AI日报:微软发布iPhone可运行AI模型;全国首例AI声音侵权案判了;Kimi创始人套现数千万美金;中文聊天模型Llama3发布
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。
新鲜AI产品点击了解:https://top.aibase.com/
1、腾讯SaaS产品智能化升级 全面接入混元模型
腾讯宣布旗下协作SaaS产品全面接入混元模型,实现软件服务智能化。腾讯乐享、腾讯电子签、腾讯问卷等产品已实现智能化升级,为用户提供更智能、高效的服务。混元大模型已扩展至万亿级参数规模,在国内率先采用混合专家模型结构,性能表现优异。外部开发者和企业可以通过腾讯云上API直接调用腾讯混元能力,解决用户痛点。
【AiBase提要:】
🚀 腾讯SaaS产品实现智能化升级,提供更智能、高效的服务。
💡 混元大模型扩展至万亿级参数规模,性能在多方面表现优异。
🔗 外部开发者和企业可通过腾讯云API调用混元能力,解决不同场景下的痛点。
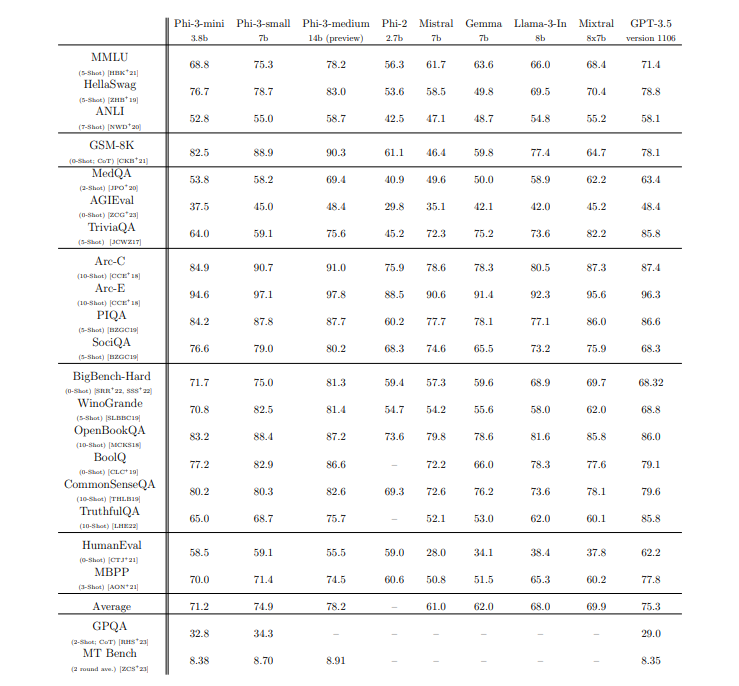
2、微软发布iPhone可运行的ChatGPT级AI模型Phi-3系列 挑战OpenAI地位
微软最新推出的Phi-3系列小型AI模型在AI领域引起轰动,尤其是Phi-3-mini模型在多项基准测试中超越了参数更大的Llama3模型。该系列模型能在iPhone14Pro和iPhone15上实现每秒12token的运行速度,达到了ChatGPT水平。微软强调训练数据的重要性,通过精心设计数据和训练方法提升模型性能。
【AiBase提要:】
🚀 Phi-3-mini模型参数仅3.8B,性能超越8B参数的Llama3模型。
💡 Phi-3系列包括Phi-3-small和Phi-3-medium版本,性能优越。
🔍 微软团队通过精心设计训练数据和独特训练方法提升了Phi-3系列模型的性能。
