卷完参数后,大模型公司又盯上了“长文本”?
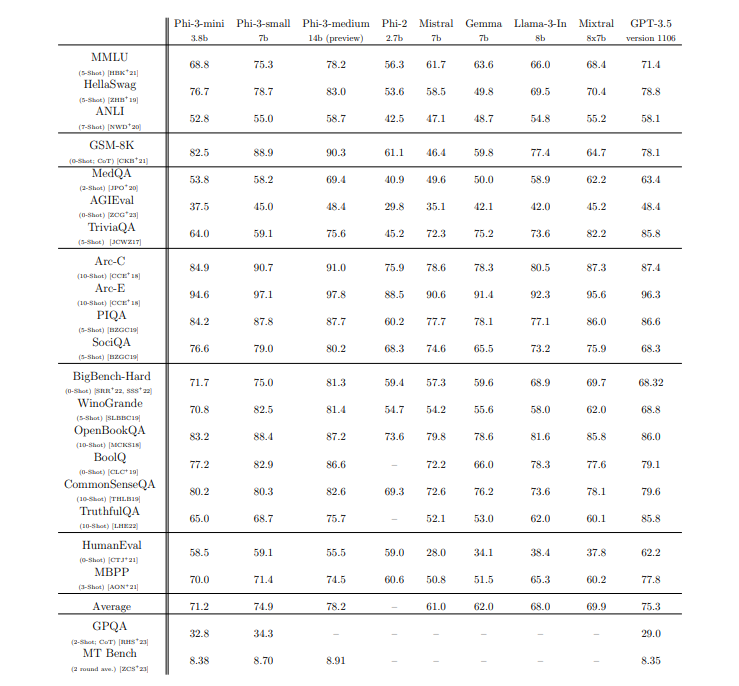
4000到40万token,大模型正在以“肉眼可见”的速度越变越“长”。
长文本能力似乎成为象征着大模型厂商出手的又一新“标配”。
国外,OpenAI经过三次升级,GPT-3.5上下文输入长度从4千增长至1.6万token,GPT-4从8千增长至3.2万token(token:模型输入和输出的基本单位);OpenAI最强竞争对手Anthropic一次性将上下文长度打到了10万token;LongLLaMA将上下文的长度扩展到25.6万token,甚至更多。
国内,光锥智能获悉,大模型初创公司月之暗面发布智能助手产品Kimi Chat可支持输入20万汉字,按OpenAI的计算标准约为40万token;港中文贾佳亚团队联合MIT发布的新技术LongLoRA,可将7B模型的文本长度拓展到10万token,70B模型的文本长度拓展到3.2万token。
据光锥智能不完全统计,目前,国内外已有OpenAI、Anthropic、Meta、月之暗面等一大批顶级的大模型技术公司、机构和团队将对上下文长度的拓展作为更新升级的重点。
毫无例外,这些国内外大模型公司或机构都是资本市场热捧的“当红炸子鸡”。
OpenAI自不必说,大模型Top级明星研究机构,斩获投资近120亿美元,拿走了美国生成式AI领域60%的融资;Anthropic近期风头正盛,接连被曝亚马逊、谷歌投资消息,前后相差不过几天,估值有望达到300亿美元,较3月份翻五番;成立仅半年的月之暗面出道即巅峰,一成立就迅速完成首轮融资,获得红杉、真格、今日资本、monolith等一线VC的押注,市场估值已超过3亿美元,而后,红杉孵化式支持,循序完成两轮共计近20亿元融资。
大模型公司铆足劲攻克长文本技术,上下文本长度扩大100倍意味着什么?
