AI智能超越人类终破解!李飞飞高徒新作破圈,5万个合成数据碾压人类示例,备咖啡动作超丝滑
AI巨佬Geoffrey Hinton称,「科技公司们正在未来18个月内,要使用比现在GPT-4多100倍的算力训练新模型」。
更大参数的模型,对算力需求巨大的同时,对数据也提出了更高的要求。
但是,更多的高质量数据该从何来?
英伟达高级科学家Jim Fan表示,「合成数据,将为我们饥渴的模型提供万亿个token」。

作为例证,英伟达与UT的研究人员在最新研究中,提出了一个MimicGen系统,能够大量生成机器人训练数据。

论文地址:https://arxiv.org/pdf/2310.17596.pdf
具体过程是,通过在模拟环境中,使用数字孪生技术复制真实世界中,人类的操作数据。
仅用了不到200个人类演示,MimicGen实现了在18个任务、多个模拟环境,甚至是现实世界中,自主生成5万个训练数据。
值得一提的是,这项研究所有数据集全部开源。

在Jim Fan看来,合成数据和模拟对AI发展非常重要,可以获得更多训练数据,维持学习算法的进步。它不仅适用于机器人领域,也会应用到其他AI领域。
我们正在迅速耗尽来自网络的高质量的真实token。从人工合成数据中获得人工智能,将是未来的发展方向。
恰恰,MimicGen展示了合成数据和模拟的力量,让「缩放法则」(scaling law)得以延续。

准备咖啡,操作如此丝滑
MimicGen实际表现如何,一起看些演示。
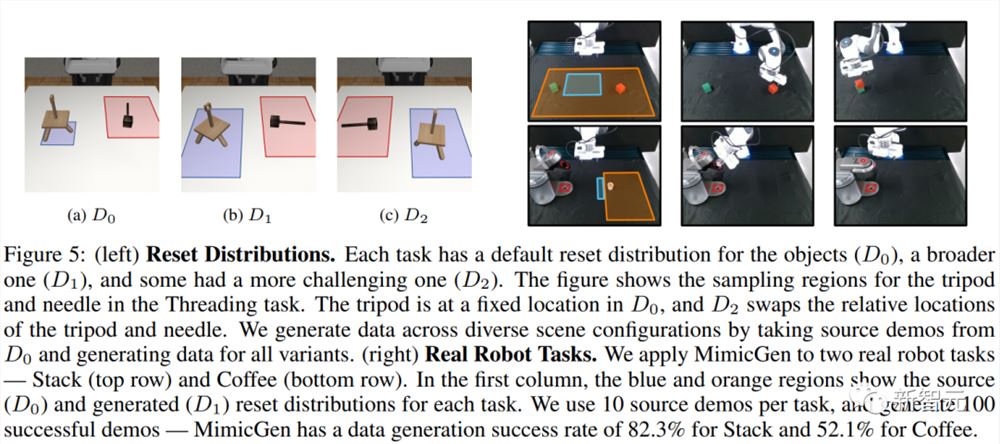
在下图的示例中,MimicGen仅从10个人类演示中,为3种不同的环境分布生成了1000个演示。

下面,将展示MimicGen在跨多个不同任务和环境分布中生成的几个数据集,比如积木堆叠、「穿针引线」、咖啡准备、拼装等等。

对于从未见过的杯子,MimicGen也能够将其收纳到抽屉里。

不同的机械臂,也能灵活自如地操作。

MimicGen在长期复杂的任务中的表现。

另外,MimicGen适用于需要毫米级精度的接触式任务。

准备咖啡的过程很丝滑。

而在其他生成示例中,合成数据都能完成高性能的展示,效果惊人!

MimicGen:生成式数据无限扩展
可以看到,从人类演示中进行模仿学习,已成为训练机器人执行各种操作行为的有效范例。
最为常见的方法是,人类通过不同的控制接口远程操作机器臂,生成执行各种任务的示例,然后用这些数据训练机器人自己完成这些任务。
然鹅,这种方法既费时,又费力。
另外,研究人员提出了另一个问题,在这些数据集中,实际上有多少数据包含了独特的操作技能?
在最新研究中,作者提出了一种新型系统MimicGen,通过对人类演示进行处理,自动生成不同场景下的大规模数据集,进而用于机器人的模仿学习。

