Hugging Face研究人员推语音识别模型Distil-Whisper 速度提高、参数减少
划重点:
⦁ Hugging Face研究人员利用伪标记创建了一个庞大的开源数据集,用于提炼Whisper模型的较小版本,称为Distil-Whisper。
⦁ Distil-Whisper在挑战性的声学条件下保持了Whisper模型的韧性,同时减轻了长篇音频中的错觉错误。
⦁ 自动语音识别(ASR)系统已达到人类水平的准确度,但由于预训练模型的不断增大,在资源受限的环境中面临挑战。
Hugging Face研究人员最近解决了在资源受限环境中部署大型预训练语音识别模型的问题。他们通过创建一个庞大的开源数据集,使用伪标记的方法,提炼出了Whisper模型的较小版本,称为Distil-Whisper。

图源备注:图片由AI生成,图片授权服务商Midjourney
Whisper语音识别变压器模型是在68万小时的嘈杂互联网语音数据上进行了预训练。它包括基于变压器的编码器和解码器组件,在零调优的情况下取得了竞争激烈的结果。而Distil-Whisper是通过使用伪标记进行知识提炼得到的紧凑版本。
Distil-Whisper在挑战性的声学条件下保持了Whisper模型的韧性,同时减轻了长篇音频中的错觉错误。这项研究引入了一种针对语音数据的大规模伪标记方法,这是一个尚未充分开发但颇具前景的知识提炼途径。
自动语音识别(ASR)系统已经达到了人类水平的准确度,但由于预训练模型的不断增大,在资源受限的环境中面临挑战。Whisper作为一个大型预训练ASR模型,在各种数据集上表现出色,但在低延迟部署方面可能更实用。而知识提炼在压缩自然语言处理变压器模型方面已经得到了有效应用,但在语音识别中的运用尚未得到充分探讨。
与原始 Whisper 模型相比,源自知识蒸馏的 Distil-Whisper 显着提高了速度并减少了参数,同时在具有挑战性的声学条件下保持了弹性。它的加速速度提高了5.8倍,参数减少了51%,在零样本场景下的分布外测试数据上实现了不到1% 的 WER。distil-medium.en 模型的 WER 稍高,但直接推理能力提高了6.8倍,模型压缩率提高了75%。Whisper 模型在长格式音频转录中容易出现幻觉错误,而 Distil-Whisper 可以减轻这些错误,同时保持有竞争力的 WER 性能。
Distil-Whisper 是通过知识蒸馏实现的 Whisper 模型的紧凑变体。这种创新方法在速度和参数减少方面产生了显着的好处,与原始 Whisper 模型相比,Distil-Whisper 速度更快,参数更少。尽管 WER 稍高,但 distil-medium.en 模型提供了更直接的推理和实质性的模型压缩。
项目网址:https://github.com/huggingface/distil-whisper
12306APP改版 新增折扣信息
近日,12306APP购票页面改版。与此前页面相比,新版在查询列车信息页面可直接选购座席等级,同时显示折扣信息。目前不少铁路执行浮动票价,在公布票价的基础上,实际票价有所浮动。据中国铁路微信公众号公布数据,三季度,全国铁路发送旅客11.5亿人次,较2019年同期增长11.6%。站长网2023-12-07 12:08:190000北京大学院长谈人工智能替代劳动力:不能一夜之间把所有人工作弄没 会引起公愤
7月27日消息,北京大学国家发展研究院院长黄益平今天公开谈论人工智能替代劳动力,其称不能一夜之间把所有人的工作都弄没了,这会引起公愤。黄益平指出,人工智能、数字技术可能给中国提供了一个当年日本不曾拥有的机会,或可以弥补、缓解劳动力减少造成的对经济的冲击。0000Canalys预测:2024年全球云服务支出将增长20% 加大对的AI投资
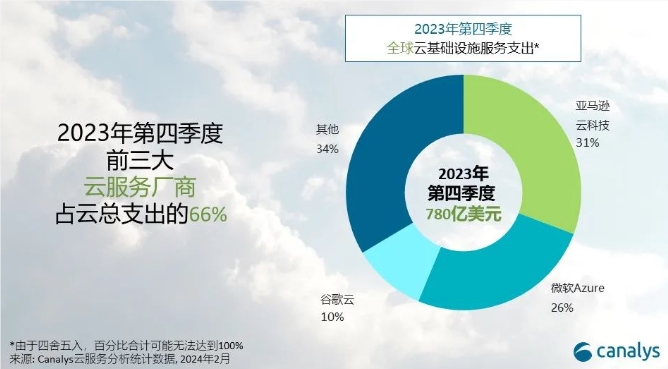
**划重点:**1.📈2023年第四季度全球云基础设施服务支出同比增长19%,达到781亿美元,较上年增加123亿美元。2.🌐云服务市场竞争激烈,前三名厂商为AWS、微软Azure和谷歌云,共占总支出的66%。3.🤖头部云厂商加大对生成式AI的投资,预计2024年全球云基础设施服务支出将增长20%。站长网2024-02-27 09:38:310001「AI选美大赛」能卷出多元审美吗?
自打AI可以生成图片后,“美女”就成了主题之一。“她们”初看惊艳,但时间久了,你就发现人类在用AI塑造女性形象时,审美也是十分单一。这些AI打造的女性形象个个皮肤完美、身材出众。当看客们审美疲劳时,社交网站Fanvue与世界AI创作者奖(WAICA)合作举办了一场名为“AI世界小姐”的选美比赛,支持任何人用AI生成工具生成女性形象的图片参赛。更有趣的是,大赛的评审团里也有两位AI生成的“网红”。站长网2024-04-30 15:54:590000阅文集团:推出大语言模型应用产品“作家助手妙笔版”
今日,阅文集团发布公告称,上半年实现收入32.8亿元,同比下降19.7%;归母净利润3.8亿元,同比增长64.8%。阅文集团表示,在2023年,我们看到了AI技术取得关键性突破的机遇。这是时代赐予的最好机会,为阅读文本带来了全新的可能性。以下是AI方面的核心观点:站长网2023-08-10 17:53:210000