表面上看是可输入的文本长度越来越长,阅读能力越来越强。
若将抽象的token值量化,GPT-3.5的4000token最多只能输入3000个英文单词或者2000个汉字,连一篇公众号文章都难以读完;3.2万token的GPT-4达到了阅读一篇短篇小说的程度;10万token的Claude可输入约7.5万个单词,仅22秒就可以阅读完一本《了不起的盖茨比》;40万token的Kimi Chat支持输入20万汉字,阅读一本长篇巨著。
另一方面,长文本技术也在推动大模型更深层次的产业落地,金融、司法、科研等精艰深的领域里,长文档摘要总结、阅读理解、问答等能力是其基本,也是亟待智能化升级的练兵场。
参考上一轮大模型厂商“卷”参数,大模型参数不是越大就越好,各家都在通过尽可能地扩大参数找到大模型性能最优的“临界点”。同理,作为共同决定模型效果的另一项指标——文本长度,也不是越长,模型效果就越好。
有研究已经证明,大模型可以支持更长的上下文输入与模型效果更好之间并不能直接画上等号。模型能够处理的上下文长度不是真正的关键点,更重要的是模型对上下文内容的使用。
不过,就目前而言,国内外对于文本长度的探索还远没有达到“临界点”状态。国内外大模型公司还在马不停蹄地突破,40万token或许也还只是开始。
为什么要“卷”长文本?
月之暗面创始人杨植麟告诉光锥智能,在技术研发过程中,其团队发现正是由于大模型输入长度受限,才造成了许多大模型应用落地的困境,这也是月之暗面、OpenAI等一众大模型公司在当下聚焦长文本技术的原因所在。
比如在虚拟角色场景中,由于长文本能力不足,虚拟角色会忘记重要信息;基于大模型开发剧本杀类游戏时,输入prompt长度不够,则只能削减规则和设定,从而无法达到预期游戏效果;在法律、银行等高精度专业领域,深度内容分析、生成常常受挫。
在通往未来Agent和AI原生应用的道路上,长文本依然扮演着重要的角色,Agent任务运行需要依靠历史信息进行新的规划和决策,AI原生应用需要依靠上下文本来保持连贯、个性化的用户体验。
杨植麟认为,无论是文字、语音还是视频,对海量数据的无损压缩可以实现高程度的智能。“无损压缩或大模型研究的进展曾极度依赖‘参数为王’模式,该模式下压缩比直接与参数量相关。但我们认为无损压缩比或大模型的上限是由单步能力和执行的步骤数共同决定的。其中,单步能力与参数量呈正相关,而执行步骤数即上下文长度。”
如果形象化地去理解这句话,“无损压缩”就像是一位裁缝,需要把一块完整的布裁剪成合身的衣服。一开始这位裁缝的思路是要去准备各种尺寸的裁剪模板(参数),模板越多,裁剪出来的衣服也越合身。但现在的新思路是,即使模板不多,只要反复裁剪、量体裁衣也能使衣服极致合身。
同时,事实已经证明,即使是千亿参数的大模型也无法完全避免幻觉和胡说八道的问题。相比于短文本,长文本可以通过提供更多上下文信息和细节信息,来辅助模型判断语义,进一步减少歧义,并且基于所提供事实基础上的归纳、推理也更加准确。