详情链接:https://arxiv.org/pdf/2404.14219.pdf
3、全国首例AI声音侵权案一审宣判 自己声音被AI化出售获赔25万元
这篇文章报道了全国首例AI声音侵权案的一审判决结果,涉及配音师声音被AI技术滥用的案件引起社会广泛关注。法院裁定被告未经授权擅自使用配音师声音开发AI产品构成侵权,需赔偿25万元。判决强调声音作为人格权益应受法律保护,为声音创作者提供了重要法律保障。
【AiBase提要:】
🔍 首例AI声音侵权案一审判决结果:被告未经授权使用配音师声音开发AI产品,需赔偿25万元。
💡 法院强调声音作为独特人格权益应受法律保护,未经授权擅自使用声音构成侵权行为。
👩⚖️ 判决为声音创作者提供了重要法律保障,将坚决维护声音权益并打击侵权行为。
4、中文聊天模型Llama3-8B-Chinese-Chat发布
这篇文章介绍了基于Meta-Llama-3-8B-Instruct模型经过ORPO方法微调的中文聊天模型Llama3-8B-Chinese-Chat。该模型减少了中英混合回答和表情符号的使用,使得回答更正式和专业。它在理解中文问题意图、提供恰当回答、拒绝不当请求等方面表现出色。
【AiBase提要:】
🔑 Llama3-8B-Chinese-Chat是基于Meta-Llama-3-8B-Instruct模型通过ORPO方法微调的中文聊天模型,减少了中英混合回答和表情符号的使用。
🌟 ORPO方法利用赔率比概念调整模型偏好设置,优化模型在特定任务中的表现,Llama3-8B-Chinese-Chat模型使用ORPO优化中英文生成偏好。
💡 Llama3-8B-Chinese-Chat模型在安全、道德、数学问题解答、写作和编程示例等方面表现出色,提供更准确、专业的回答和示例代码。
详情链接:https://top.aibase.com/tool/llama3-8b-chinese-chat
