LLM-Shearing大模型剪枝法:用5%的成本拿下SOTA,比从头开始预训练更划算
要点:
1. 陈丹琦团队开发了LLM-Shearing大模型剪枝法,可以将大型预训练模型剪枝至低成本,但高性能水平。
2. 剪枝方法将模型剪枝看作一种约束优化问题,同时学习剪枝掩码矩阵以最大化性能为目标。
3. 这种方法提供了一种有效的方式,可用于将剪枝后的模型继续预训练,最终超越从头开始预训练的模型。
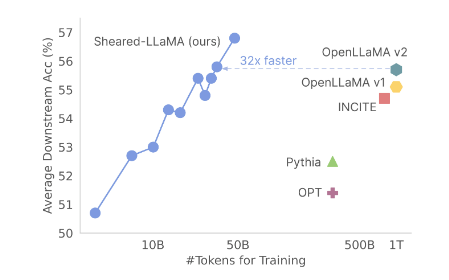
陈丹琦团队近期发布了一项重要的研究成果,他们开发了一种名为LLM-Shearing的大模型剪枝法。这项技术允许将庞大的预训练模型剪枝至仅需3%的计算量和5%的成本,同时保持着SOTA(State-of-the-Art)水平的性能。
这一成果的基础是以羊驼LLaMA2.7B为起点,通过有针对性的结构化剪枝,得到了1.3B和3B规模的Sheared-LLama模型。在各种下游任务评估中,这些剪枝后的模型表现出色,超越了之前的同等规模模型。
论文地址:
https://arxiv.org/abs/2310.06694
Hugging Face:
https://huggingface.co/princeton-nlp
项目主页:
https://xiamengzhou.github.io/sheared-llama/
该研究的首席作者夏梦舟指出,与从头开始预训练相比,这种剪枝方法在成本和性能方面更为划算。
研究团队还在论文中提供了剪枝后模型的示例输出,表明即使规模只有1.3B和2.7B,这些模型仍然能够生成连贯且内容丰富的回复。此外,相同规模下的不同版本模型在某些任务上还表现出更清晰的结构。

这一研究的重要性在于,虽然目前仅使用Llama2.7B模型进行了剪枝实验,但这种方法可扩展到其他模型架构和规模。此外,剪枝后的模型还可以进一步预训练,从而在一定程度上恢复因剪枝而导致的性能损失。
研究团队还解决了一个关键问题,即剪枝可能导致模型在不同数据集上性能下降的问题。他们提出了动态批量加载(Dynamic Batch Loading)的方法,通过根据模型在不同领域数据上的损失下降速率,动态调整每个领域的数据比例,从而提高数据使用效率。
实验证明,虽然剪枝模型最初表现较差,但通过继续预训练,最终可以超越与之规模相同但从头开始预训练的模型。
总而言之,这项研究的关键在于提供了一种高效的方式,可以将庞大的预训练模型剪枝至较低成本,同时保持高性能。这有望在大规模深度学习模型的研究和应用中产生广泛的影响。
iPhone16或垂直排列摄像头 将应用于iPhone16标准版
近日,有关iPhone16的摄像头设计引发了广泛关注。国外用户率先曝光了iPhone16的首个摄像头组件,证实了其后摄像头模组将重回垂直排列的消息。从曝光的图片来看,这款摄像头组件与现款iPhone15的对角线排列设计截然不同,而是采用了类似iPhone11时代的垂直排列方式。据MR证实,该组件将应用于iPhone16标准版。站长网2024-02-17 12:36:510000视频号青少年内容分级能力上线 青少年模式活跃用户同比增长35%
视频号宣布青少年内容分级新能力上线,家长给孩子开启青少年模式后,可以根据孩子的年龄、偏好的内容标签来设置专属的视频号青少年内容池。数据显示,青少年模式活跃用户同比增长35%,青少年爱看的视频内容包括科技科普、知识科普、美食旅行、运动生活、萌宠萌娃等等。另外,微信绿苗公开课检察官来了六大检察院、六大权威媒体联合开课,大小朋友观看人数超21万,累计曝光超2000万次。站长网2023-06-02 00:11:250000做小工具,4个人,400万/年收入。
各位村民好,我是村长。这几年大家都挺迷茫的。想要去创业,看起来外面有各种各样的项目,听每个人分享起来都是年入几千万、几个亿的。但是当自己看了一圈想要去做的时候,又感觉无从下手,感觉每个人项目都有人做了。这几年,除了在做传统的电商、短视频外,也在尝试做一些小项目。个人觉得小工具对于普通创业者来说,还算是一个不错的赚钱赛道,是有机会猥琐(闷声)发育,活下来赚到钱的。01信息差永远存在0000买手电商,小红书的“新解药”?
抖音有兴趣电商,快手有信任电商,小红书也有买手电商了。小红书披露的数据显示,截至11月3日,参与小红书电商双11的商家数量是去年的3.7倍。首次全面发力双11,小红书看样子是有备而来的。小红书跑出“买手电商”8月底,小红书提出买手制电商。小红书COO柯南在link电商伙伴周喊出“买手时代已来”,并透露,小红书每天有求购意图的用户数近4000万人,求链接、求购买等相关的评论近300万条。站长网2023-11-10 17:56:490000三星推出临时云备份服务:可免费存储30天
三星将推出全球范围内的临时云备份服务,为用户提供安全的数据存储和传输。通过使用三星账户,用户可以将重要数据上传到云存储,并在需要时下载,无需其他额外设备,只需连接WiFi。这项服务是免费的,没有总存储空间限制,单个文件大小上限为100GB,但数据最多只能存储30天。临时云备份功能将从今年秋季开始面向全球陆续推出,适用于运行OneUI6的所有三星Galaxy智能手机和平板电脑,包括国行版本。站长网2023-10-27 11:39:380000