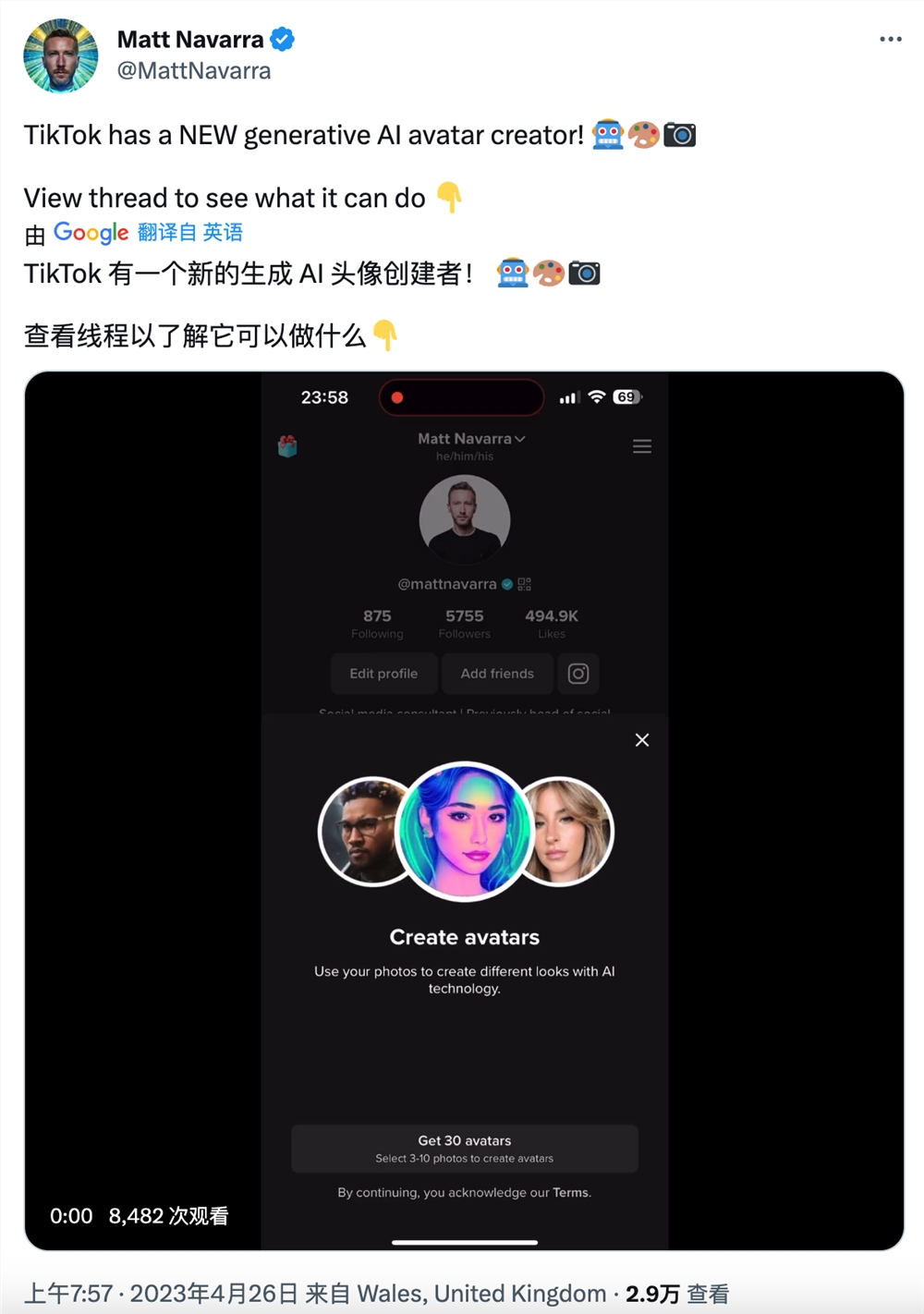
微软在官网宣布,将OpenAI最新模型DALL-E3集成在BingChat和BingImageCreate中,并免费提供给用户使用。据悉,DALL-E3是一款类Midjourney产品,通过文本就能生成二次元、3D、朋克、涂鸦、素描、黑白、极简、印象派、位面像素等几十种类型图片。例如,生成一个东方巨龙云雾缭绕冲上云霄,很快就能获得多张精美图片。站长网2023-10-08 08:59:400005TikTok 测试添加 AI 头像生成功能:上传照片生成风格化插图形象
TikTok周三向媒体证实,该公司正在测试一个新选项,让用户为他们的个人资料照片创建人工智能生成的头像,此举有可能将人工智能技术的最新进展置于数百万用户的面前和中心。根据社交媒体顾问MattNavarra的一篇贴文,这项新功能似乎是根据用户上传的图片创建一个风格化的插图形象,他是第一个发现这个选项的人。站长网2023-04-27 09:03:130000B站2023最美的夜跨年晚会官宣 将于 12 月 31 日 举行
今天,B站2023年跨晚阵容终于全部官宣,将于12月31日20:00举行,用户可以上B站搜索“2023最美的夜”预约直播。据悉本次跨年晚会来自二次元的嘉宾包括了:红楼梦、猫和老鼠、蜘蛛侠、奥特曼、葫芦兄弟、猪猪侠、铠甲勇士、洛天依、王者荣耀等热门IP角色。站长网2023-12-25 18:52:310000芯片制造商KLA业绩超预期 受益于AI领域投资增加
制造芯片工具的厂商KLA公司预测,其第一季度的收入和利润都超过了华尔街的预期。该公司的业绩受益于人工智能(AI)投资的增加,因为各个行业的企业都在争相将AI工具融入其运营中。KLA公司在芯片供应链中发挥着关键作用,从AI技术的需求增长中受益。站长网2023-07-28 14:09:370000