Kandinsky1:3.3亿参数强大模型,文本生成逼真图像
划重点:
1. 🌟 Kandinsky1:3.3亿参数的强大模型,以令人瞩目的图像生成质量表现
2. 🖼️ 文本到图像生成模型的演进,潜在扩散技术的引入
3. 📊 Kandinsky在COCO-30K验证数据集上取得8.03的FID分数,与最先进的文本到图像生成模型竞争激烈
最近几年,计算机视觉和生成建模领域取得了显著进展,推动了文本到图像生成的不断发展。各种生成架构,包括基于扩散的模型,在提高生成图像的质量和多样性方面发挥了关键作用。Kandinsky是一个拥有3.3亿参数的强大模型,并突出了它在可度量的图像生成质量方面的卓越表现。
文本到图像生成模型已经从具有内容级别工件的自回归方法演化到了基于扩散的模型,如DALL-E2和Imagen。这些扩散模型被归类为像素级和潜在级,它们在图像生成方面表现出色,超越了GANs在保真度和多样性方面的表现。它们无需敌对训练就能集成文本条件,这一事实由GLIDE和eDiff-I等模型所证明,它们生成低分辨率图像并使用超分辨率扩散模型进行升采样。这些进步已经改变了文本到图像生成的方式。
AIRI、Skoltech和Sber AI的研究人员引入了Kandinsky,这是一种结合了潜在扩散技术和图像先验模型的新型文本到图像生成模型。Kandinsky采用了改进的MoVQ实现作为其图像自动编码器组件,并单独训练图像先验模型,将文本嵌入映射到CLIP的图像嵌入。他们的方法提供了一个用户友好的演示系统,支持多样的生成模式,并发布了模型的源代码和检查点。

他们的方法引入了一种潜在扩散架构,用于文本到图像合成,利用了图像先验模型和潜在扩散技术。它采用了一种图像先验方法,将文本和图像嵌入之间的扩散和线性映射结合起来,使用CLIP和XLMR文本嵌入。他们的模型包括三个关键步骤:文本编码、嵌入映射(图像先验)和潜在扩散。基于完整数据集统计的视觉嵌入的逐元归一化实施,加速了扩散过程的收敛。
Kandinsky架构在文本到图像生成方面表现出色,以256×256的分辨率在COCO-30K验证数据集上获得了8.03的令人印象深刻的FID分数。线性先验配置产生了最佳的FID分数,表明视觉和文本嵌入之间存在潜在的线性关系。他们的模型的能力由在一组猫图像上训练“猫先验”而得到的图像生成成绩得以证明。总的来说,Kandinsky在文本到图像合成方面与最先进的模型竞争激烈。
Kandinsky是一种基于潜在扩散的系统,在图像生成和处理任务中表现出色。他们的研究广泛探讨了图像先验设计选择,线性先验显示出潜在的潜在线性关系。用户友好的界面,如Web应用程序和Telegram机器人,有助于提高可访问性。
未来的研究方向包括利用先进的图像编码器、改进UNet架构、改进文本提示、生成更高分辨率的图像,以及探索本地编辑和基于物理的控制等功能。研究人员强调了解决内容问题的需求,建议采取实时监管或强大的分类器来减轻不良输出。
