GPT-4不知道自己错了! LLM新缺陷曝光,自我纠正成功率仅1%,LeCun马库斯惊呼越改越错
【新智元导读】GPT-4根本不知道自己犯错?最新研究发现,LLM在推理任务中,自我纠正后根本无法挽救性能变差,引AI大佬LeCun马库斯围观。
大模型又被爆出重大缺陷,引得LeCun和马库斯两位大佬同时转发关注!
在推理实验中,声称可以提高准确性的模型自我纠正,把正确率从16%「提高」到了1%!
简单来说,就是LLM在推理任务中,无法通过自我纠正的形式来改进输出,除非LLM在自我纠正的过程中已经知道了正确答案。
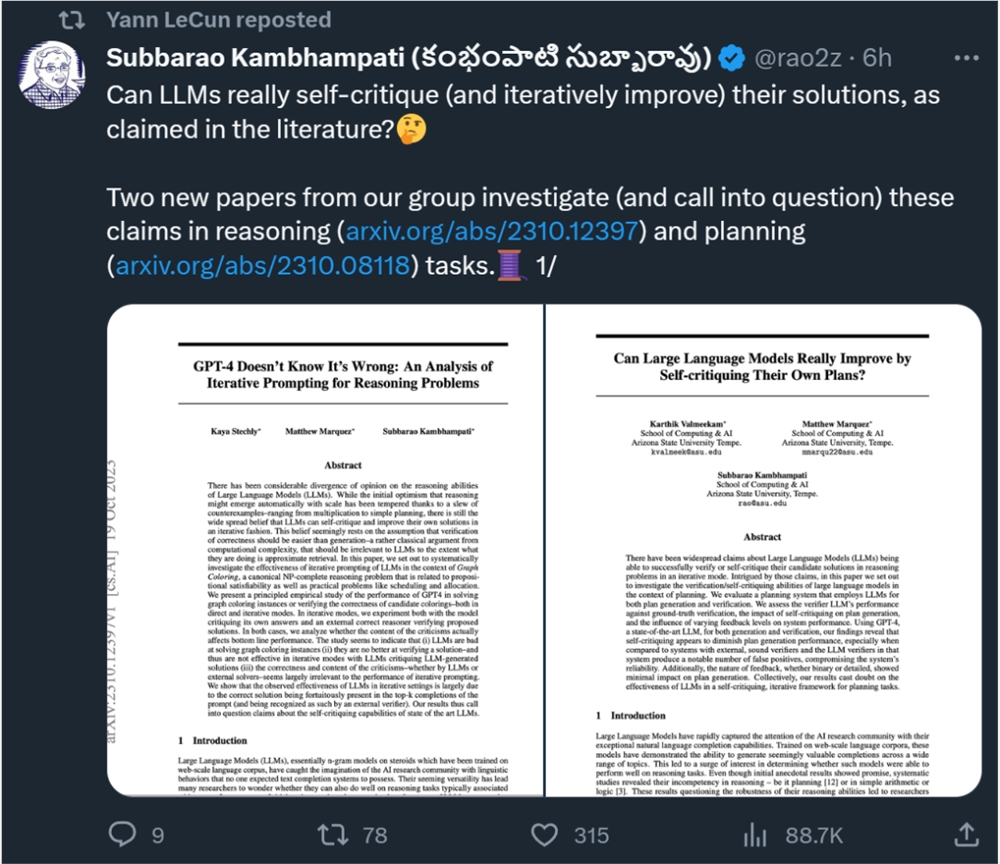
由ASU研究人员发表的两篇论文,驳斥了之前很多研究提出的方法「自我纠正」——让大模型对自己的输出的结果进行自我纠正,就能提高模型的输出质量。

论文地址:https://arxiv.org/abs/2310.12397

论文地址:https://arxiv.org/abs/2310.08118
论文的共同作者Subbarao Kambhampati教授,一直致力于AI推理能力的相关研究,9月份就发表过一篇论文,甚至全盘否定了GPT-4的推理和规划能力。

