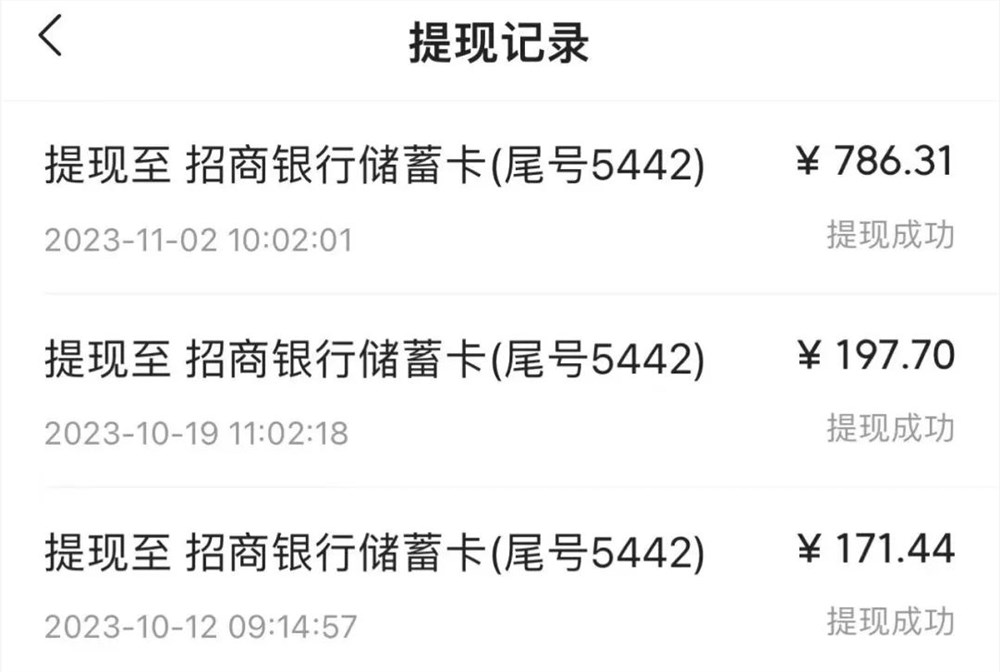
李开复零一万物公司回应大模型争议:承认模型结构基于GPT结构
要点:
1. 李开复旗下公司「零一万物」的大模型 Yi-34B 引发争议,因研究者发现其基本采用 LLaMA 架构,但只是对两个张量进行了重命名。
2. 有关该模型的性能和成就,包括上下文窗口大小超过200k、一次处理40万汉字、在 Hugging Face 全球开源模型排行榜中获得双料冠军等。
3. 在社区中有人指出,Yi-34B 实际上是对 LLaMA 代码的一次重构,但未作实质性改变,引起对虚假宣传、许可证违规等问题的疑虑。公司回应表示基于 GPT 结构,并在模型训练中遇到的一些需求导致了代码重命名。
最近,「零一万物」公司旗下的大模型 Yi-34B 因使用 LLaMA 架构但改变张量名引发争议。这一争议中,研究者指出其代码实际上是对 LLaMA 代码的一次重构,只是未作实质性改变。社区担心这可能违反了许可证规定,且未经过框架支持的外部代码附加可能存在安全风险。
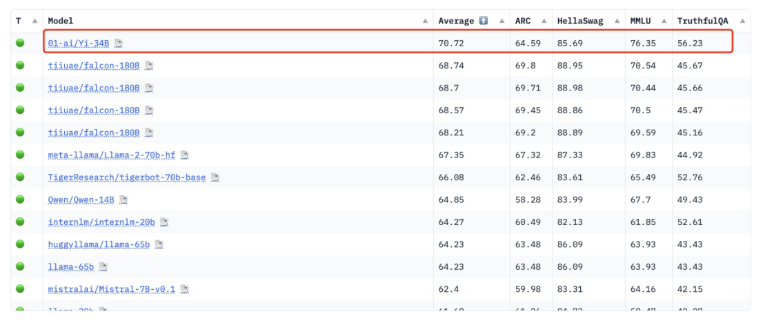
Yi-34B 的成就在开源大模型领域引起了广泛关注,其上下文窗口大小超过200k,能处理40万汉字,成为全球开源模型双料冠军。然而,争议的核心在于其是否真正符合 LLaMA 的许可协议,以及对模型代码的更改是否属于虚假宣传。
在社区的讨论中,有人提到模型的性能参数和配置存在疑虑,包括模型被标榜为32K 模型实际上配置为4K 模型的问题。此外,对于模型的微调数据和基准测试的信息也没有充分提供,引起了社区的疑虑。

「零一万物」公司回应称,他们的模型结构基于 GPT 成熟结构,但在训练实验中由于需求对代码进行了更名。他们强调模型的结构只是其中一部分,投入了大量研发工作在数据工程、训练方法、评估方法等方面,这是他们在大模型预训练阶段的核心技术护城河。最后,他们表示尊重社区的反馈,将代码进行更新以更好地融入 Transformer 生态。
综合来看,争议集中在「零一万物」公司的 Yi-34B 模型是否违反了开源协议,以及其在性能参数和代码修改上的透明度。这一事件提醒开源社区对于模型的合规性和透明度的重要性,同时也反映了在开源领域中公司的技术选择可能引发广泛关注和争议的现实。
新手写头条,第一个月3000元。
