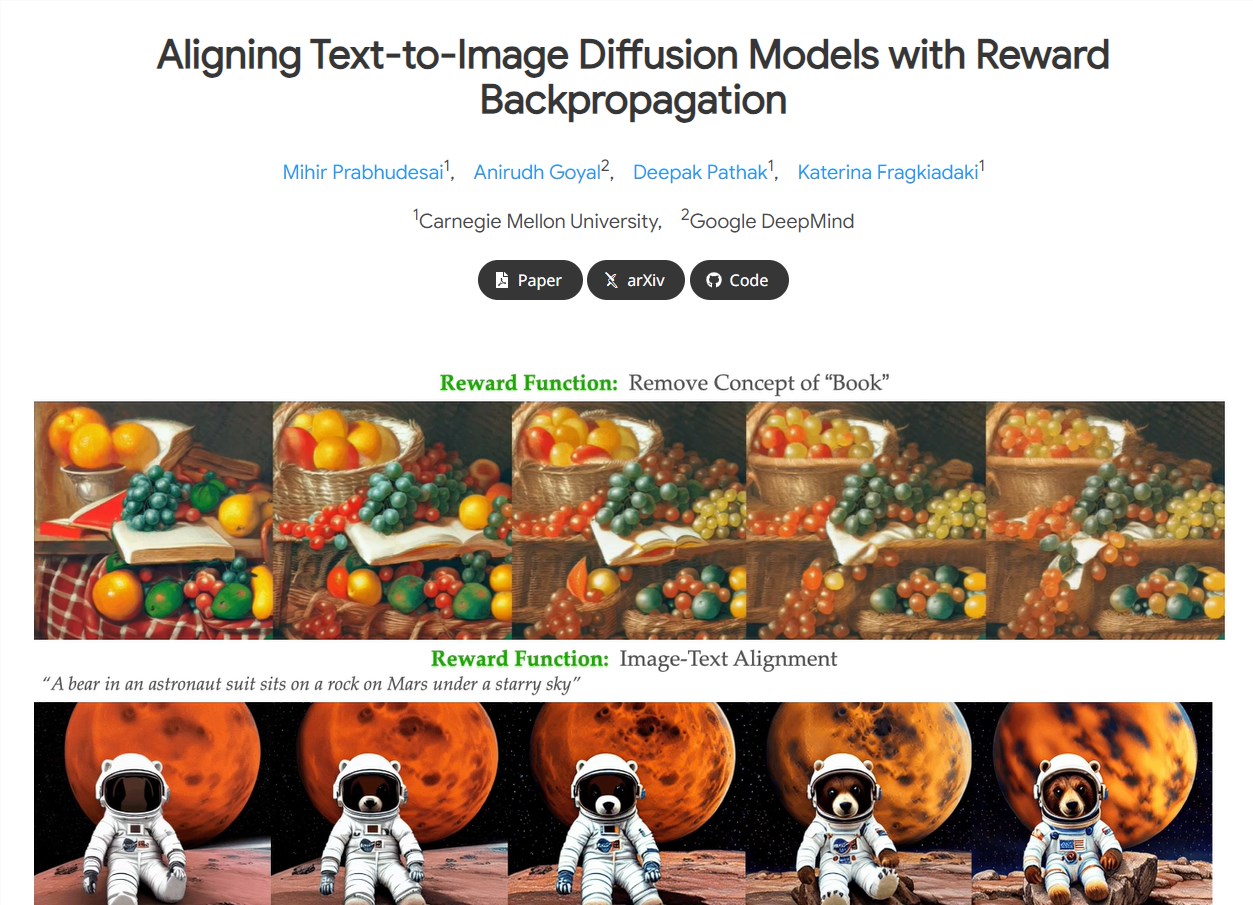
CMU与Google DeepMind研究人员推出AlignProp:微调文本到图像扩散模型的创新方法
卡内基梅隆大学(CMU)和Google DeepMind的研究人员引入了一种突破性的方法,称为"AlignProp"。该方法利用直接反向传播来微调文本到图像扩散模型,解决了将这些模型与所需的奖励功能对齐的挑战。AlignProp提供了一种更高效和有效的方式来优化文本到图像扩散模型,适用于图像生成等领域。
项目地址:https://align-prop.github.io/
概率扩散模型的崛起
概率扩散模型已经成为连续领域生成建模的标准。DALLE,一种文本到图像扩散模型,已经成为该领域的领导者。这些模型以其能够通过在广泛的网络规模数据集上训练来生成图像的能力而闻名。然而,它们的无监督或弱监督性质使得在下游任务中控制其行为,如优化图像质量、图像文本对齐或伦理图像生成成为一项具有挑战性的任务。
微调扩散模型的挑战
最近的尝试使用强化学习技术来微调扩散模型受制于梯度估算中的高方差。AlignProp通过在去噪过程中启用奖励梯度的端到端反向传播,从而对这一问题提供了创新性的解决方案,将扩散模型与所需的奖励功能对齐。
AlignProp的创新特点:
AlignProp引入了一些创新特点,以提高微调扩散模型的效率:
减轻高内存需求: AlignProp通过微调低秩适配器权重模块和实施梯度检查点来减轻通常与现代文本到图像模型的反向传播相关的高内存需求。
性能评估: 研究论文评估了AlignProp在微调扩散模型以实现各种目标的性能,包括图像文本语义对齐、美学、图像可压缩性以及生成图像中对象数量的可控性等目标的性能。AlignProp在较少的训练步骤中实现了更高的奖励,胜过了其他方法。
