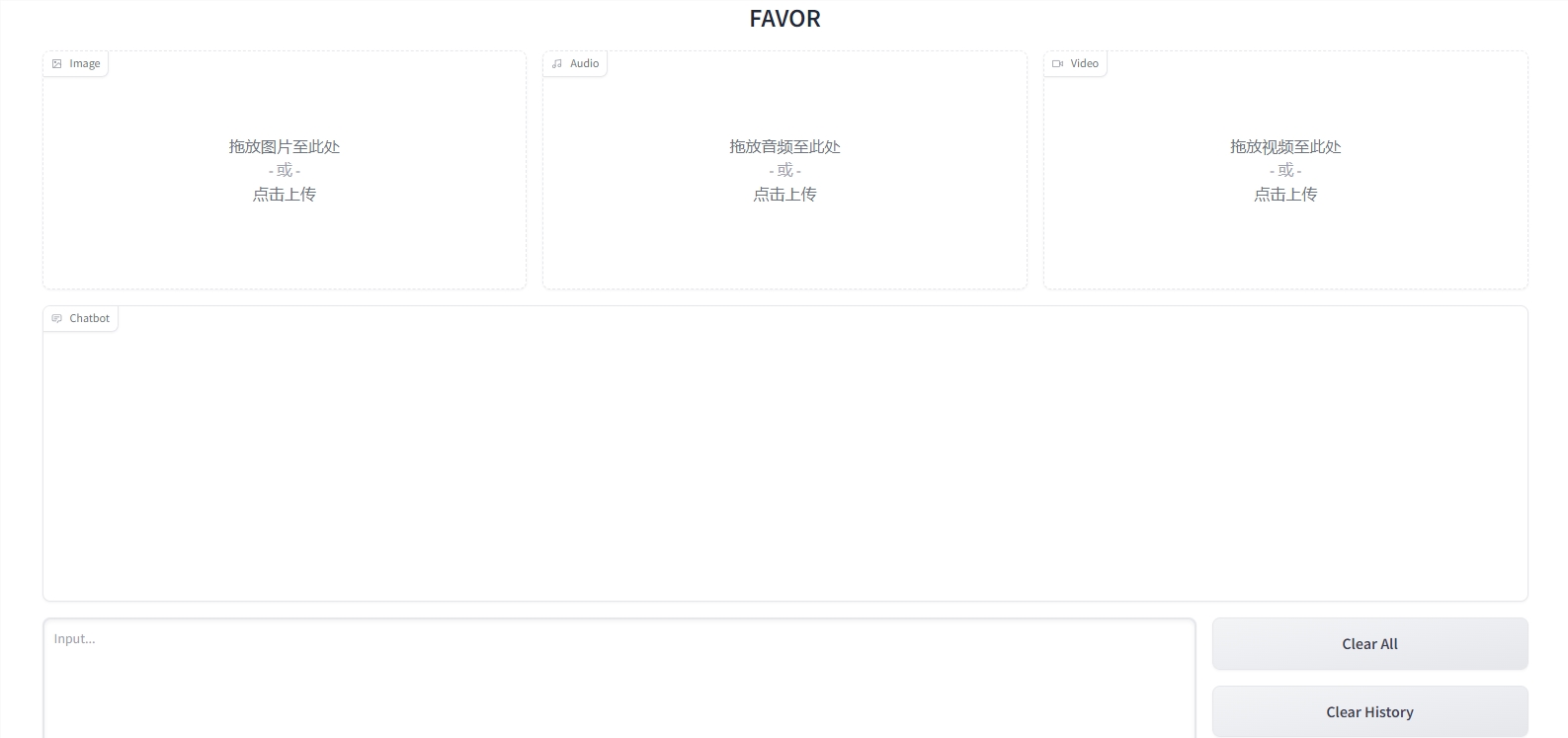
FAVOR:通过精细融合音频和视觉细节提升大模型视频理解能力
站长网2023-10-12 11:54:430阅
研究人员日前发布了一项名为"FAVOR"的创新技术,它能够在帧级别巧妙地融合音频和视觉细节,从而增强大型语言模型对视频内容的理解能力。
这一引入FAVOR方法的举措,为拓展大型语言模型在视频理解领域的潜力开辟了新的机遇。这一创新技术通过精细融合音频和视觉信息,显著提高了视频理解的准确性和效率,有望对人工智能视频理解技术的进步产生积极的影响。
项目地址:https://github.com/the-anonymous-bs/FAVOR
核心功能:
多模态支持: FAVOR支持多种输入模态,包括文本、图像、音频和视频。用户可以轻松结合这些不同的媒体类型,以更精确地表达他们的需求。
清除历史记录: FAVOR允许用户清除聊天历史,以确保他们的会话始终保持整洁。这有助于更好地组织对话,同时保留所有输入模态。
提交和重新提交: 用户可以通过点击"Submit"按钮来发送他们的请求,获取模型的响应。如果需要重新发送相同请求,可以使用"Resubmit"选项,同时清除上一轮的对话。
参数控制: FAVOR提供了控制生成文本的参数,包括最大长度、Top-P和温度。这使用户能够微调生成的文本,以满足他们的需求。
提供示例: 项目提供了论文中提到的示例,以帮助用户更好地了解如何使用FAVOR。这些示例可以作为起点,帮助用户开始构建他们自己的多模态交互。
0000
评论列表
共(0)条相关推荐
苹果iOS 18隐藏功能曝光!任何文本框中都可进行数学计算
