一张照片生成3D头像!苹果新模型击败StyleGAN2,表情光线都能调,网友:要用于MR?
随便一张照片,就可生成3D头像。而且光线真实,任意角度可调。
这是苹果的最新黑科技生成框架FaceLit。
正如其名,FaceLit的特色就是可以将人脸“点亮”。
“自带光环”的FaceLit在易用性上也不输同类,甚至更胜一筹——
进行3D建模时,需要的照片素材无需专门选择角度,数量上也只需一张。
甚至对表情、发型、眼镜等元素进行调节时,也不需要额外素材。
而传统的头像合成工具或者需要多张图片才能工作,或者对照片角度有刁钻的要求。
正是凭借这一创新,FaceLit获得了3.5的FID评分,较同类产品直接高出了25%。
改进式EG3D合成人像,光线信息单独处理
下面就来看一下FaceLit具体是如何实现头像合成的。
总的来说,苹果采用了将人物本体与光线分别处理再进行叠加的策略。
早期的三维人像合成工具在转换过程中可能产生形变。
而爆火的NeRF通过将场景拆分成具体因素,提高了3D图像合成效果,改善了这一问题。
但苹果团队认为,在可控性方面,NeRF仍存有不足之处。
于是,在EG3D框架的基础上,苹果创造了FaceLit的合成模型。
EG3D通过三平面解码器,赋予了二维卷积神经网络生成渲染3D模型所需深度参数的能力。
苹果团队对标准的EG3D训练方式进行了扩展,并将之转化成了FaceLit框架。
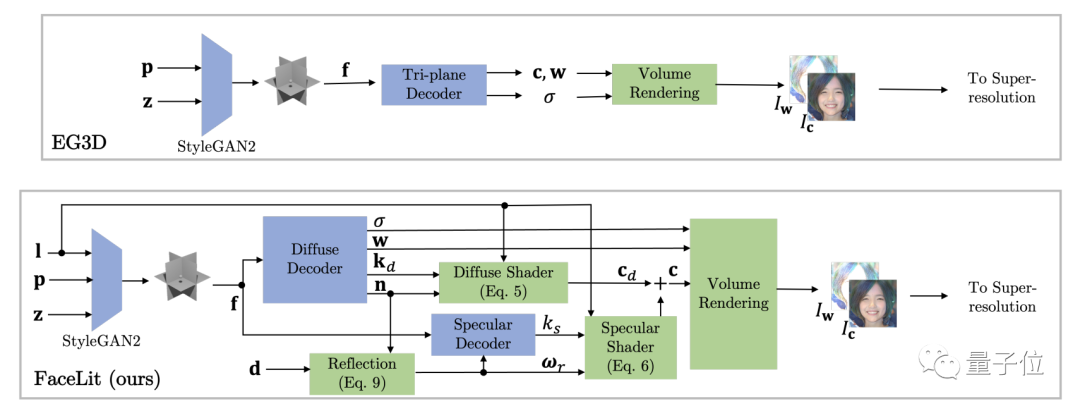
△FaceLit与传统EG3D渲染流程对比图
标准的ED3G使用相机位置p参数作为基本输入参数。
在建立GAN2操作时,苹果在EG3D的基础上加入了光照参数l。
苹果选择了经过球形谐波方式简化后的Phong反射模型作为处理光源的物理基础。
光照参数l就是在这一基础之上独立处理得到的。
在自然界中,反射包括镜面反射和漫反射两种形式。
△不同镜面反射率条件下的效果对比
因此,苹果在ED3G模型中加入了镜面反射解码器和漫反射解码器。
它们替代了可以直接得到颜色c、密度σ数据的三平面解码器。
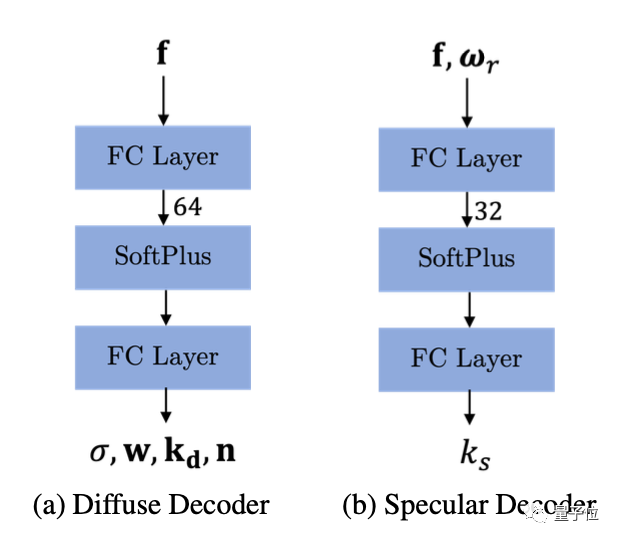
△反射解码器流程示意图
通过对GAN2产生的数据进行再次解码,可以得到镜面反射率ks和漫反射率kd。
然后再通过两种反射着色器得到颜色c,密度σ则由漫反射解码器计算得出。
最终,FaceLit以与三平面解码器相同的参数(c,w,σ)渲染图像,并进行分辨率优化。