论文地址:https://arxiv.org/pdf/2206.10498.pdf
而除了这位教授之外,最近DeepMind和UIUC大学的研究者,也针对LLM在推理任务中的「自我纠正」的能力提出了质疑。
这篇论文甚至呼吁,所有做相关研究的学者,请严肃对待你们的研究,不要把正确答案告诉大模型之后再让它进行所谓的「自我纠正」。
因为如果模型不知道正确答案的话,模型「自我纠正」之后输出质量反而会下降。

https://arxiv.org/abs/2310.01798
接下来,就具体来看看这两篇最新论文。
GPT-4「自我纠正」,输出结果反而更差
第一篇论文针对GPT-4进行研究,让GPT-4对图形着色问题提供解决方案,然后让GPT-4对于自己提出方案进行「自我纠正」。
同时,作者再引入一个外部的评估系统对GPT-4的直接输出,和经过了「自我纠正」循环之后的输出进行评价。

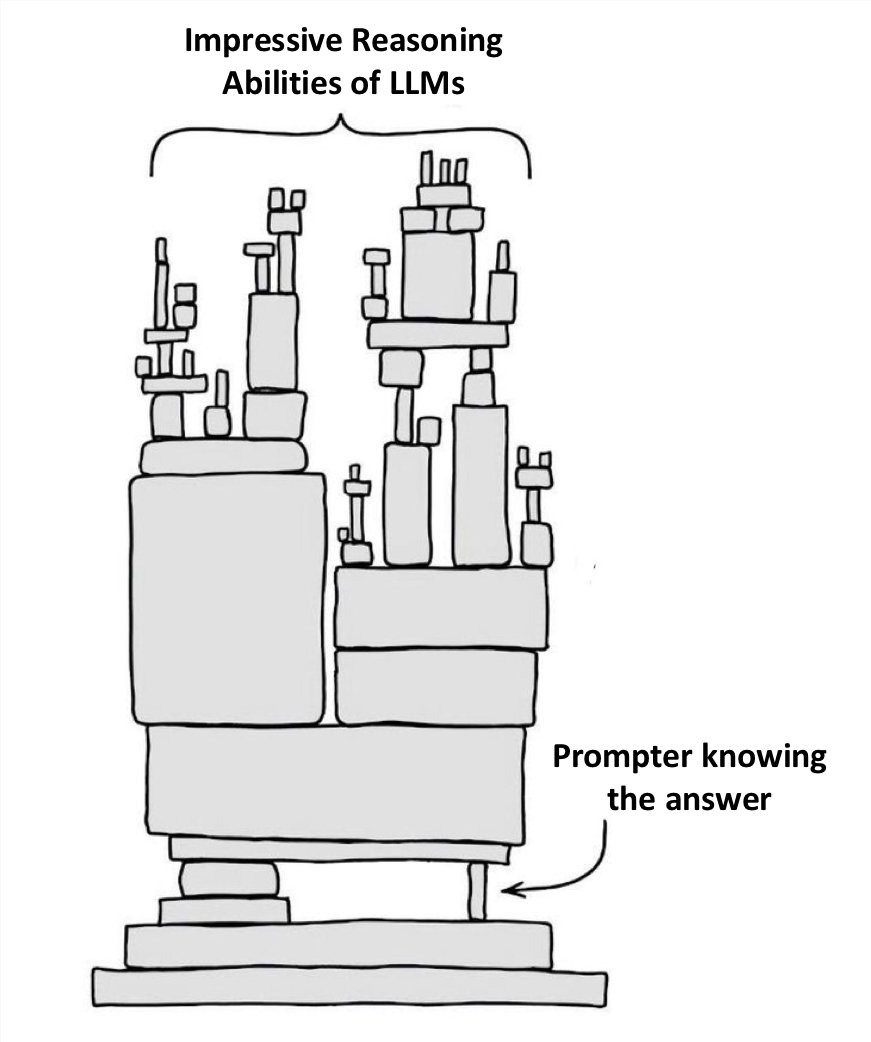
实验结果显示,GPT-4在猜测颜色方面的准确率还不到20%,这个数值似乎并不让人意外。
但令人惊讶的是,「自我纠正」模式下的准确性却大幅下降(下图第二根柱状条 )——与所有自我纠正本意完全背道而驰!