概念上的简单性: AlignProp因其概念上的简单性而备受赞誉,使其成为基于可区分奖励函数的扩散模型优化的明智选择。
提高采样效率和计算有效性
AlignProp利用从奖励函数获得的梯度来微调扩散模型。这种方法提高了采样效率和计算有效性。实验一致表明,AlignProp在优化一系列奖励函数方面的有效性,甚至对于难以仅通过提示定义的任务也是如此。
未来的研究方向
未来,研究人员可以探索将AlignProp的原则扩展到基于扩散的语言模型,以增强其与人类反馈的一致性。
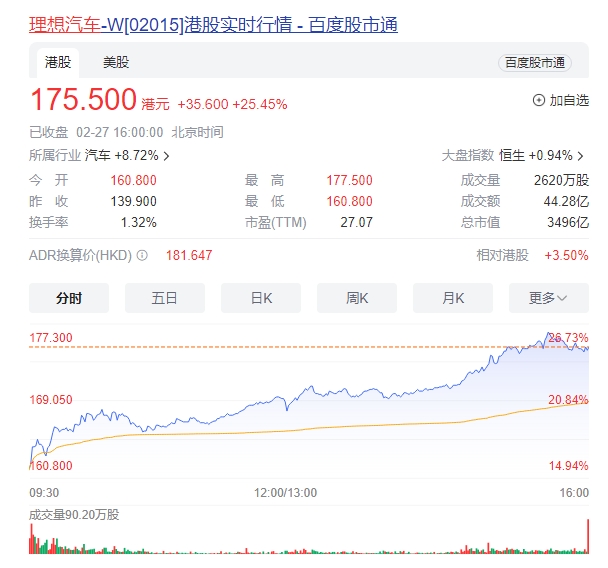
理想市值一天涨了1个小鹏 港股收盘涨幅达25.45%
站长之家(ChinaZ.com)2月28日消息:2月27日早间,美股收盘后,理想汽车股价飙升18%,迅速登上热搜。而港股开盘后,其涨幅更是超过美股,最高触及26%。至港股收盘,理想汽车单日涨幅高达25.45%,市值激增至3495.60亿港元(约合3215.95亿元人民币),一日之内市值增长超过740亿港元。站长网2024-02-28 08:10:090000组合式AI驱动生态系统XenonJs 像搭积木一样构建Web应用
XenonJs是一个模块化的Web开发框架,让开发者可以轻松创建和分享可定制的Web应用和组件。该框架具有以下核心优点:XenonJs采用组件化和图状态(GraphState)的模式,开发者可以像搭积木一样组合不同的组件和服务来构建Web应用。组件间采用标准化接口,实现松耦合和高内聚。开发者可以选择使用官方组件库中的现成组件,也可以开发自定义组件。组件和组件组合非常易于重用。站长网2023-09-12 10:24:010000马斯克星舰今晚第三次试飞 将首次尝试新技术