有的放矢设计训练策略,数据无需人工标注
生成框架已有,那就来到训练阶段,其特点在于训练过程中无需人工标注。
方法论层面,在训练时,团队使用了FFHQ、MetFaces和CelebA-HQ数据集。
对于不同的数据集,苹果使用了不同的训练方式。
FFHQ包含了7万余条人脸数据,其训练分为两个阶段:先在较低的分辨率下训练,再提高分辨率再次进行。
对于包含2万数据量的CelebA-HQ,训练不需要分阶段进行。
而对于更小的MetFAces,则只需要通过ADA扩容的方式,使用预训练的FFHQ进行优化调整即可。
定性地看,训练结果在机位、光源和反射高光等方面都有出色的表现,图中的细节也有所增强。
△FaceLit生成的头像(左侧四列)唇齿部位的细节进行了明显重构
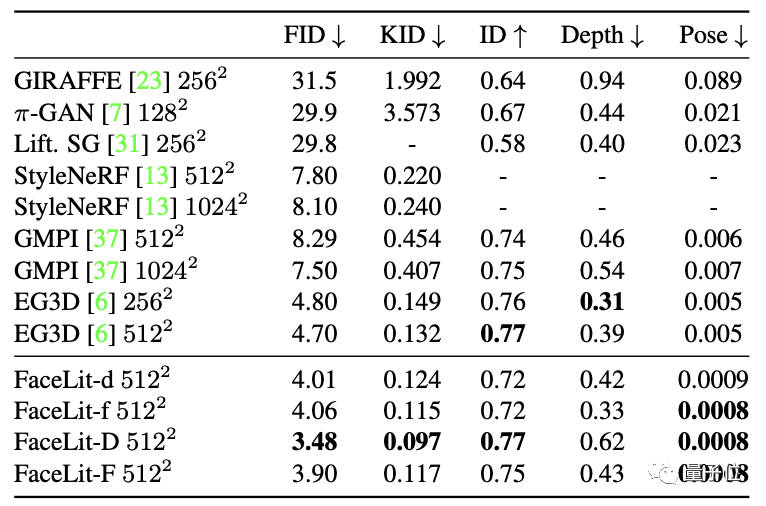
定量结果同样表明,FaceLit在FID、KID等指标上均优于包括标准EG3D在内的传统生成方式。
在使用FFHQ作为训练集的条件下,各生成方式的表现如下表,不难看出FaceLit拥有最低的FID和KID值。
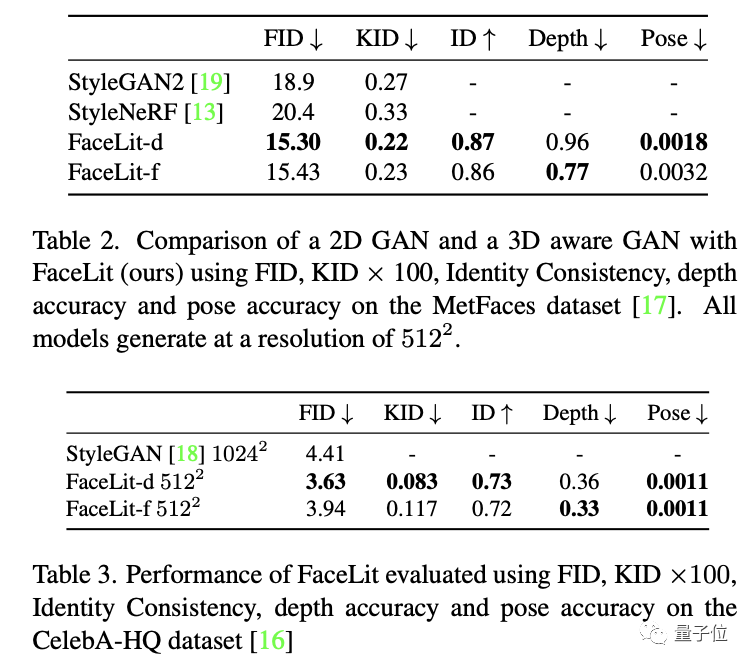
而相比于英伟达的StyleGAN2,FaceLit的表现依旧出色:
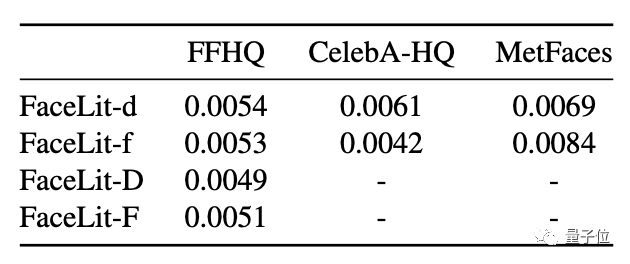
光线准确度方面,FaceLit在使用三种不同训练数据集的情况下,与人工设定的标准值平均均方误差均低于0.01。
网友:人们低估了苹果AI
消息发出后,便有网友认为“这是对更重磅产品的预热”。
更有网友直接推测,FaceLit的出现标示着人工智能将进军AR和VR领域,苹果的混合现实将最终实现商用……
也有网友认为,FaceLit不会商用,否则苹果才不会以论文的形式发表。

针对FaceLit本身,也有网友表示,除了LLM,其他都是浮云,他们(苹果)如果不开发LLM,就没有未来。
但这位网友同时也说,苹果可能已经在做(LLM)了。
相应的,也有网友称人们“低估了苹果在AI领域的深度”。
所以各位网友对苹果在AI领域还有什么样的期待呢?
论文地址:
https://arxiv.org/abs/2303.15437
GitHub地址:
https://github.com/apple/ml-facelit
参考链接:
https://twitter.com/AlphaSignalAI/status/1648361623004774400