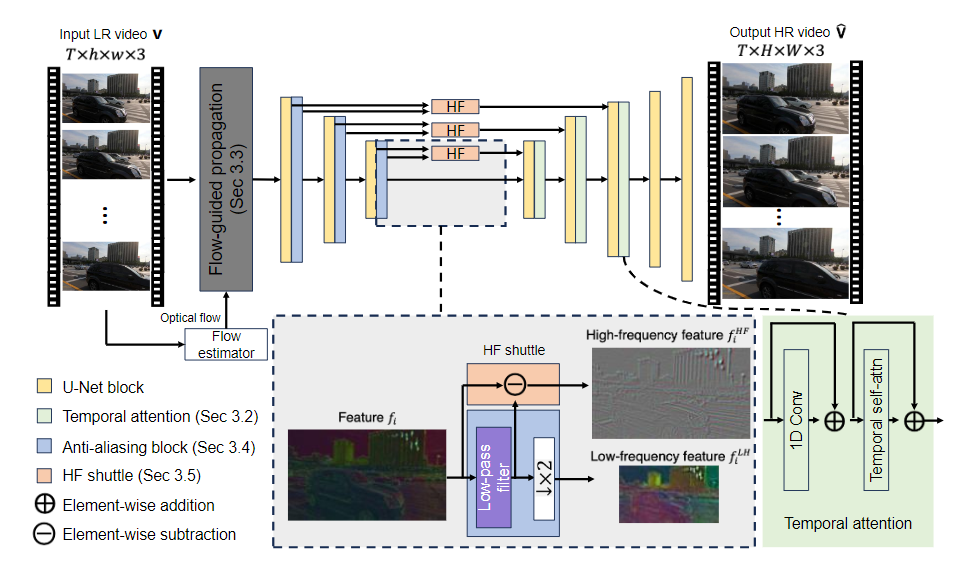
5、Adobe发布视频超分辨率项目VideoGigaGAN
Adobe最近推出了视频超分辨率项目VideoGigaGAN,该项目在视频放大技术方面取得了显著进展,能将视频放大至原始分辨率的8倍,保持时间连贯性和高频细节清晰度。这一技术将视频处理带入新阶段,极大扩展了视频内容的应用范围和质量。
【AiBase提要:】
✨ VideoGigaGAN实现视频放大至8倍原始分辨率,保持时间连贯性和高频细节清晰度。
🔍 Adobe优化GigaGAN模型,增强视频稳定性,展示卓越性能。
💡 VideoGigaGAN提升视频视觉质量,适应不同风格视频内容,具有广泛的应用潜力。
详情链接:https://top.aibase.com/tool/videogigagan
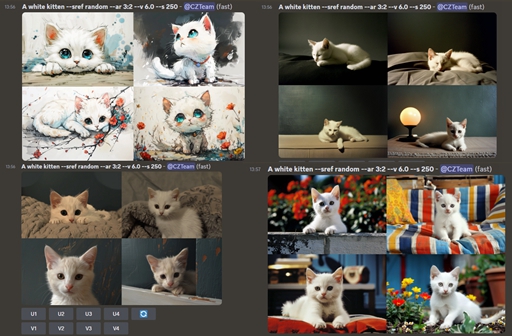
6、Midjourney发布random功能 可基于提示词生成完全随机的图像风格
Midjourney发布了一个有趣的功能,可以基于提示词生成完全随机的图像风格。用户可以通过随机生成的图像风格来探索不同的创作方向,同时还可以与其他用户进行实时交流和分享,共同探讨创作过程中的灵感和想法。这一功能的推出将进一步丰富用户的图像生成体验,为他们提供更多的创作选择和交流平台。
【AiBase提要:】
⚙️ 可基于提示词生成完全随机的图像风格
💬 用户可以通过Room功能进行实时交流和分享
🎨 探索不同的创作方向,丰富用户的图像生成体验
7、AI独角兽月之暗面创始人杨植麟套现数千万美金 官方回应
杨植麟作为月之暗面创始人,通过个人股份销售套现数千万美元,引起广泛关注。公司成立仅一年便获得巨额融资,估值超过25亿美元。月之暗面的成功不仅在估值上体现,旗舰产品Kimi Chat的成功也备受瞩目。
【AiBase提要:】
🚀 月之暗面创始人杨植麟通过个人股份销售套现数千万美元,公司估值超过25亿美元。