具体来说:
- 人类远程操控机器人完成一个任务,生成非常高质量演示数据,但缓慢且昂贵。
- 在高保真的GPU加速的模拟环境中,创建机器人和场景的数字孪生。
- 在模拟环境中移动对象,替换新的物体,甚至改变机械臂,基本上是使用程序生成的方式扩充训练数据。
- 导出成功的场景,提供给神经网络进行训练。这样就获得了一个近乎无限的训练数据流。
总而言之,这项研究的主要贡献在于,展示了MimicGen可以在各种新的场景配置、对象实例和机械臂上生成高质量数据,来通过模仿学习训练出熟练的智能体,这些都是人类演示中没有的。
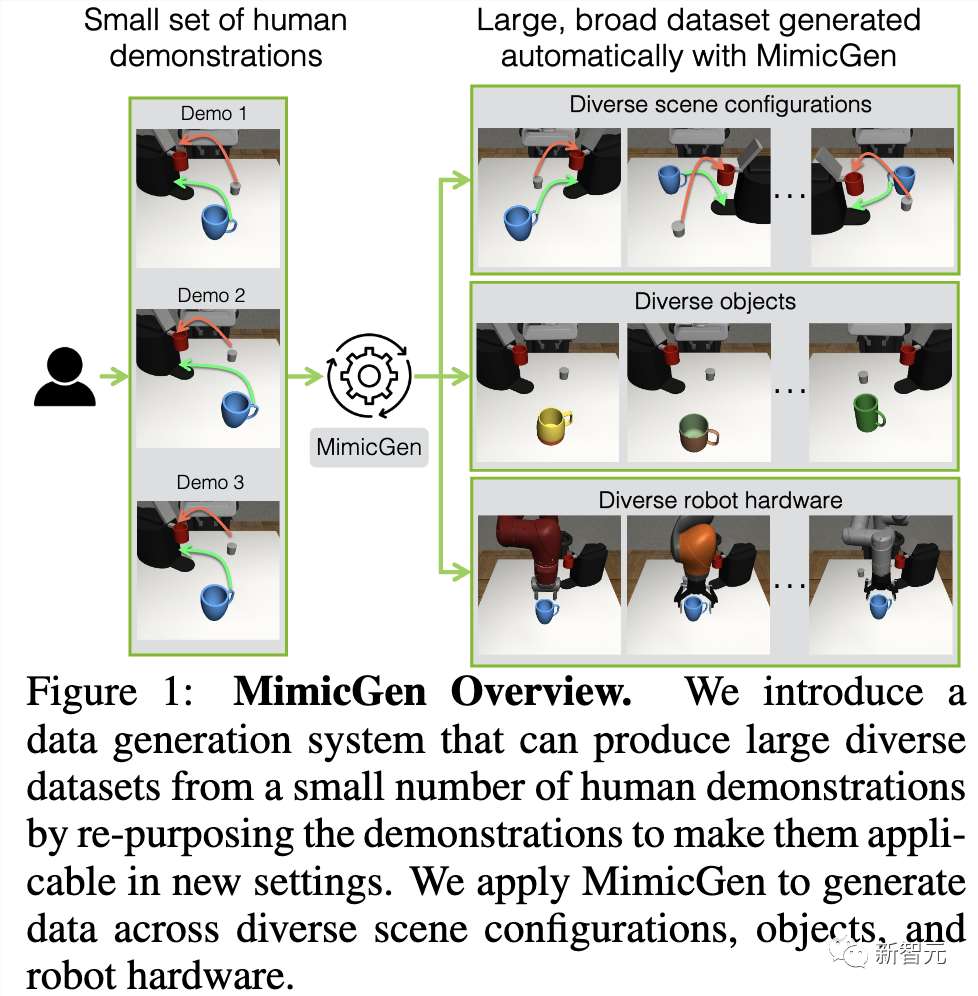
MimicGen广泛适用于需要不同操作技能的长序列任务和高精确度任务,比如抓放、组装等。
在2个模拟环境和1个物理机械臂上,只用大约200个人类演示就生成了5万个新的演示,涵盖18个任务。
与收集更多人类演示相比,这一方法更加优越。
使用MimicGen生成的合成数据(例如从10个人类演示生成200个演示)与200个人类演示训练出的智能体性能相当。
论文细节
问题设定
模仿学习
研究人员将每一个机器人操纵任务视为一个马尔可夫决策过程(MDP),并旨在学习一个将状态空间S映射到动作空间A的机器人操纵策略。
问题陈述和假设
研究人员的目标是使用一个源数据集D1,该数据集由在任务M上收集的一小组人类演示组成,并用它来生成一个大型的数据集D(用于相同任务或任务变体,其中初始状态分布 D、对象或机器人臂可能发生变化)。
生成新演示的步骤如下:
(1)从研究人员想要生成数据的任务中抽样一个起始状态,
(2)从D1中选择并适应一个演示以生成一个新的机器人轨迹τ',
(3)机器人在当前场景中执行轨迹τ',如果任务成功完成,则将状态和动作的序列添加到生成的数据集D中(具体的每一步请参见方法)。接下来,研究人员概述系统利用的一些假设。
假设1:增量末端执行器位姿( delta end effector Pose)动作空间。动作空间(action space)A包括用于末端执行器控制器和夹持器开/关命令的增量位姿命令。
这使研究人员能够将演示中的动作视为末端执行器控制器的一系列目标位姿。
假设2:任务由已知的对象中心子任务序列组成。设 O = {o₁, ..., oₖ} 为任务 M 中的对象集合。
研究人员假设任务由一系列对象中心子任务
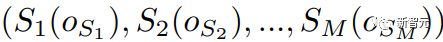
组成,其中每个子任务
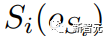
相对于单一对象的坐标系

