Together AI发布RedPajama v2 用于大模型训练
站长网2023-11-06 10:31:311阅
要点:
1. Together AI发布了RedPajama v2,这是一个包含30万亿标记的开放数据集,用于训练大型语言模型。
2. 这个数据集的目的是提供高质量的数据,以支持开放式大型语言模型的成功发展。
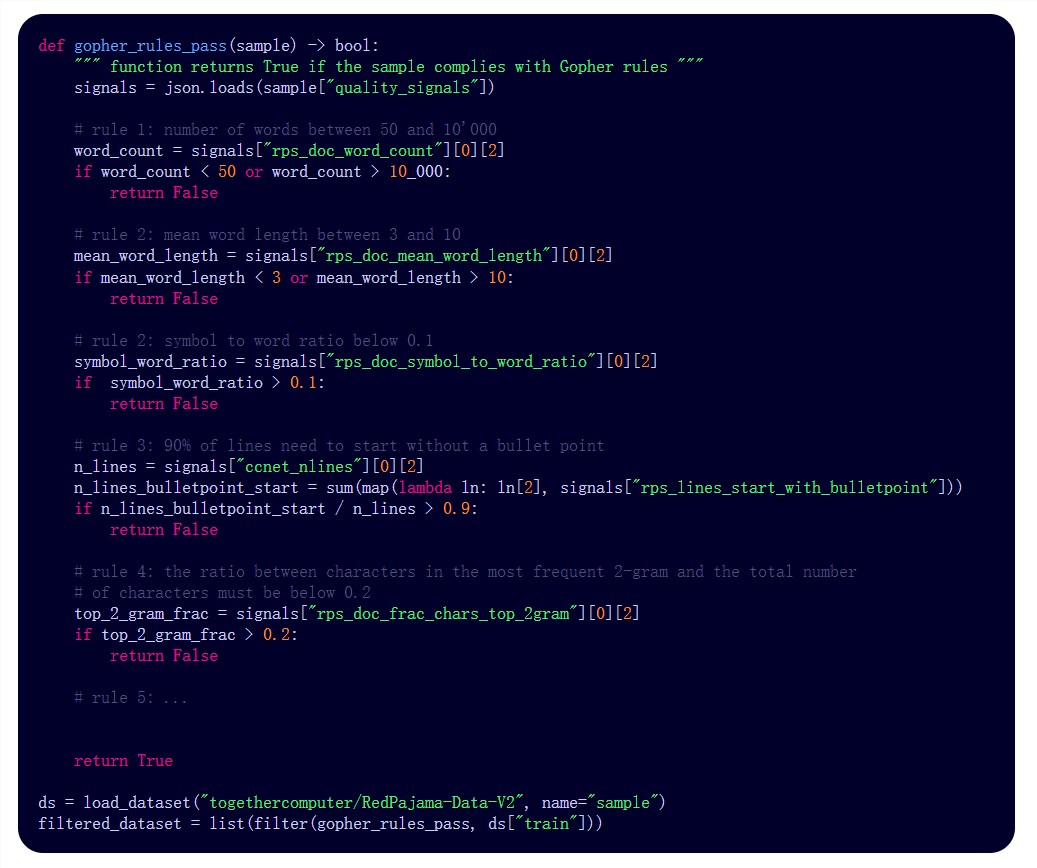
3. 数据集包含来自CommonCrawl和其他公开可用网络数据的原始文本数据,以及超过40个质量注释和去重集群。
Together AI发布了RedPajama v2,这是一个包含30万亿标记的数据集,旨在支持大型语言模型的研究和开发。高质量的数据对于这些模型的成功至关重要,但获取适当的数据集是一项繁琐的任务,需要大量时间、资源和金钱。
研究人员从CommonCrawl和其他公开可用的网络数据中提取了原始文本数据,其中包括40多个质量注释和去重集群。他们计划扩展这些注释,以包括与常用LLM基准的比较、主题建模和分类注释等内容,以促进更深入的研究。
地址:https://together.ai/blog/redpajama-data-v2
RedPajama v2的数据集还经过最小处理,以保持尽可能多的原始数据,并让模型构建者在后续处理中进行过滤和重新加权。这个数据集的覆盖面是前所未有的,涵盖了CommonCrawl的多个处理转储。
通过这一举措,研究人员为语言模型的开发和研究提供了更多的资源和工具,有助于改进模型的性能和应用领域。
这一数据集的发布对于AI研究和应用领域具有重要意义,为开发更强大的语言模型提供了支持和基础,有望推动AI领域的进一步发展。
0001
评论列表
共(0)条相关推荐
小米POCO F6死侍限量版发布 专为漫威爱好者设计!
POCOF6推出了一款限量版手机,吸引了漫威粉丝的注意。这款手机与普通POCOF6的规格相同,包括高通骁龙8sGen3移动平台、50MP主摄像头和5000mAh电池。该版本采用了深红色后面板和黑色边框,并在设计上模仿了死侍和金刚狼的形象。站长网2024-08-10 03:53:000000埃隆・马斯克因用太空垃圾充满轨道而受到抨击
最近,随着SpaceX公司推出超过6000颗Starlink互联网卫星,并计划未来增加到多达42000颗,关于这些卫星对地球环境影响的讨论愈发激烈。尽管这些卫星为全球互联网覆盖提供了便利,但它们在低地球轨道的存在也引发了不少担忧。图源备注:图片由AI生成,图片授权服务商Midjourney站长网2024-08-13 09:44:190000张大仙跳槽抖音,头部游戏主播还有新故事吗?
同一天,字节放弃游戏业务,而抖音迎来了头部游戏主播张大仙。只是,抖音不是不能播王者荣耀吗?似是早已预料到跳槽抖音会引起的疑惑,张大仙发了微博,关键信息是:将会继续播王者荣耀。还有消息称,下个月起,抖音将可以播王者荣耀和英雄联盟。腾讯和抖音围绕游戏直播版权的纷争,终于结束了?而随着头部游戏主播换平台、寻求新出路,他们还有新故事吗?张大仙官宣抖音开播“正式加入抖音直播啦,让兄弟们久等了。”站长网2023-11-29 16:35:040000Figma 推出 FigJam AI:让设计师免去枯燥的规划准备工作
站长之家(ChinaZ.com)11月8日消息:Figma以其产品设计应用程序而闻名,该公司今天宣布推出FigJamAI,这是一套用于其协作白板服务FigJam的新生成式AI工具套件,可为常见设计和规划项目创建即用型模板。FigJamAI的推出意在减少从零开始手动创建这些协作白板项目所需的准备时间,使设计师能够专注于更紧迫的任务。图片来自Figma站长网2023-11-08 09:06:510002阿里云推出针对Llama 3系列模型限时免费训练、部署、推理服务
最近,Meta公司发布了全新的Llama3系列,而阿里云魔搭社区迅速响应,将这一系列的四款模型全部上架。今天,阿里云百炼大模型服务平台更是宣布,将提供针对Llama3系列的限时免费训练、部署和推理服务,旨在帮助企业和开发者利用这一强大工具,快速构建属于自己的专属大模型。站长网2024-04-22 10:44:380001