各位村民好,我是村长。别人写头条文章,一篇少则四五十、一二百,多则上千元。为什么你写的时候,却只有几毛钱、几分钱。那是因为你真的写错了,不会写。我注册了一个新头条号,选了一个领域,开始认真写头条也就三四个的时间,目前每个月平均能从头条获取2000多收益。这笔钱的确不多,但是比多数人写了三个月、6个月甚至一年还强。那么我是怎么做到的呢?今天我就和大家一起来分享。01选对题目站长网2023-11-13 22:23:520000REDMI Turbo 4 Pro明年4月发布:升级骁龙8S至尊版+7K级电池
快科技12月23日消息,{tag_keyurl_4}Turbo4即将发布,该机将首发联发科天玑8400芯片,是中端性能神机。值得注意的是,据数码闲聊站爆料,这次该系列还将首次推出Pro版,预计REDMITurbo4Pro机型将会在明年4月发布。该机核心升级为骁龙8S至尊版,采用骁龙8至尊版的同工艺、同架构等,直接用上全大核CPU,综合体验可能会比第三代骁龙8更强。0000AI写高考作文,才是真的大材小用了
2023年高考刚结束,“AI考生”的答题热情却迎来新的高潮。6月7日,随着各种“高考”话题一起登上热搜的还有“AI写高考作文”。高考题目一出来,就有人从数学、语文、英语三大学科对讯飞星火、ChatGPT和各家模型进行了高考真题对比测试。先上结果:站长网2023-06-12 23:35:290000脉脉:不存在匿名发帖情况 发帖时可以选择实名或者唯一昵称
近期,网络匿名发帖引发了广泛关注和争议。知乎和脉脉平台都采取了相应措施,其中知乎宣布取消匿名发帖功能。而脉脉则表示,脉脉在2021年就升级了用户ID管理机制。用户必须经过后台绑定手机号加实名认证才有发帖权限,发帖时可以选择实名或者唯一昵称,和目前主流的社区机制相似,此后脉脉平台不存在“匿名发帖”的情况。此外,脉脉还表示倡导用户负责任地发言,反对任何网络暴力。站长网2023-07-10 15:18:090000为什么B站还在强调DAU破亿
伴随着流量大盘趋于稳定,互联网平台进入存量博弈阶段,在很多人眼里,高增长和高投入成为了一个强绑定的词。但总有人想要走出一条不一样的路。11月29日晚,B站交出了一份大幅减亏的三季报。财报显示三季度公司营收58.1亿元,三季度B站持续增利减亏,毛利率连续五个季度环比提升,从去年同期的18%增至25%。站长网2023-12-01 13:56:060000