由此可见,长文本技术既可以解决大模型诞生初期被诟病的一些问题,增强一些功能,同时也是当前进一步推进产业和应用落地的一环关键技术,这也从侧面证明通用大模型的发展又迈入了一个新的阶段,从LLM到Long LLM时代。
透过月之暗面的新发布的Kimi Chat,或许能一窥Long LLM阶段大模型的升级功能。
首先是对超长文本关键信息提取、总结和分析的基础功能。如输入公众号的链接可以快速分析文章大意;新出炉的财报可以快速提取关键信息,并能以表格、思维导图等简洁的形式呈现;输入整本书、专业法律条文后,用户可以通过提问来获取有效信息。
在代码方面,可以实现文字直接转化代码,只要将论文丢给对话机器人,就能根据论文复现代码生成过程,并能在其基础上进行修改,这比当初ChatGPT发布会上,演示草稿生成网站代码又进了一大步。

在长对话场景中,对话机器人还可以实现角色扮演,通过输入公众人物的语料,设置语气、人物性格,可以实现与乔布斯、马斯克一对一对话,国外大模型公司Character AI已经开发了类似的AI伴侣应用,且移动端的DAU远高于ChatGPT,达到了361万。在月之暗面的演示中,只需要一个网址,就可以在Kimi Chat中和自己喜欢的原神角色聊天。
以上的例子,共同说明了脱离简单的对话轮次,类ChatGPT等对话机器人正在走向专业化、个性化、深度化的发展方向,这或许也是撬动产业和超级APP落地的又一抓手。
杨植麟向光锥智能透露,不同于OpenAI只提供ChatGPT一个产品和最先进的多模态基础能力,月之暗面瞄准的是下一个C端超级APP:以长文本技术为突破,在其基础通用模型基础上去裂变出N个应用。
“国内大模型市场格局会分为 toB 和 toC 两个不同的阵营,在 toC 阵营里,会出现super-app,这些超级应用是基于自研模型做出来的。”杨植麟判断道。
不过,现阶段市面上的长文本对话场景还有很大的优化空间。比如有些不支持联网,只能通过官方更新数据库才获得最新信息;在生成对话的过程中无法暂停和修改,只能等待对话结束;即使有了背景资料和上传文件支持,还是偶尔会出现胡说八道、凭空捏造的情况。
长文本的“不可能三角”困境
在商业领域有一组典型的价格、质量和规模的“不可能三角”,三者存在相互制约关系,互相之间不可兼得。
在长文本方面,也存在文本长短、注意力和算力类似的“不可能三角”。
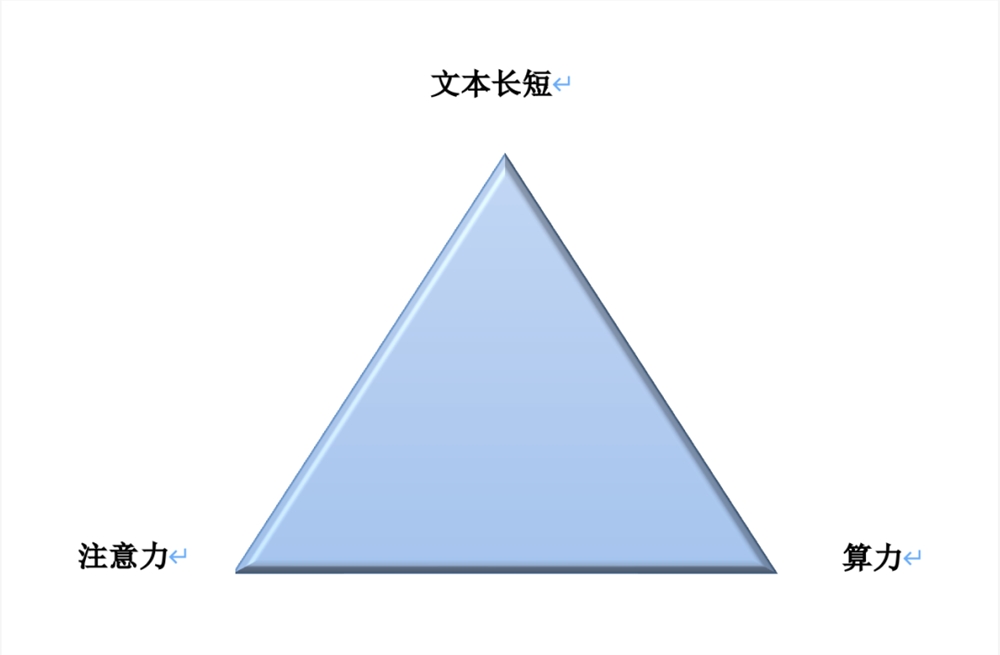
(图:文本长短、注意力、算力“不可能三角”)
这表现为,文本越长,越难聚集充分注意力,难以完整消化;注意力限制下,短文本无法完整解读复杂信息;处理长文本需要大量算力,提高成本。
追本溯源,从根本上看这是因为现在大部分模型都是基于Transformer结构。该结构中包含一项最重要的组件即自注意力机制,在该机制下,对话机器人就可以跨越用户输入信息顺序的限制,随意地去分析各信息间的关系。
