研究人员推出压缩框架QMoE:可将1.6万亿参数模型高效压缩20倍
要点:
1. ISTA的研究人员提出了QMoE模型量化方法,可以将1.6万亿参数的SwitchTransformer压缩至160GB以下,每参数仅0.8位,实现了高达20倍的压缩率。
2. 这种压缩框架通过专门设计的GPU解码内核实现,能在一天内将庞大的模型压缩至适用于4张英伟达RTX A6000或8张英伟达RTX3090GPU的大小,而开销不到未压缩模型的5%。
3. QMoE采用了数据依赖的量化方法,实现了高效的压缩,即使在极低位宽下,仍能维持准确性,适用于大规模的混合专家架构模型。
最新研究来自ISTA的科学家提出了一种创新的模型量化方法,称为QMoE,可以将庞大的1.6万亿参数SwitchTransformer压缩到令人难以置信的160GB以下,每个参数仅占用0.8位。这一方法实现了高达20倍的压缩率,为解决大型模型的高昂成本和内存需求问题提供了新的解决方案。
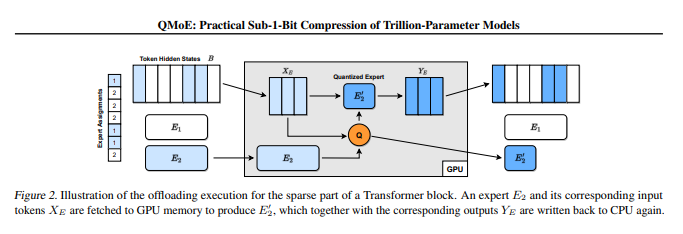
GPT-4等大型模型的发展使混合专家架构(MoE)成为研究的焦点。虽然MoE可以显著提高模型的准确性和训练速度,但由于庞大的参数数量,需要大量的显存才能运行这些模型。例如,1.6万亿参数的SwitchTransformer-c2048模型需要3.2TB的GPU显存。为解决这一问题,ISTA的研究人员提出了QMoE,这一框架利用专门设计的GPU解码内核,实现了高效的端到端压缩推理。
论文地址:https://arxiv.org/pdf/2310.16795.pdf
QMoE的独特之处在于采用了数据依赖的量化方法,允许在底层的位宽下实现高度压缩,同时仍能维持准确性。实验结果表明,即使在仅有2位或三元精度的情况下,与未压缩模型相比,精度的损失非常小。这一研究的成果为大规模混合专家架构模型的高效压缩和执行提供了新的可能性,将其适用于消费级GPU服务器,减少了内存开销,并降低了运行成本。
尤其令人印象深刻的是,QMoE的高效性,小型模型甚至可以在一小时内完成压缩,而大型模型如c2048也只需要不到一天的时间。虽然在执行速度方面与未压缩模型相比略有下降,但这一方法在大规模模型的压缩方面具有重要潜力。总的来说,QMoE为解决大型模型的内存需求问题提供了创新的解决方案,实现了高度的压缩和高效的执行。
然而,这项研究也存在一些局限性,因为目前公开可获得的大规模精确MoE模型数量有限,因此需要更多的研究和实验来进一步验证其适用性。这一创新性研究将有望为未来的深度学习和大型模型研究开辟新的方向。
大厂大模型,强在哪?
今年以来,中国科技公司掀起“百模大战”,大厂、创业公司都发布了自己的AI大模型。大模型越来越多,有闭源有开源,有通用也有垂直;企业做大模型的策略也不尽相同,有的坚持从底座做起,有的在开源架构之上抄近道。不过,虽然路径有差异,但有一点逐渐成为行业共识——大模型要落地,得从产业开始。B端的使用效果,成为评价一个大模型靠不靠谱的重要指标。站长网2023-07-26 14:05:170000改变创造力!10大终身免费的AI图像生成工具
在数字时代,视觉效果扮演着关键角色,既能吸引注意力,也能有效传达信息。随着人工智能图像生成工具的涌现,创意格局得以彻底改变,制作惊人的视觉效果比以往任何时候都更为容易。更妙的是,现在有许多免费的人工智能图像生成工具可供使用,无需花费太多金钱,创作者就能挥洒自己的艺术才华。在本文中,我们将深入探讨十大免费的人工智能图像生成工具,这些工具可以轻松帮助用户打造令人惊叹的视觉效果。站长网2023-08-31 17:57:400000AI芯片创企Taalas获5000万美元融资 定制专用芯片助力AI模型
据外媒SiliconANGLE报道,由Tenstorrent创始人LjubisaBajic领导的AI芯片创企Taalas已成功完成两轮共计5000万美元的融资,旨在为特定AI模型打造定制化专用芯片。图源备注:图片由AI生成,图片授权服务商Midjourney站长网2024-03-11 16:19:280000微信鸿蒙版要来了!曝华为腾讯接近达成协议:还将对微信免抽成
快科技6月19日消息,据媒体报道,华为与腾讯接近达成一项重要协议,该协议将允许微信在华为的鸿蒙(HarmonyOS)操作系统上运行。且华为不会对微信中的应用内交易收取任何费用,在结束了数月的谈判,双方即将签署正式协议。据悉,华为正考虑在鸿蒙应用商店收取20%佣金,并与游戏开发者讨论了约20%的分成比例,这一比例远低于苹果AppStore和谷歌Play商店的30%佣金。00007个月赚了3500万,山寨主播们杀疯了
起猛了,看见“疯狂小杨哥”在别的平台带货了。中分头、黑T恤、双胞胎兄弟,两人在直播间里疯狂甩头,时不时还来一句“我滴妈,这个价格还不冲,兄弟们”。不仔细辨别,真以为是疯狂小杨哥本尊。但定睛一看,这俩兄弟的账号叫“暴躁小鹏哥”。站长网2023-09-21 13:58:140000