💡 月之暗面创立仅一年便迅速崛起,成为中国大模型领域独角兽之一。
💬 月之暗面旗舰产品Kimi Chat凭借“长文本”功能在AI大模型领域脱颖而出,引发资本市场热潮。
8、毫不犹豫!小扎自曝愿开源100亿美元模型 直言2025年之前AGI不可能实现
在最新的播客访谈中,小扎展现了开源英雄形象,表示愿意开源价值100亿美元模型,强调开源降低成本促进创新,但也需综合考虑经济利弊。他对2025年之前AGI实现持悲观态度,认为能源短缺是瓶颈,解决可能需数十年。批评苹果和谷歌独占移动生态,希望通过开源改变局面,防范竞争对手威胁。对于人工智能发展瓶颈,担忧能源限制和数据中心挑战,持保留态度未来AI模型能力提升。
【AiBase提要:】
💡 小扎愿意开源价值100亿美元模型,认为开源降低成本促进创新,但需综合考虑经济利弊。
💡 对2025年之前AGI实现持悲观态度,认为能源短缺是瓶颈,解决可能需数十年。
💡 批评苹果和谷歌独占移动生态,希望通过开源改变局面,防范竞争对手威胁。
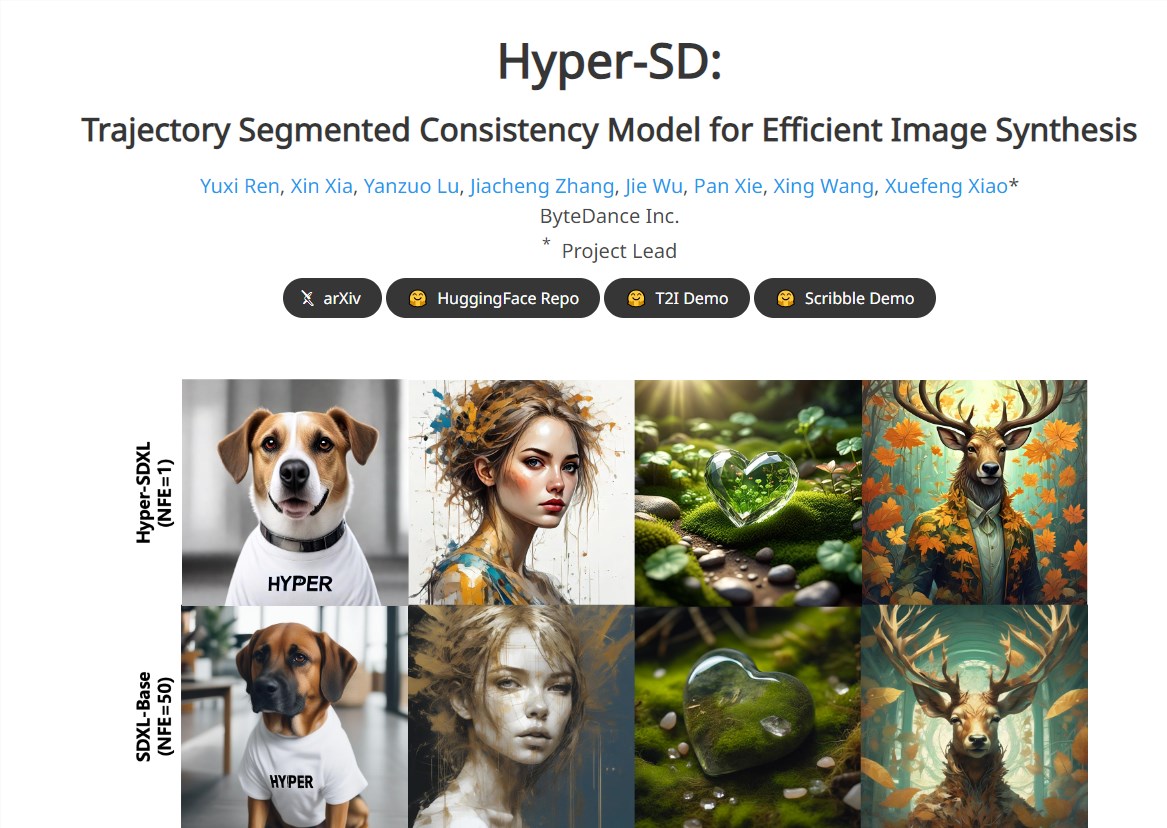
9、字节跳动发布图像模型蒸馏算法Hyper-SD
这篇文章介绍了字节跳动的Lightning团队发布的新图像模型蒸馏算法Hyper-SD,该算法在图像处理和机器学习领域取得重要进展。通过创新的方法提升了模型性能,在保持模型精简的同时提高了推理速度和效率。
【AiBase提要:】
⚙️ 分段轨迹一致性蒸馏:Hyper-SD技术确保了原始ODE轨迹的完整性。
🧠 人类反馈学习机制:引入人类反馈学习,提升模型表现,减少性能损失。
🔬 分数蒸馏技术:增强了模型在低步推理下的生成能力,进一步提升性能。
详情链接:https://top.aibase.com/tool/hyper-sd
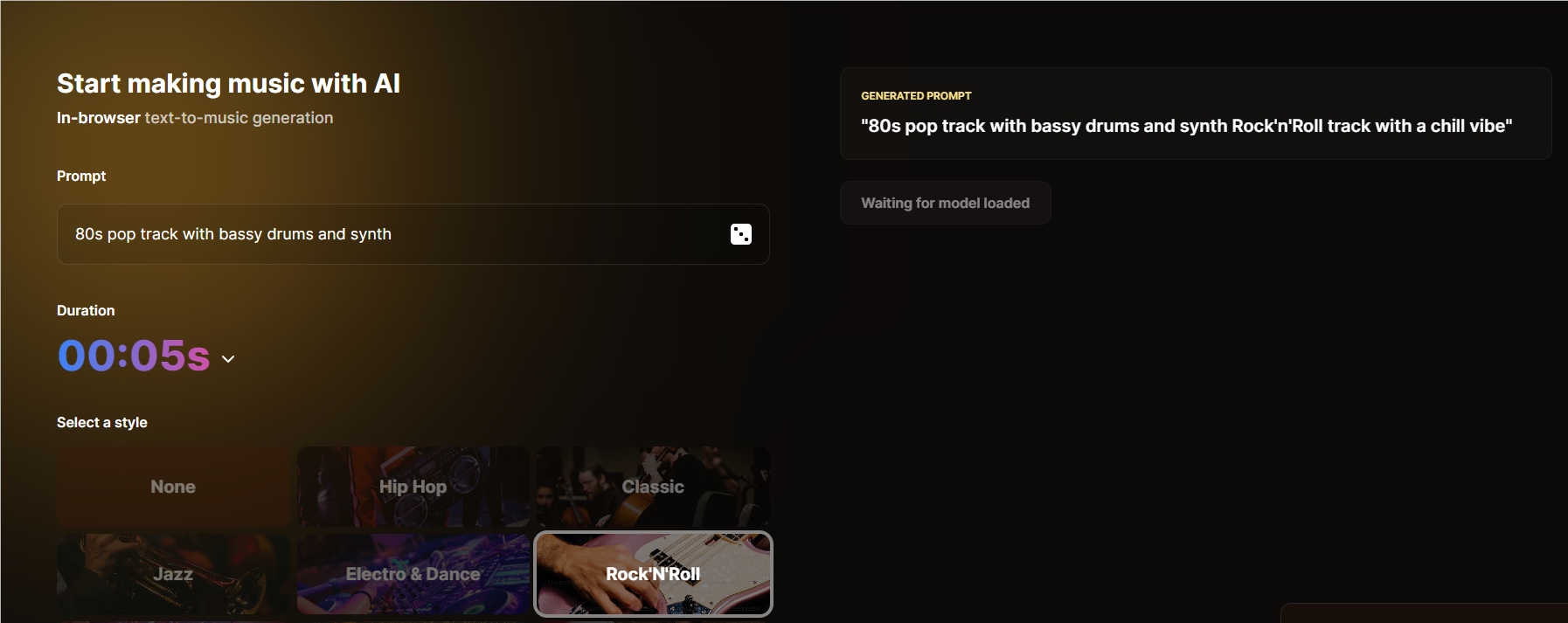
10、AI音乐生成工具AI Jukebox 输入提示词选择曲风即可创作音乐