作者认为,这种看似反直觉的情况可以这么解释:GPT-4在验证正确答案的表现也很糟糕!
因为即使当GPT-4偶然猜到正确颜色时,它的「自我纠正」会使它觉得正确答案是有问题的,然后就把正确答案给替换掉了。

通过进一步研究后还发现:如果外部验证器给GPT-4猜测出的颜色提供了可以被证实的正确答案,GPT-4确实会改进它的解决方案。
在这种情况下,经过「自我纠正」产生的提示词,确实可以提高输出结果的质量(上图的第3-5根柱状图 )
总结来看,就是对于「着色问题」任务,GPT-4独立的「自我纠正」反而会损害输出的性能,因为GPT-4没法验证答案是否正确。
但是如果能提供外部的正确验证过程,GPT-4生成的「自我纠正」确实能提升性能。
而另一篇论文,从规划任务的角度来研究了大语言模型「自我纠正」的能力,研究结果也和上一篇论文类似。
而且,研究人员发现,真正能提高输出准确性的不是LLM的「自我纠正」,而是外部独立验证器的反馈。
归根结底,还是在于LLM没有办法进行独立的验证,必须依赖外部的验证器给出的「正确答案」,才能有效地进行「自我纠正」。
「着色问题」表现不佳,LLM无法独立验证正确答案
研究设计框架
「着色问题」是非常经典的推理问题,即使难度不大,答案也足够多样性,而且答案的正确性很容易进行验证。
多样性的结果使得LLM的训练数据很难覆盖全,尽量避免了LLM的训练数据被污染的可能。
这些原因使得「着色问题」很适合用来研究LLM的推理能力,也很方便用来研究LLM在推理中「自我纠正」的能力。
研究人员构建了自己的数据集,使用GrinPy2来处理常见的图操作。每个图都是使用Erdos-Rényi方法( ˝p =0.4)构造的。
一旦找到正确的答案,它就会被编译成标准的DIMACS格式,并附加上一个包含其预计算的色数(chromatic number)的注释。
