南洋理工大学研发DIRFA:仅需音频和照片,就能创造逼真数字人
要点:
1. 新加坡南洋理工大学的研究团队开发了一款名为DIverse yet Realistic Facial Animations(DIRFA)的计算机程序,可以仅通过音频和一个人的照片创建展示说话者面部表情和头部动作的逼真视频。
2. DIRFA是一种基于人工智能的程序,通过训练模型使用来自The VoxCeleb2Dataset的超过一百万个音频视觉剪辑,以预测语音中的线索并将其与面部表情和头部动作关联,从而生成与口头音频同步的3D视频。
3. 该技术有望在医疗保健等领域推动新应用,提高虚拟助手和聊天机器人的逼真程度,同时对于有言语或面部障碍的个体,可以通过表达性的化身或数字表示来帮助他们传达思想和情感,增强他们的沟通能力。
在这项最新的研究中,新加坡南洋理工大学的研究团队成功开发了一项名为DIverse yet Realistic Facial Animations(DIRFA)的计算机程序,该程序通过仅使用音频和一个人的照片,就能够生成逼真的视频,展示说话者的面部表情和头部动作。DIRFA是一种基于人工智能的程序,通过训练模型使用超过一百万个音频视觉剪辑,从而能够预测语音中的线索,并将其与面部表情和头部动作关联,从而生成与口头音频同步的3D视频。

图源备注:图片由AI生成,图片授权服务商Midjourney
研究人员表示,相较于现有方法,DIRFA在处理姿势变化和情感控制方面取得了显著进展。这一技术创新有望在医疗保健等多个领域推动新应用,提高虚拟助手和聊天机器人的逼真程度,改善用户体验。同时,对于那些有言语或面部障碍的个体,DIRFA还可以作为一个强大的工具,通过表达性的化身或数字表示帮助他们传达思想和情感,提升他们的沟通能力。
研究团队的首席作者表示,语音表现出多种变化,而他们的方法从音频表示学的角度出发,致力于提高人工智能和机器学习的性能。此外,研究者们还指出,DIRFA能够生成具有准确的嘴唇运动、生动的面部表情和自然头部姿势的说话面孔。
然而,研究团队也表示他们正在努力改进DIRFA的界面,以允许用户控制某些输出,比如调整表情。此外,他们计划通过使用更广泛的数据集来进一步优化DIRFA的面部表情,其中包括更多不同的面部表情和语音音频剪辑。
总体而言,这项研究为多媒体交流领域带来了深远而革命性的影响,通过结合人工智能和机器学习等技术,实现了高度逼真的个体说话视频的创作。
AITO问界系列5月交付量5629辆 环比增长22.7%
AITO汽车公布数据称,AITO问界系列5月交付量5629辆,环比增长22.7%。仅用时15个月,AITO问界迎来第10万辆整车的正式下线,成为最快达成这一里程碑的新能源汽车品牌。AITO汽车表示,未来,将继续致力于“智能化下半场”,为用户带来更加满意的产品与服务。站长网2023-06-02 00:11:250000知乎盐言故事和短篇互为最优解
「短」正在成为内容行业的新趋势。在过去一年,观众越来越追求在短时间内进行完整的内容消费体验。而在供给端,行业一直在试图生产更轻量化的内容,作为表征,短剧成了这一年巨大的内容风口,影视公司纷纷寻找更精炼的IP作为改编对象。站长网2024-01-11 09:23:130000Sora给你带来的真实变化
距离Sora的发布已经有一段时间,但对它的讨论还在持续。讨论话题已经从Sora会不会取代人类、现实会不会不存在、中国能不能做出来类似模型,变成了“将来如何用Sora搞钱”“AIGC赛道有没有机会创业”。所以,在继《Sora给中国AI带来的真实变化》后,我们想要多聊一个话题,就是Sora代表的新算法、新能力,将给对AI有好奇,也有一些忐忑的你,带来什么变化。站长网2024-03-19 12:18:430000支付宝上线新功能:免费生成AI写真 还可导出高清图
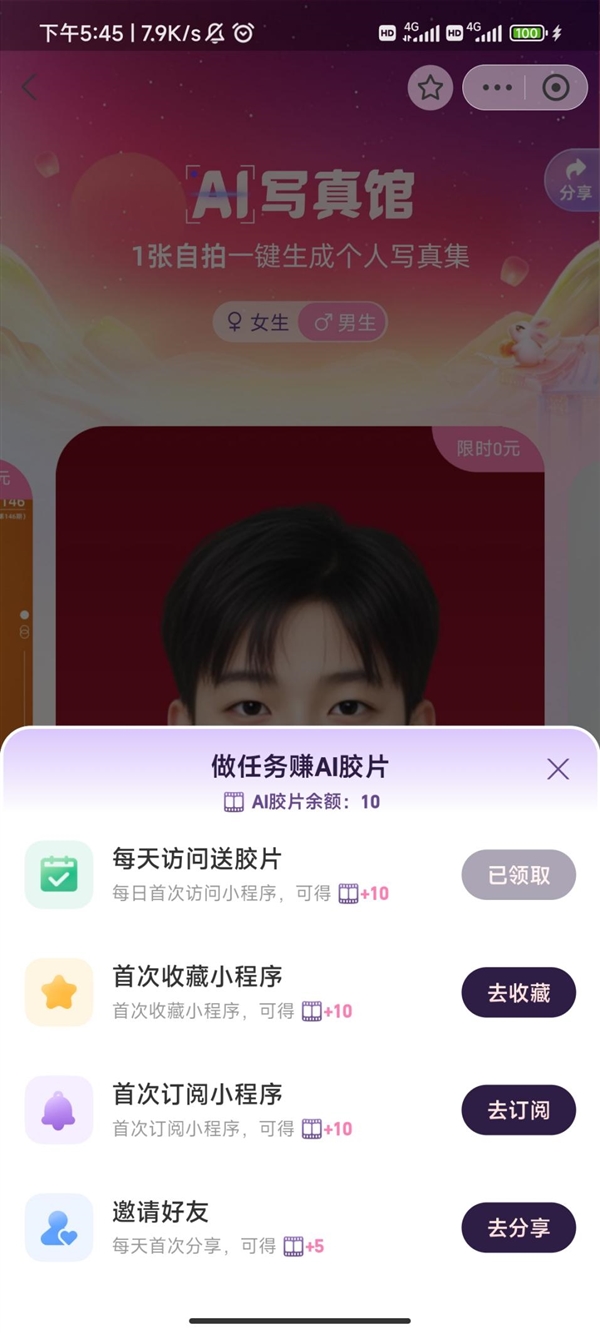
快科技11月7日消息,支付宝近日上线了免费的AI写真功能,在首页直接搜索AI写真馆”即可进入小程序使用。该小程序的主体信息为支付宝子公司吱信(上海)网络技术有限公司,小程序官方介绍为:1张自拍一键生成个人写真集。目前为限时免费阶段,每天登录小程序就能获得10张胶片,1张胶片可以生成4张写真,做小任务还能获得额外胶片。站长网2023-11-07 21:54:270000iPhone mini“重出江湖”?15系列阵列遭爆料,网友:库克真会整活
去年的iPhone14系列产品线路有所调整,取消小屏的mini,取而代之的是大屏Plus。这也是库克用mini实践得出来的机型,既然小屏叫好不叫座,那就干脆来个大屏?但iPhone14Plus明显遇冷,一经上市立刻破发。截止目前,128G版本iPhone14Plus的市场价格要比官网便宜800元左右,512G版本更是骤降超千元。站长网2023-05-23 12:23:000003