AI Jukebox是一款利用人工智能技术的音乐生成工具,通过Hugging Face平台提供服务。它简化音乐创作过程,智能化且用户友好。用户可以通过输入提示词指导AI生成特定风格音乐,实现智能化音乐创作。AI Jukebox鼓励人机合作模式,为音乐人和音乐爱好者提供灵感和创作工具,探索无限可能性。
【AiBase提要:】
🎵 本地化模型加载: 用户打开AI Jukebox的网页后,系统自动加载生成模型,无需复杂设置。
🎶 基于提示词的音乐生成: 用户通过输入特定提示词指导AI生成特定风格音乐,包括音乐类型、情感、乐器等描述。
🎼 人机合作模式: AI Jukebox鼓励用户与AI合作,探索新的音乐创作方式,提供灵感和创作工具。
详情链接:https://top.aibase.com/tool/ai-jukebox
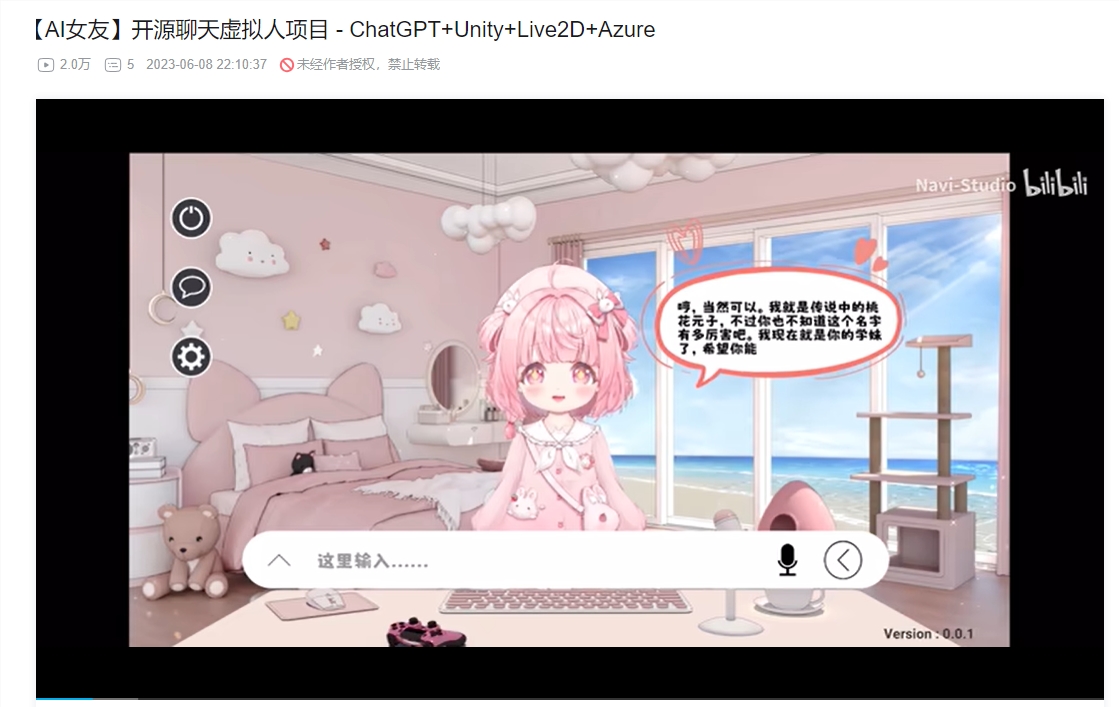
11、虚拟人聊天系统Live2D
这篇文章介绍了基于Unity开发的Live2D虚拟人聊天系统项目,利用Live2D技术展现动态虚拟人形象,提供流畅的动画效果,增强用户交互体验。项目集成了Azure、OpenAI和APISpace等API支持自然语言处理和生成,实现实时文本交流。同时支持图像处理和人脸检测,高清分辨率显示,以及自定义扩展功能。
【AiBase提要:】
👩💻 Live2D虚拟人形象集成,提供流畅的动画效果,增强用户体验。
💬 实时聊天功能,虚拟人能理解并回应用户文本输入,实现实时交流。
🔍 图像处理和人脸检测,让虚拟人更好地响应用户视觉输入。
详情链接:https://top.aibase.com/tool/live2d-virtual-human-for-chatting-based-on-unity
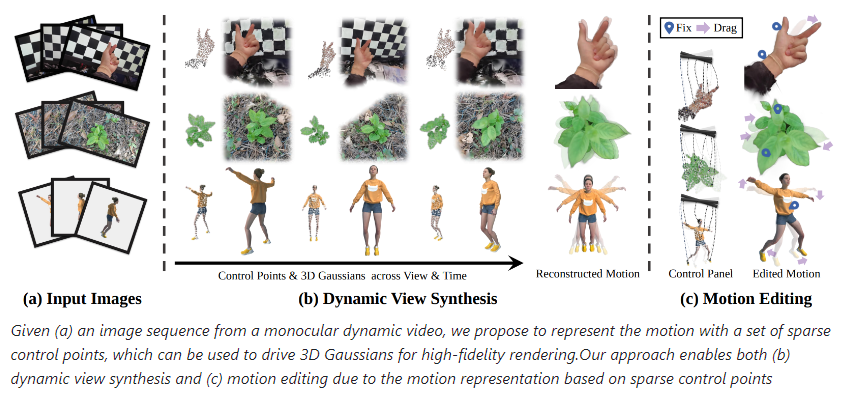
12、港大与浙大联合研发SC-GS模型