对于接下来的实验,研究人员生成了100个实例,每个实例平均有24条边,分布在从10到17的节点数范围内——这一分布是因为经验显示,它是一个表现足够多变的范围。
研究人员使用的图例如下图1所示,这个流程包括LLM的第一次回复、该回复的返回提示(backprompt)以及最终正确的图色方案。
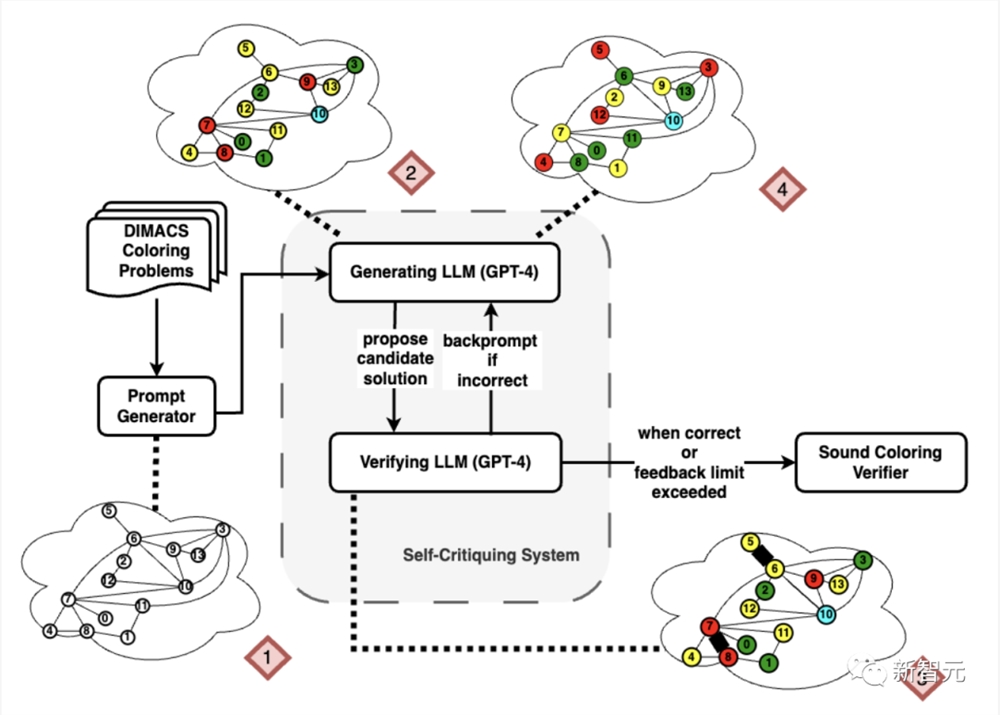
迭代返回提示(Iterative Backprompting)的架构
提示生成器(Prompt Generator):
这个提示词生成器会选取一个DIMACS实例,并将每条边翻译成一个句子,然后将整体包裹在一组通用指令中,从而构造出一个自然语言提示词。
研究人员有意缩小不同实例提示之间的差异,以减少研究人员向LLM泄露的问题特定信息。各种类型提示的示例可以在附录中找到。
大型语言模型:
通过OpenAI API来调用GPT-4,这是当前最先进的模型。
研究人员提供一个系统角色:「你是一个解决各种CSP(约束满足问题)的约束满足求解器」。
返回提示词生成(Backprompt Generation)
在验证模式下,LLM收到一种不同类型的提示。
除了标准指令外,它只包含图的描述和建议的着色方案。它的任务是验证正确性、最优性以及每个顶点是否都已经被涂上了一个颜色。
如果生成的回复中有一组边是矛盾的,那着色方案就是错误的。
为了比较每个点,研究人员还构建了一个能够列出每一条矛盾边的验证器。
由于LLM的响应也是自然语言形式的,研究人员首先将它们翻译成便于分析的格式。为了使这个过程更加一致,研究人员设计了最初的提示,以描述一个模型需要遵循的精确输出格式。然后,该响应会被评估其正确性。
为了判断LLM验证结果,研究人员会检查它们在找出建议的着色方案中的错误方面表现如何。