。研究人员假设这个序列是已知的。
假设3:在数据收集期间,每个子任务开始时都可以观察到对象的姿态。研究人员假设在每个子任务
的数据收集期间(但在策略部署期间则不是),研究人员可以观察到相关对象 oₛᵢ 的姿态。
研究方法
研究人员展示了如何使用一个小型的人类演示源数据集来生成新的演示(下图2)。
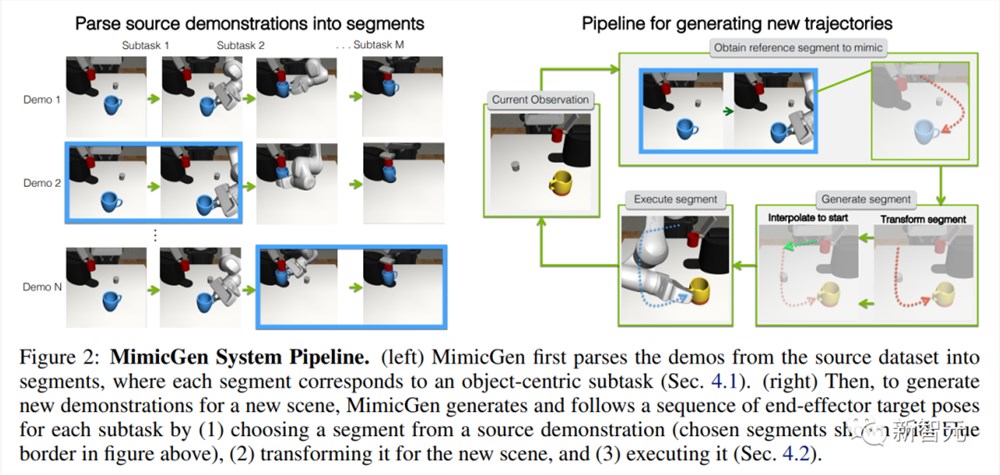
MimicGen首先将源数据集解析为多个段(segment) — 每个段对应于任务中的一个对象中心子任务。
然后,为了在新场景中生成一个演示,MimicGen会为每一个子任务生成并执行一个轨迹(末端执行器控制位姿的序列,sequence of end-effector control poses)。
方法是从源示例中选择一个参考段,根据新场景中对象的位姿进行转换,然后使用末端执行器控制器执行目标位姿的序列。
将源数据集解析为对象中心的段
每个任务都由一系列对象中心的子任务组成 — 研究人员希望将源数据集中的每个轨迹τ解析为多个段 {τᵢ}ₘⁱ=₁,其中每个段τᵢ对应于一个子任务Sᵢ(oₛᵢ)。
为新场景转换源数据段
为了在新场景中生成一个任务演示,MimicGen会为任务中的每一个对象中心子任务生成并执行一个段。如上图2(右)所示,这包括每个子任务的三个关键步骤:
(1)在源数据集中选择一个参考子任务段,
(2)为新的上下文转换子任务段,
(3)在场景中执行该段。
选择一个参考段:MimicGen将源数据集解析为与每个子任务相对应的段
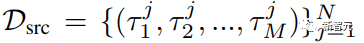
在每个子任务 Sᵢ(oₛᵢ) 开始时,MimicGen从集合
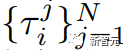
中选择一个相应的段。这些段可以随机选择或使用相关对象的位姿。
转换源子任务段:研究人员可以将选定的源子任务段 τᵢ 视为末端执行器控制器的目标位姿序列。
执行新段(Executing the new segment)
最后,MimicGen通过在每个时间步取目标位姿,将其转换为增量位姿动作,与源段中相应的抓取器打开/关闭动作配对,并执行新动作来执行新段τ′ᵢ。
以上步骤重复每个子任务,直到执行了最后一个段。
然而,这个过程可能是不完美的——由于控制和手臂运动学问题导致的小轨迹偏差可能导致任务失败。
因此,MimicGen在执行所有段后检查任务成功与否,并仅保留成功的演示。研究人员将成功生成轨迹的数量与总尝试次数之间的比率称为数据生成率。
这个流程只依赖于对象框架和机器人控制器框架——这使得数据生成可以在具有不同初始状态分布、对象(假设它们有规范框架定义)和机器人手臂(假设它们共享末端执行器控制框架的约定)的任务之间进行。
在研究人员的实验中,研究人员为每个机器人操作任务设计了任务变体,其中研究人员改变初始状态分布(D)、任务中的一个对象(O)或机器人手臂(R),并表明 MimicGen 支持这些变体之间的数据收集和模仿学习。
175个人类演示,生成5万个数据集
研究人员将MimicGen应用于多种不同的任务(见下图3)和任务变体,以展示它如何为模仿学习在包括拾取-放置、富有接触性的交互以及关节动作在内的多样化的操控行为生成有用的数据。