国家邮政局:“双11”当天全国快递业务量达6.39亿件
国家邮政局监测数据显示,2023年11月1日至11日,全国邮政快递企业共揽收快递包裹52.64亿件,同比增长23.22%,日均业务量是平日业务量的1.4倍。其中11月11日当天,共揽收快递包裹6.39亿件,是平日业务量的1.87倍,同比增长15.76%。站长网2023-11-13 17:20:320000网易云音乐官宣故障已陆续恢复:没有删库跑路 送全员7天会员
快科技8月19日消息,今日网易云音乐崩溃的消息引发全网关注,在经过约三个小时的修复之后,官方终于宣布故障解决,已经陆续恢复正常。网易云音乐发文道歉,并表示:作为补偿,8月20日0-24时,云音乐搜畅听音乐,可领取7天会员权益到您的账户(具体规则请见活动页面)。”同时,官方也再次强调:没有删库,没有跑路。据悉,此前有网友爆料称,此次网易云音乐故障是因为开发删库跑路”导致,引起不小轰动。站长网2024-08-20 03:21:030002苹果尴尬!iOS系统比安卓难上手实锤了:易用性相差58%
快科技6月23日,Android和iOS谁更易用?恐怕对于不同的人来说,答案会各不相同。不过,Greensmartphones试图借助搜索引擎来统计出一种确定性的答案。方法是汇总过去12个月iPhone和Android上执行一种常见任务如截图、录屏、拉黑、扫码等操作的搜索量,如果搜索量很大,那证明对于用户并不友好,或者说功能并不直观。结果发现,Android的易用性比iOS高出58%。站长网2023-06-23 23:42:490001猿辅导推出小猿学练机 正式入局1000亿智能硬件市场
猿辅导沉寂两年之后,在智能硬件领域重磅推出旗舰型产品——小猿学练机。该产品针对全国中小学生,注重学习和练习的结合,以及数字化学习的产品体系,配备封闭式系统和10.3寸类纸墨水屏,重定义了学习和练习的全新模式。这次动作也标志着猿辅导正式进入1000亿智能硬件市场。站长网2023-05-30 15:06:330000蚂蚁集团宣布换帅!韩歆毅接任CEO 井贤栋专注董事长工作
快科技12月8日讯,据国内媒体消息,今日蚂蚁集团董事长兼CEO井贤栋通过全员信宣布了一项重要的人事调整决定。蚂蚁集团总裁韩歆毅将从2025年3月1日起正式接任蚂蚁集团CEO一职,全面负责蚂蚁的各项业务及日常管理工作,并直接向井贤栋及董事会汇报。井贤栋在信中明确表示,未来他将更加专注于董事长的工作,并全力支持韩歆毅及其管理团队。0000