直观地说,这些应该很容易识别:如果组成一个边的两个顶点共享一个颜色,立即返回该边。从算法角度看,只需要检测所有的边并比较每个顶点的颜色与其连接点的颜色即可。
验证
为了更深入了解LLM的验证能力,研究人员研究了它们在找出提出的着色方案中的错误方面的表现。
直观来说,这些错误应该很容易识别:如果组成一个边的两个顶点共享一个颜色,则立即返回该边。从算法角度来看,所有需要做的就是遍历所有边,并将每个顶点的颜色与其对应顶点的颜色进行比较。
研究人员使用相同的分析流程,但构建了一个研究人员称为color_verification的新域。LLM被引导去检查着色的正确性、最优性以及是否每个顶点都已经被赋予了一个颜色。
如果着色是不正确的,它被指示列出着色中的错误,即如果两个连接的节点共享一种颜色,就返回该边以表示该错误。没有给出返回提示(backprompts)。
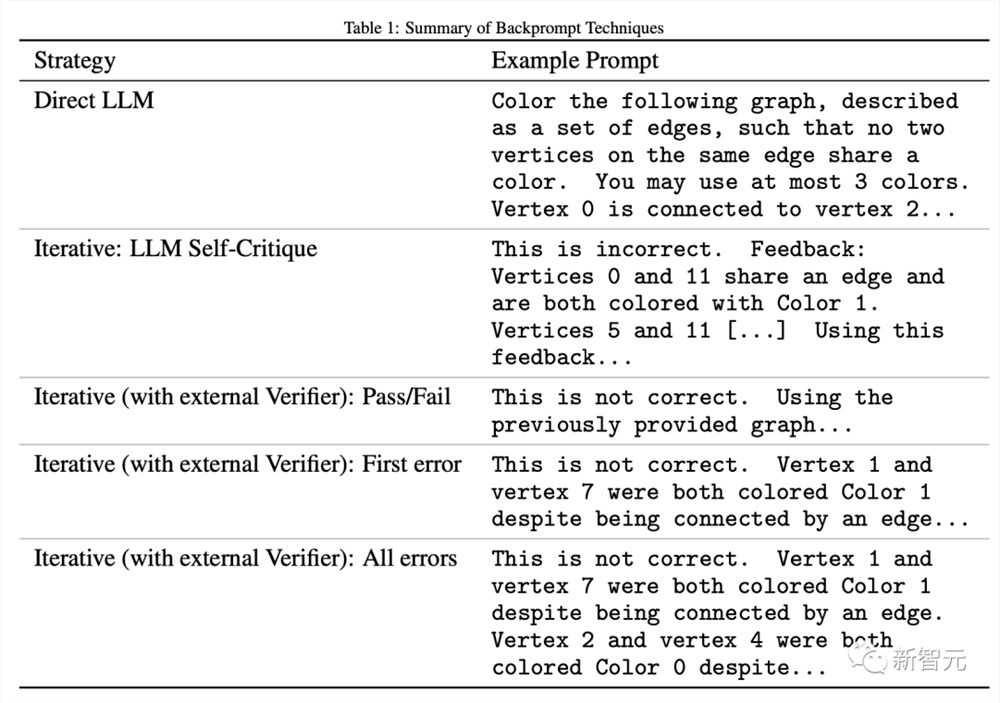
研究人员使用之前相同的图实例,但生成了四种用于测试模型的着色方案:
正确(Correct):通过迭代的、随机的贪婪算法生成的没有错误的最优着色方案(使用预先计算的色数以确保最优性)。
缺失(Ablated):将先前一组着色方案中的一个随机节点改变为其邻居的颜色。
非最优(Non-optimal):在正确的集合中,随机选择一个颜色部分重新着色为一个新的色调。
随机(Random):完全随机分配的颜色,不同颜色的数量等于图的色数。
LLM:从先前实验中LLM生成的输出中随机选取的着色方案。
结论

对LLM进行提示、评估答案,并在没有任何返回提示(backprompts)的情况下就会进入下一个实例,得到的基线分数为16%。
当研究人员运行相同的实例,但这次使用由相同的语言模型充当验证者生成的反馈进行返回提示时,性能急剧下降——100个实例中只有一个得到了正确的回答。