本文介绍了香港大学CVMI实验室与3D大模型公司VAST以及浙江大学联合研究团队提出的SC-GS模型,该模型在数字资产创造和3D重建领域取得突破性成果。通过稀疏控制点实时交互编辑,实现了对动态场景的高效编辑和合成,展现了巨大潜力。
【AiBase提要:】
🌟 SC-GS模型在新视角合成领域掀起革命性浪潮,展现出对动态高斯的稀疏控制点进行实时交互编辑的能力。
🔑 用户可以通过简单的鼠标拖拽和键盘组合按键操作,轻松实现对重建动态场景的编辑。
💡 SC-GS模型通过神经网络预测控制点运动状态,驱动整个场景中的动态高斯进行变形,提升了动态新视角合成的性能。
详情链接:https://top.aibase.com/tool/sc-gs
13、新视频分割技术SAM 可高效识别移动物体
本文介绍了在视频分割领域,研究团队探索新的视频对象分割技术,通过结合SAM模型和光流技术,提高了视频分割性能。两种模型展示了潜力,实现了显著性能提升,并将分割技术扩展到整个视频序列,实现物体追踪。这些技术提升了视频分割精度和效率,降低了计算复杂度,对多个应用场景具有重要意义。

【AiBase提要:】
⚙️ SAM与光流结合的模型展示了提高视频分割性能的潜力。
🔍 SAM与RGB图像结合的模型增强了模型对视频中物体运动的识别和分割能力。
🚀 将基于帧的分割方法扩展到整个视频序列,实现了物体在视频连续帧中的身份追踪。
详情链接:https://www.robots.ox.ac.uk/~vgg/research/flowsam/
OpenAI 和 Axel Springer 达成史无前例的协议,允许 ChatGPT 摘要其付费新闻内容
OpenAI和全球新闻出版商AxelSpringer周三宣布,双方达成了一项史无前例的协议,允许ChatGPT总结来自Politico和BusinessInsider等媒体的新闻报道。图片来自AxelSpringer站长网2023-12-14 09:43:080000MidReal AI更新Beta版本 官网上线推荐小说页面