论文网址:https://arxiv.org/abs/2310.03502
项目网址:https://github.com/ai-forever/Kandinsky-2
Kognitos发布生成式AI支持的业务自动化服务
Kognitos今天宣布了其新的自助式方法,使组织能够利用生成AI进行业务流程自动化。Kognitos一直在建立一个平台,允许组织使用自然人类语言来定义和启用BPA。这是该公司上个月在VBTransform活动上详细介绍的一种方法。这项新的提供,自助式生成AI适用于卓越中心和财务组织,扩展了该公司的平台,也是AI初创公司首次提供自助式服务,因为Kognitos旨在使商业用户更容易启用自动化。站长网2023-08-09 10:55:260000暗黑版GPT流窜暗网 降低犯罪门槛
随着AIGC应用的普及,不法分子利用AI技术犯罪的手段越来越高明,欺骗、敲诈、勒索也开始与人工智能沾边。近期,专为网络犯罪设计的“暗黑版GPT”持续浮出水面,它们不仅没有任何道德界限,更没有使用门槛,没有编程经验的小白能通过问答的方式实施黑客攻击。AI犯罪的威胁离我们越来越近,人类也开始加筑新的防火墙。网络犯罪AIGC工具现身暗网站长网2023-08-08 09:16:410000轻松识别Midjourney等AI生成图片,开源GenImage
AIGC时代,人人都可以使用Midjourney、StableDiffusion等AI产品生成高质量图片,其逼真程度肉眼难以区分真假。这种虚假照片有时会对社会产生不良影响,例如,生成公众人物不雅图片用于散播谣言;合成虚假图片用于金融欺诈,造成信任危机等。站长网2024-01-16 10:08:200000七部门:支持人工智能企业研发视听应用大模型
工业和信息化部等七部门印发《关于加快推进视听电子产业高质量发展的指导意见》。图源备注:图片由AI生成,图片授权服务商Midjourney其中提出,支持彩电龙头企业丰富产品矩阵,完善产业链条,开拓海外市场,持续提升生态主导力,引领行业发展。鼓励音箱、耳机、麦克风代工企业发展自有品牌,提升产品附加值和行业影响力。加快培育商用显示、车载视听、音视频领域的专精特新“小巨人”、制造业单项冠军。0000微信视频号上线原创标记外显、原创保护记录、创作分成计划
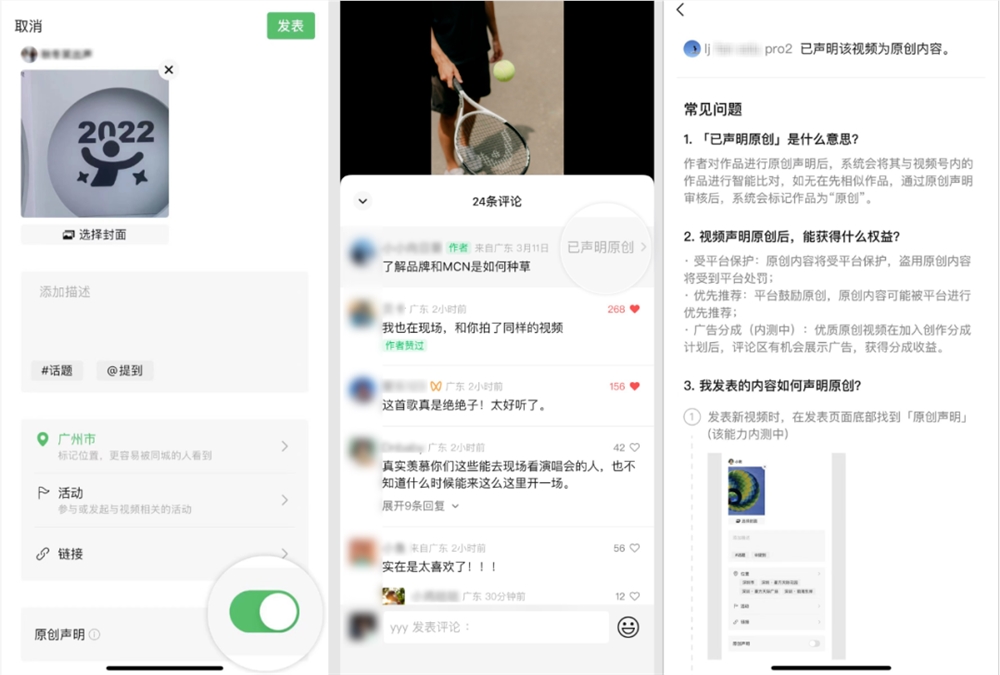
微信宣布,视频号上线3大原创能力:原创标记外显、原创保护记录、创作分成计划。原创标记外显在视频号内容发布时,页面最下端新增了“原创声明”功能,开启后即可选择“原创类型”,享受平台保护和优先推荐。通过原创声明审核后,这条视频的评论区将展示“已声明原创”标签,在创作者个人主页将展示累计原创条数。原创保护记录站长网2023-05-29 13:46:500000