与外部合格的验证器进行返回提示的结果起初看似更有效果。
正确回答的实例数量接近40%,但如果这意味着GPT-4在听取、改进,并根据反馈进行推理,那么研究人员期望更准确的返回提示会带来更好的结果。
然而,在这个域中,原始分数(见上图2)并没有证明这一点。
LLM的验证能力
研究人员测试了GPT-4在相同实例上验证图着色方案的能力,为每种实例生成了五种不同类型的着色方案。
明显的结果是,与上面的LLM自我纠正结果完全一致:模型几乎不愿将任何答案标记为正确。在100个最优着色方案中,它只同意其中2个是正确的。
整个500个着色方案的集合,其中118个是正确的,它只声称其中30个是正确的。在这30个中,其实只有5次是正确的。
总体而言,这一模式保持不变。在不到10%的案例中,LLM给出了「正确」、「非最优」或「缺少赋值」的反应。在这些情况中,行为看似有些随机。
在大约四分之一的实例中,它用「这是不正确的」验证作出回应,而解释与现实相符,而且它只通过指明不超过一个边来实现这一点,从而最小化了错误陈述某事的机会。
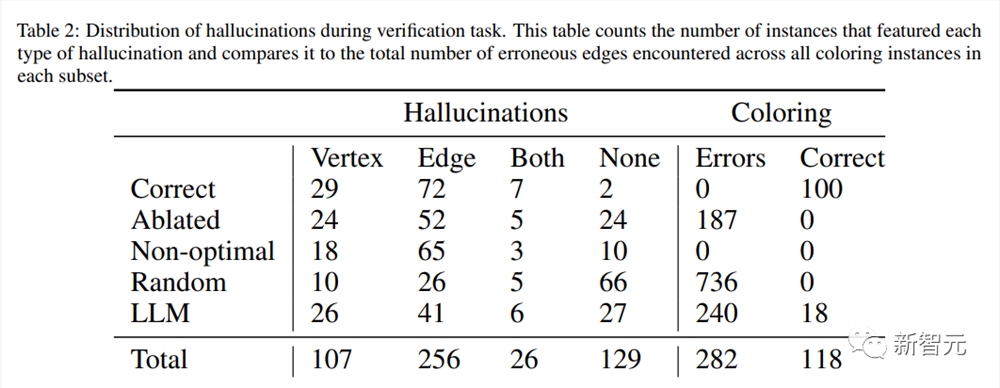
结果如上表2所示。请注意,当域的错误率增加时,幻觉比例下降。也就是说,当有更多的不正确的边时,模型更有可能指出其中出错的情况。
LLM自我批评,性能不增反减
在12日提交的论文中,作者同样得出了与上面一致的结论。
无论是规划,还是简单的算术或逻辑,当前最先进的大模型GPT-4也无法完全胜任。
许多研究人员对其进行了许多的探索和改进,其中就包括让LLM学会自我迭代、自我验证等策略来提升性能。
由此,业界人们乐观地认为,大模型还有救!
然而,经典意义上的推理任务复杂性与大模型无关,因为LLM是采用近似检索而非精确推理的模型。