实验和结果
研究人员进行了实验,目的是(1)突出显示MimicGen能够生成数据的多样情境;(2)展示MimicGen与收集额外人类示范相比在努力和数据下游政策性能方面都有优势;(3)提供系统不同方面的洞见;(4)证明MimicGen能在真实世界的机器人手臂上工作。
MimicGen的应用
研究人员概述了几个展示MimicGen有用属性的应用场景。
MimicGen数据大幅提升了代理在源任务上的性能。MimicGen一个直接的应用就是收集某个感兴趣任务的小型数据集,然后为该任务生成更多数据。与在小型源数据集上训练的代理相比,使用MimicGen生成的D0数据集训练的代理表现有显著提升。
MimicGen数据能在广泛的初始状态分布下生成高性能的代理。如下图4所示,使用在广泛的初始状态分布(D1、D2)上生成的数据集训练的代理具有很高的性能。
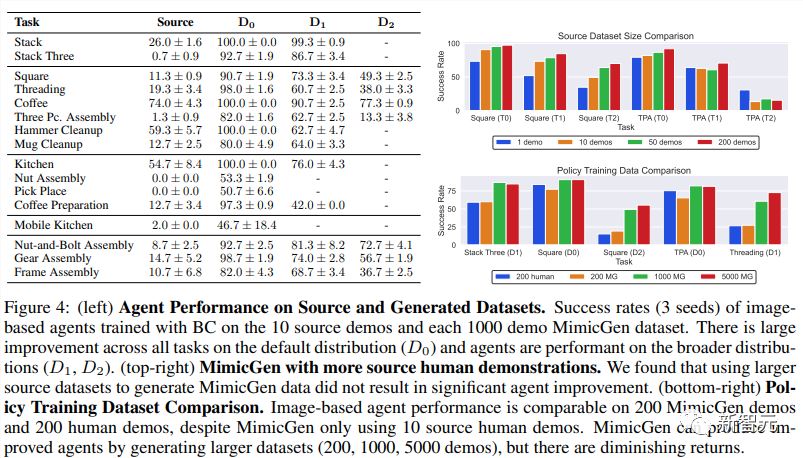
MimicGen能为不同对象生成数据。例如,在「Mug Cleanup(马克杯收纳)」任务的源数据集中只有一个马克杯,但研究人员用MimicGen为一个未见过的马克杯(O1)和一组12个马克杯(O2)生成了演示。
MimicGen可以为多种机器人硬件生成数据。研究人员将MimicGen应用于使用Panda手臂的Square和Threading源数据集,并为Sawyer、IIWA和UR5e生成了跨D0和D1重置分布变体的数据集。
将MimicGen应用于移动操纵。在「Mobile Kitchen(移动厨房)」任务中,MimicGen使得成功率从2.0%提升到46.7%。
MimicGen是模拟器不可知的。研究人员证明MimicGen不仅限于一个模拟框架,通过将其应用于在Isaac Gym之上构建的Factory模拟框架中需要毫米级精度的高精度任务。
MimicGen和人类数据对比
MimicGen可以利用少量人类示例生成大规模数据集:
在18个任务中,只用175个人类示例就生成了超过5万个示例。在Square任务中,只用10人类示例就生成了1000个示例,覆盖不同场景配置。
而且MimicGen生成的数据集可以训练出高性能策略,甚至比人类示例的效果好很多:
在Square任务中,从10人类示例的数据集成功率11.3%,从生成数据集成功率可达90.7%。
在复杂的Coffee Preparation任务中,成功率从12.7%提升到97.3%,在高精度装配任务Gear Assembly中,成功率从14.7%提升到98.7%。
MimicGen生成的数据集与人类数据集性能相当:
在Square任务中,200人类示例成功率为12%,200个生成示例成功率为11.3%,在Three Piece Assembly任务中,200人类示例成功率为14%,200生成示例成功率为13.3%。
在机械臂上的表现上,MimicGen生成的数据的Stack任务从源域0%的成功率提升到了36%,Coffee任务,成功率从源域的0%成功率到目标域14%成功功率。
网友热议
合成数据将主导大部分生成式人工智能行动!