AI小说生成工具MidRealAI最新更新了Beta版本,不仅更新了模型,还增加了许多新功能。新模型生成的内容更有逻辑,更连贯。同时,官网上线了小说展厅,用户可以在官网上查看推荐的小说,比在Discord上阅读更加舒适。此外,还增加了新功能,比如使用“/start_private”命令可以创建完全私密的内容,让用户不用担心发布的提示词导致自己社交媒体上的尴尬。站长网2024-01-03 09:49:510000被吹爆的GPT-4o真有那么强?这有23个案例实测
距离OpenAI正式发布GPT-4o生图功能(2025年3月25日),已经过去两周多了。这段时间里,“ChatGPT-4o颠覆了AI图像生成的逻辑”这句话大家应该都听腻了。但说实话,因为区域限制、付费制这些门槛,真正能上手用一用的朋友可能并不太多。0000小米汽车海报正式亮相 官宣加入小米“人车家全生态”
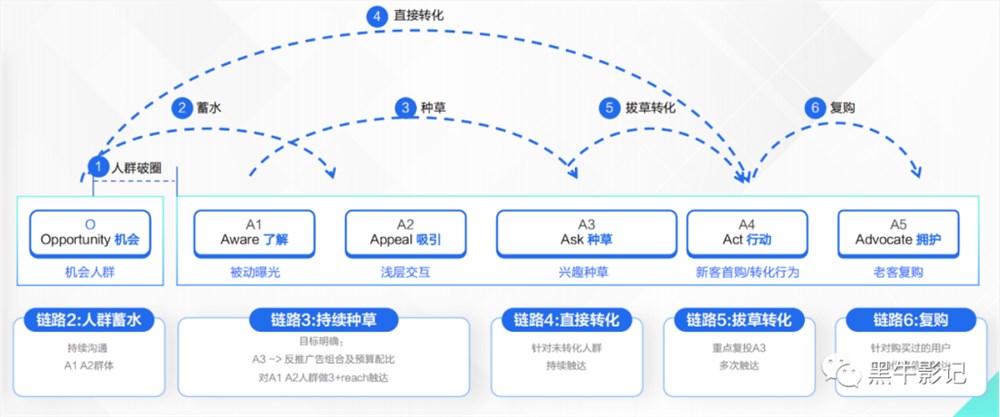
就在刚刚,小米官方宣布,小米汽车正式加入小米「人车家全生态」,同时,小米官方还发布了小米汽车官方海报。小米表示,13年来,小米一直在手机、智能设备领域深耕,现在,随着小米汽车的即将发布,小米「人车家全生态」也实现了真正闭环。据了解,小米汽车技术发布会将于12月28日下午2点举行。站长网2023-12-27 15:36:300000营销要为效果负责!短视频时代下的新内容营销方法论
一、以ROI评判内容的准确性“抖音电商,让我们首次看到了集曝光、种草和转化为一体的全链路新生态。”——美妆品牌XXX总监不可否认,抖音可以说是唯一万亿级集内容营销与销售转化为一体的全链路闭环交易平台。也是更务实的品效协同营销场域,而营销场的杠杆支点是“内容破圈,自带buff”,闭环链路平台的内容建设约等于品牌建设。站长网2023-05-16 11:50:410001