在12日提交arXiv的论文中,ASU研者系统地评估和分析LLM在规划任务中的自我批评,以及迭代优化的能力。
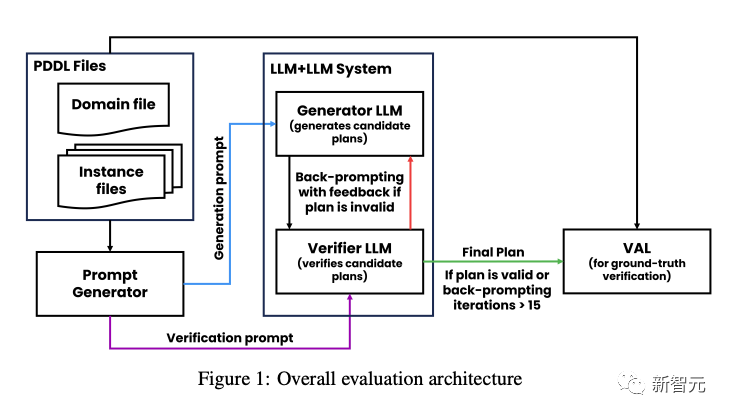
研究中,作者提出了一个包含生成器LLM和验证器LLM的规划系统。
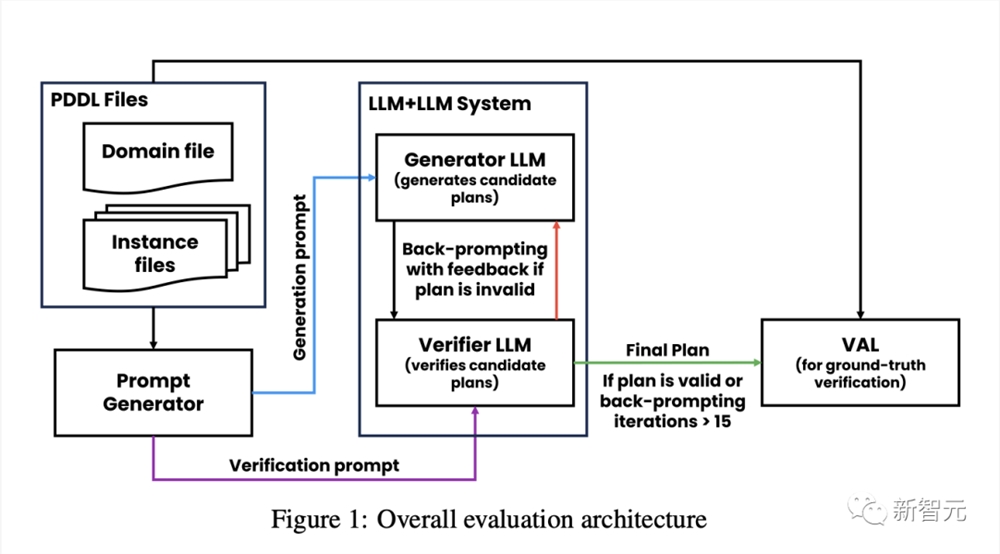
其中,GPT-4生成器负责生成候选计划,GPT-4验证器负责验证计划的正确性并提供反馈。
然后,研究人员在Blocksworld规划领域上进行了实验,并对以下方面进行了实证评估:
- 自我批评对整个LLM LLM系统的计划生成性能的影响
- 验证器LLM相对于地面真值验证的性能;
- 在批评LLM生成时,同反馈级别对整体系统性能的影响。
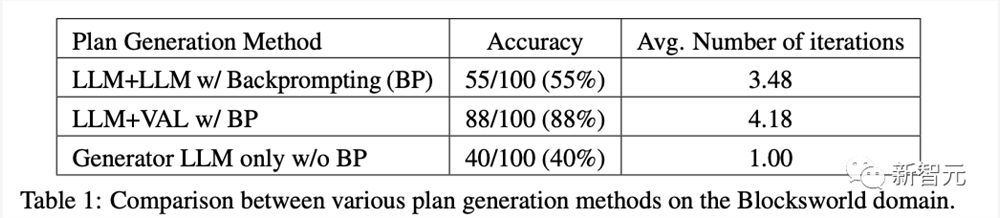
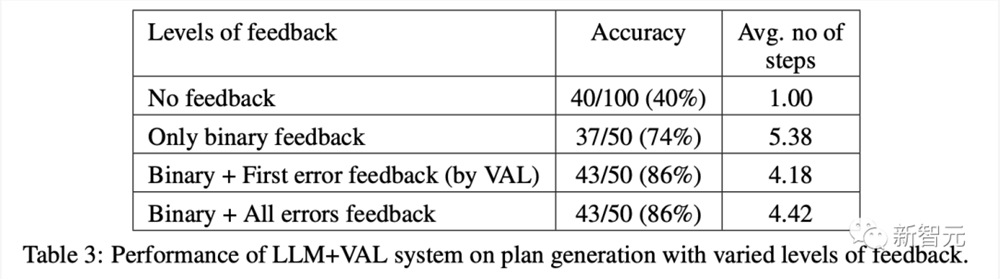
结果表明,与使用外部可靠的验证器相比,自我批评会降低LLM规划生成性能。

性能下降可以直接归因于验证器LLM的糟糕结果,验证器LLM产生了大量的假阳性,这可能严重损害系统的可靠性。
验证器LLM的二元分类准确率仅为61%,存在大量的假阳性(将错误规划判断为正确)。

另外,根据反馈的详细程度对比,发现其对规划生成性能影响不大。
总的来说,这项研究的系统调查提供了初步证据,对于LLM作为迭代、自我批评框架内规划任务验证者的有效性提出质疑。
作者介绍
Subbarao Kambhampati
Subbarao Kambhampati是亚利桑那州立大学计算机科学教授。Kambhampati研究规划和决策中的基本问题,特别是受人类感知人工智能系统挑战的推动。
不好用不收钱,这家AI公司破天荒按结果收费,要卷死同行?