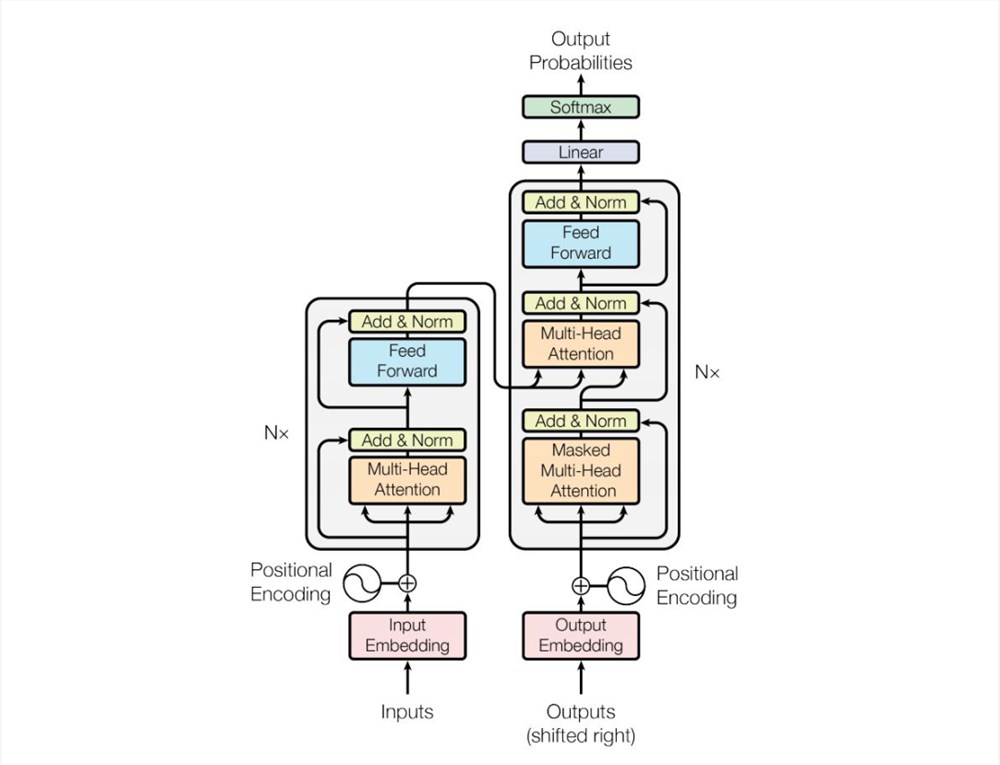
(图:Transformer结构)
但与之带来的代价是,自注意力机制的计算量会随着上下文长度的增加呈平方级增长,比如上下文增加32倍时,计算量实际会增长1000倍。
一些发表的论文给予了佐证:过长的上下文会使得相关信息的占比显著下降,加剧注意力分散似乎成为了不可避免的命运。
这就构成了“不可能三角”中的第一组矛盾——文本长短与注意力,也从根本上解释了大模型长文本技术难以突破的原因。
从“卷”大模型参数到现在,算力一直都是稀缺的资源。OpenAI创始人Altman曾表示,ChatGPT-432K的服务无法立马完全向所有用户开放,最大的限制就在于GPU短缺。
对此,杨植麟也称:“GPU是一个重要的基础,但还不光是GPU的问题。这里面是不同因素的结合,一方面是GPU,一方面是能源转换成智能的效率。效率进一步拆解可能包含算法的优化、工程的优化、模态的优化以及上下文的优化等等。”
更为重要的是,在大模型实际部署环节,企业端根本无法提供很大的算力支持,这也就倒逼厂商无论是扩大模型参数还是文本长度,都要紧守算力一关。但现阶段要想突破更长的文本技术,就不得不消耗更多的算力,于是就形成了文本长短与算力之间的第二组矛盾。
腾讯NLP工程师杨雨(化名)表示:“大模型长文本建模目前还没有一个统一的解决方案,造成困扰的原因正是源于Transformer自身的结构,而全新的架构已经在路上了。”
当前无论从软件还是硬件设计,大部分都是围绕Transformer架构来打造,短时间内新架构很难完全颠覆,但围绕Transformer架构产生了几种优化方案。
杨雨对光锥智能说,“目前主要有三种不同的解决方案,分别为借助模型外部工具辅助处理长文本,优化自注意力机制计算和利用模型优化的一般方法。”
第一种解决方案的核心思路就是给大模型开“外挂”。主要方法是将长文本切分为多个短文本处理,模型在处理长文本时,会在数据库中对短文本进行检索,以此来获得多个短文本回答构成的长文本。每次只加载所需要的短文本片段,从而避开了模型无法一次读入整个长文本的问题。
第二种解决方案是现在使用最多的方法,主要核心在于重新构建自注意力计算方式。比如LongLoRA技术的核心就在于将长文本划分成不同的组,在每个组里进行计算,而不用计算每个词之间的关系,以此来降低计算量,提高速度。
前两种模式也被杨植麟称之为“蜜蜂”模型,即通过对检索增强的生成或上下文的降采样,保留对部分输入的注意力机制,来实现长文本处理的效果。
据杨植麟介绍,在优化自注意力机制计算还存在一种方式,也被其称之为 “金鱼”模型。即通过滑动窗口等方式主动抛弃上文,以此来专注对用户最新输入信息的回答。这样做的优点显而易见,但是却无法跨文档、跨对话比较和总结分析。