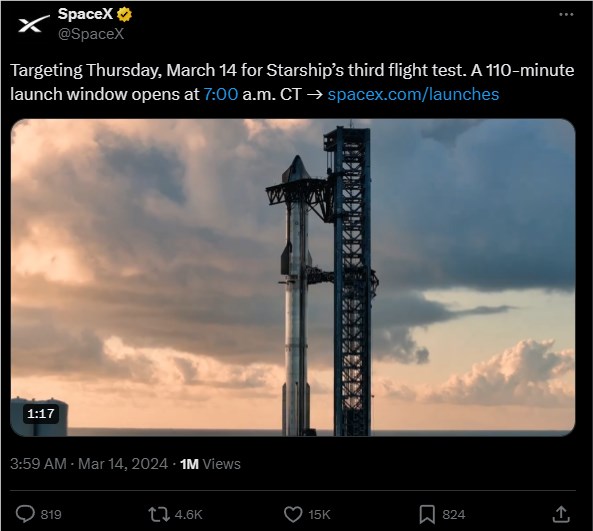
今日,马斯克旗下美国太空探索巨头SpaceX在备受瞩目的声明中公布,计划于3月14日进行星舰(Starship)的第三次试飞。此次发射的关键时间窗口设定在北京时间今晚20:00起的110分钟内,备受全球航天爱好者的关注。据悉,这次试飞任务将带来一个重大的技术突破:SpaceX将首次在太空中对猛禽发动机进行重新点火测试。这一技术的成功应用,将极大地提升星舰在未来太空探索任务中的灵活性和可靠性。站长网2024-03-14 10:28:220000Nomic AI发布开源嵌入模型Nomic Embed,击败OpenAI的Ada-002
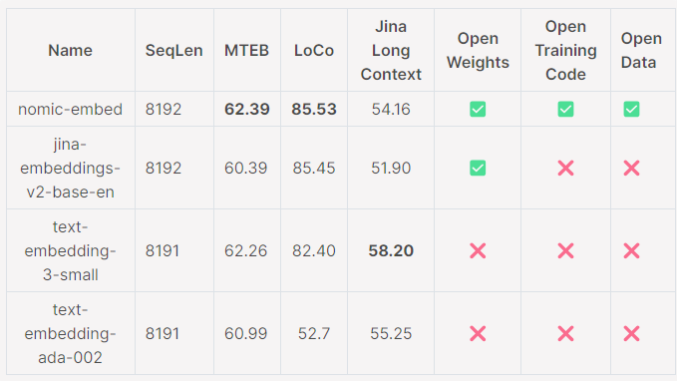
**划重点:**1.🏆NomicEmbed在短文和长文任务中胜过OpenAI的Ada-002和text-embedding-3-small模型。2.🔍模型支持最大8192的上下文长度,通过MassiveTextEmbeddingBenchmark(MTEB)和LoCoBenchmark表现优异。站长网2024-02-02 14:38:300000B站“亮底牌”,靠大开环直播导流打赢双11?
平台血拼低价,双11再起波澜,B站也在暗处悄悄使劲。9月,B站推出直播带货超新星计划,为UP主对接货源,持续开放各品类的招商。一个月后,B站陆续对外发布消息,称双11期间将为电商平台导流。站长网2023-11-06 17:11:470000