一种新的人工智能商业模式。近两天,关于OpenAI提高付费版模型价格的消息满天飞,有消息称订阅价格最高可达每月2000美元。尽管最终价格尚未确定,但现在个人每月20美元、企业每人每月25美元的订阅费也让大家苦不堪言。或许,这一个月你用了没几次,又或许订阅的服务根本没能解决问题,用户还是需要支付全部的费用。而这种付费模式,也是当前很多企业都在采用的。站长网2024-09-10 16:26:130001淘宝修改销量显示规则 由30天月销变为近365天已售件数
淘宝最近修改了销量显示规则,将原来的30天月销改为显示近365天累计已销售件数,并排除了不诚信经营和售中退款等销量。这一改变对于用户、商家和平台都是利好。首先,这个规则鼓励商家在平台上实现长久稳健经营,打造长远品牌。其次,对于新品和新商家,淘宝提供了更多机会,促进创新和原创保护。最后,这一规则激发了中小商家的活力,帮助他们获得持续激励。站长网2023-08-19 15:33:110000“网红带货鼻祖”回归,6年败完370亿后改拍短剧
比李佳琦资历更深的“美妆一哥”,低调三年后,再一次进入公众视野。如果你是“80后”、“90后”,对他一定不会感到陌生——他是最早把自己包装成网红的企业家,巅峰期的微博粉丝量比罗永浩更多;他和李佳琦一样擅长卖化妆品,早在十年前,就已身家过亿;他曾本人出镜,请来顶流韩庚,一句“我为自己代言”,开启了一个新的时代。近日,聚美优品创始人陈欧被曝出,正在积极筹备短剧平台并推进版权贸易。站长网2023-11-17 14:01:520001Vision Pro技术下放?苹果展示新技术 用眼睛就能控制iPad
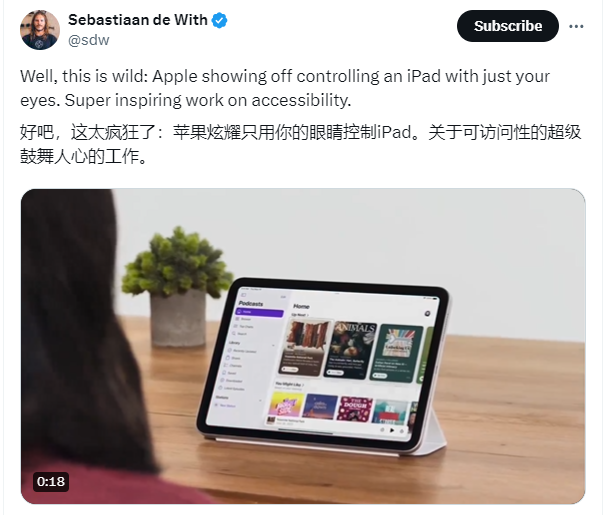
苹果公司即将在6月11日举办的WWDC开发者大会上发布一系列全新功能,这些功能旨在提升用户体验,特别是为残疾人群提供更多的辅助支持。以下是苹果预告的四大新功能:眼动追踪:这项功能将允许身体障碍用户通过眼睛控制iPhone和iPad。用户通过前置镜头进行设置后,设备会使用机器学习技术追踪用户的眼动,从而实现对设备的控制。所有眼动追踪数据都将安全地保存在设备上,不会与苹果公司共享。站长网2024-05-16 11:59:430000马斯克的脑机接口公司今年有望完成10例手术
埃隆·马斯克的脑机接口公司Neuralink在一项新的进展中,已经为第二名患者成功植入了其创新的脑机接口设备。马斯克在一次节目中宣布了这一消息,并表示公司计划在今年内为另外8名患者进行植入手术,作为公司临床试验的一部分。这将标志着Neuralink在脑机接口领域的进一步发展,届时将完成总共10例植入手术。站长网2024-08-05 16:40:500000