第三种解决方案是专注于对模型的优化。如LongLLaMA以OpenLLaMA-3B和OpenLLaMA-7B 模型为起点,在其基础上进行微调,产生了LONGLLAMAs新模型。该模型很容易外推到更长的序列,例如在8K token上训练的模型,可以很容易外推到256K窗口大小。
对模型的优化还有一种较为普遍的方式,就是通过通过减少参数量(例如减少到百亿参数)来提升上下文长度,这被杨植麟称之为 “蝌蚪”模型。这种方法会降低模型本身的能力,虽然能支持更长上下文,但是任务难度变大后就会出现问题。
长文本的“不可能三角”困境或许暂时还无解,但这也明确了大模型厂商在长文本的探索路径:在文本长短、注意力和算力三者之中做取舍,找到最佳的平衡点,既能够处理足够的信息,又能兼顾注意力计算与算力成本限制。
戴尔CTO预测量子计算和生成式AI将在未来五年内实现交汇
**划重点:**1.🚀AI将推动先进硬件、边缘设备和网络安全等新兴技术协同发展,助力业务转型。2.⚙️戴尔技术预测在未来五年内,量子计算和生成式人工智能将交汇,实现实际应用。3.🔒安全将成为关键焦点,生成式人工智能从建立培训基础设施将转向推理基础设施。站长网2023-12-04 16:52:250000AI日报:微软发布iPhone可运行AI模型;全国首例AI声音侵权案判了;Kimi创始人套现数千万美金;中文聊天模型Llama3发布
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、腾讯SaaS产品智能化升级全面接入混元模型站长网2024-04-23 17:49:020000魅族推出 XR 品牌 “MYVU” 采用FlymeAR交互系统
2023魅族秋季无界生态发布会将于11月30日14:30举行,届时将发布AR眼镜、全新Flyme及FlymeAuto生态系统、魅族21、PANDAER等产品。星纪魅族集团今天揭晓了全新的XR品牌“MYVU”,并公布了其Slogan:“唯我独见IT'SMYVIEW”。站长网2023-11-27 10:51:260000苹果发布iOS 17.3.1:修复iPhone输入法崩溃等问题
2月9日是农历兔年的最后一天,也是除夕。今天凌晨,苹果为iPhone用户推送了iOS17.3.1正式版更新。此次更新的安装包大小约为281MB,内部版本号为21D61。根据了解,本次iOS17.3.1升级幅度较小,仅是对一些小问题进行了修复。0000B站UP主手作AI男士婚纱引围观 视频播放量超43万
B站UP主“钙星球”受到AI绘图生成的男士婚纱照的启发,策划了一个多月,成功制作了一套男士婚纱,并在视频中展示了设计过程。他发现男士婚纱需要在突出男性特征的同时传达虔诚和纯洁感。现有的AI生成男士婚纱主要有两种类型:硬朗的西装和纯洁梦幻的蕾丝纱裙,都注重宽肩窄腰的设计。站长网2023-09-19 15:24:300000