终有一天,人类标注和演示成为过去。

有网友惊呼,这与AGI大差不差了,人类灵巧程度的机器人也会突然能力大爆发。

这正是我之前思考的AI智能超越人类智能,大概率只是时间问题:因为真实世界有限的数据并不是限制,数据可以通过AI合成,之后再投入到模型训练中:Artificial synthetic data ⇒ Training AI ⇒ AI smarter ⇒ Generating more synthetic data ⇒ more into trianing AI model; Feedback Loop已建立。

有网友表示,「这可以用来生成自动驾驶训练集吗?这样汽车公司就不必仅仅依靠真实世界的数据来训练他们的模型了?」

突发!GPT-4.5泄露传闻:是圣诞的礼物,还是传言的迷雾?
刚刚,一颗潜在的AI圈震撼弹——OpenAI的GPT-4.5版本——似乎无声地滑入公众的视线。这份所谓的“泄露”信息,以及它预示的技术突破究竟意味着什么,目前仍是一个谜。背景信息:GPT的演变0000GPT-4调教指令揭秘,OpenAI又「Open」了一回!网友在线追问GPT-5
【新智元导读】GPT-4越来越懂事了,这背后有着非常巧妙的「调教」策略。OpenAI最新发布的「模型规范」,给LLM列出了条条框框,即正确的行为方式。没想到,评论区一大片网友催更GPT-5。这周既没有GPT-5,也没有搜索引擎的发布,不过,OpenAI也是没闲着。这次,OpenAI可是又open了一回。先是揭秘了,大家一直揪着不放的「数据」问题。站长网2024-05-14 10:37:100000好用不贵的五款手机,买来使用五年没有问题
对于大部分用户来说,其实使用手机的需求都比较简单,完全没必要购买四五千的旗舰产品,就算是一款2000元左右的机型,只要你对拍照没有过高的要求,买来舒服使用五年也是没有任何问题的。客观地说,如今的中端手机和旗舰手机最大的差距还是拍照,性能、续航、充电甚至屏幕层面都没有特别大的差距,如果你不是拍照爱好者,那2000左右的手机就足够好用了。站长网2023-05-23 20:18:420000微软开发新型大模型压缩方法SliceGPT
SliceGPT是微软开发的一种新型的大语言模型压缩方法。通过SLICEGPT,可以在保持99%,99%,和90%零样本任务性能的同时,将LLAMA2-70B、OPT66B和Phi-2模型分别去除高达25%的模型参数(包括嵌入)。站长网2024-01-29 17:21:360000OpenAI正在开发SearchGPT 将成Perplexity强有力的竞争对手
OpenAI正在积极开发Perplexity的竞争对手——Sonic-SNC(SearchGPT),目前该工具已经进入评估阶段,并新增了多项实用功能。域名:https://search.chatgpt.comSearchGPT的新增功能包括:图像搜索:用户现在可以进行图像搜索,增强了信息检索的能力。站长网2024-04-27 17:40:470004