Stability AI推出视频生成模型Stable Video Diffusion
**划重点:**
1. 🎥 Stability AI发布开源的视频生成模型Stable Video Diffusion,基于其现有的Stable Diffusion文本转图像模型,可通过动画化现有图像生成视频。
2. ⚠️ 模型目前处于“研究预览”阶段,使用者需同意特定使用条款,限制其应用于“教育或创意工具”等领域,禁止用于“真实事件或人物的表现”。
3. 💰 Stability AI计划商业化应用,已筹集超过1.25亿美元资金,但面临财务困境和高烧钱速度。公司前高管离职,曾提出更严格的版权使用方针。
Stability AI近日推出了名为Stable Video Diffusion的视频生成模型,该模型基于该公司现有的Stable Diffusion文本转图像模型,能够通过对现有图像进行动画化生成视频。与其他AI公司不同,Stable Video Diffusion在开源领域提供了少数几个视频生成模型之一。

然而,需要注意的是,该模型目前处于“研究预览”阶段,使用者必须同意特定的使用条款,明确规定了其预期应用领域,如“教育或创意工具”等,同时禁止用于“真实事件或人物的表现”。考虑到过去类似AI研究预览的历史,有可能该模型很快会在暗网上流传,引发对其滥用的担忧,特别是因为它似乎没有内置的内容过滤器。
Stable Video Diffusion提供两个模型,分别为SVD和SVD-XT。其中,SVD将静止图像转换为14帧的576x1024视频,而SVD-XT在相同的架构下将帧数提升至24。这两者都能以每秒3到30帧的速度生成视频。白皮书显示,这两个模型最初在数百万个视频的数据集上进行训练,然后在数十万到百万数量级的较小数据集上进行“微调”。
模型生成的四秒视频片段质量相当高,被认为在某些方面可以与Meta、Google以及其他AI初创公司的视频生成模型相媲美。然而,Stable Video Diffusion存在一些局限性,例如不能生成没有运动或慢速摄像机移动的视频,无法通过文本控制,不能呈现文本(至少不能清晰可辨认),也不能一致地生成面部和人物。
尽管存在这些局限性,Stability AI指出这些模型是相当可扩展的,并可适应生成物体的360度视图等用例。公司计划推出“一系列”建立在SVD和SVD-XT基础上并扩展其功能的模型,以及一款将文本提示引入网络模型的“文本到视频”工具。最终目标是商业化,认为Stable Video Diffusion在“广告、教育、娱乐等领域都具有潜在应用”。
然而,Stability AI目前面临财务问题。据报道,公司最近通过可转债筹集了2500万美元,使其总融资达到1.25亿美元。但是,公司并未以更高的估值完成新一轮融资,最后一次估值为10亿美元。Stability AI曾计划在未来几个月内寻求四倍于此的估值,尽管公司收入较低,烧钱速度较高。
在这一时期,Stability AI还面临一次高管离职。公司副总裁Ed Newton-Rex在一份公开信中表示,他因对如何使用版权数据进行争论而离开了公司。这也是公司面临的另一次挫折,因为Newton-Rex曾在稳定AI音乐生成工具Stable Audio的推出中扮演了关键角色。
官方演示视频: https://www.youtube.com/watch?v=G7mihAy691g
东方甄选入淘:没带董宇辉,首秀带货1.75亿却不日播?
单场GMV达1.75亿,交易订单总数超过158万单,直播间粉丝增长至200万......这是东方甄选入淘首秀交出的成绩单。8月29日早上,东方甄选正式在淘宝开播,一直播到了晚上。俞敏洪、孙旭东两位高管不仅亲临直播间,还身穿厨师服在直播间进行厨艺比拼。尽管头部机构、主播跨平台开播已不是什么新鲜事,但东方甄选入淘直播依然备受关注。站长网2023-08-31 14:09:050000虚幻引擎 5.2 发布,原生支持 Apple Silicon
EpicGames宣布推出虚幻引擎5.2(UnrealEngine5.2/UE5.2)。EpicGames表示,虚幻引擎5.2进一步扩展了UE5开创性的工具集,继续实现最先进的实时3D创作工具的承诺。此外,虚幻引擎5.2还推动了开发者期望的开箱即用的界限,提供了更多的新功能。站长网2023-05-16 11:35:170000从3个核心维度,理解百度战略布局电商业务的底层逻辑
1最近几年,百度公司的表现让笔者刮目相看。除了在搜索引擎主战场稳住基本盘之外,其正在多个新业务领域遍地开花。站长网2023-05-26 18:12:070001比Win版便宜!华为MateBook 14 Linux版发布:国补4799元起 外观有这些变化
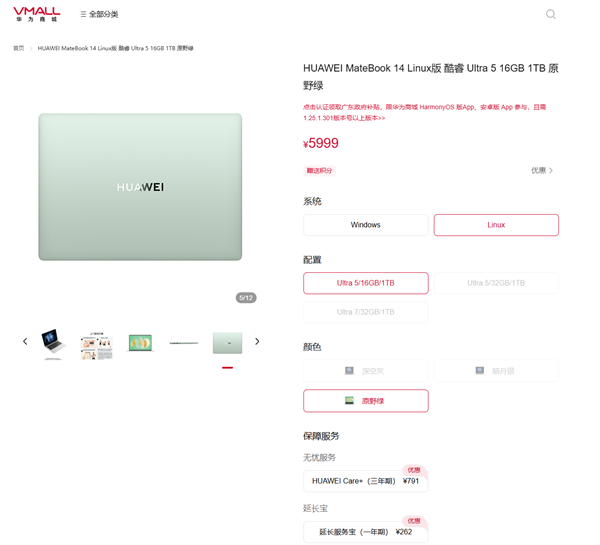
快科技4月13日消息,日前,华为MateBook14Linux版发布,可选Ultra5/16GB/1TBLinux版、Ultra5/32GB/1TBLinux版、Ultra7/32GB/1TBLinux版三款配置,售价分别为5999元、6699元、7999元,目前已经开售。站长网2025-04-13 10:27:380000人工智能之父Geoffrey Hinton 警告科技发展难预知 AI 可能会取代人类
据国外媒体报道,被称为“人工智能之父”的杰弗里·辛顿最近在接受《60分钟》采访时警告,人工智能的快速发展存在巨大隐忧,科技有可能在某个时间点超越并最终取代人类。辛顿表示,人工智能可能在5年内就能比人类进行更好的推理。他担心人类是否能充分理解这个飞速发展的技术。一旦事情变得极为复杂,人类对技术内部运行机制的理解就会很有限,正如人类无法完全洞悉大脑的神秘运作。站长网2023-10-10 15:02:100000