快科技6月16日消息,苹果公司在2024年的全球开发者大会(WWDC)上推出了iOS18的开发者测试版,尽管官方已经展示了诸多新功能,但一些用户和开发者还是发现了一些未被广泛宣传的隐藏特性。近日,有用户发现,iOS18现在允许用户在任何文本框中直接进行数学计算,而无需打开计算器应用。站长网2024-06-17 04:50:130000云从科技推出行人基础大模型
近日,云从科技宣布推出云从行人基础大模型,该模型使用了超过20亿的数据,包括大量无标签数据集以及图文多模态数据集,数据集的丰富多样使得模型能够提取到非常稳健的特征,轻松应用于多种行人任务。站长网2023-07-19 12:29:500000清华系发布全新金融AI功夫量化 几秒完成金融数据分析
近日,国内AI创新企业功夫源科技推出了一款名为「功夫量化」的金融数据分析AI应用,标志着金融数据分析领域的一次重大突破。「功夫量化」AI应用能够在PB级金融数据中以秒级速度进行精准的信息搜寻,为普通投资者提供了一款无需编程即可轻松进行数据分析的金融工具。这款应用的核心竞争力在于其深度筛选数据的能力,能够洞悉背后的价值信息,并据此生成有力的洞见,帮助用户做出更明智的投资决策。站长网2024-04-22 15:38:530000阿里蔡崇信:微软与OpenAI的未来可能分道扬镳
快科技6月17日消息,据媒体报道,在摩根大通举办的第20届全球中国峰会上,阿里巴巴集团主席蔡崇信就AI与云计算的融合趋势发表了见解。蔡崇信表示,AI和云计算的紧密结合非常重要,因为任何使用AI技术服务的人都离不开强大的云计算能力的支持。他还表示:虽然微软与OpenAI建立了紧密的合作,但两者的独立地位意味着他们未来极有可能会分道扬镳。”站长网2024-06-17 16:13:150000华为再面向全球招募天才少年 旨在发掘优秀的青少年人才
华为招聘微信公众号显示,华为再次面向全球招募天才少年。旨在发掘全球优秀的青少年人才,培养未来科技领域的精英人才,为人类社会的进步与发展做出贡献。华为公司曾表示,参赛的天才少年将有机会获得来自华为公司的专业培训和指导,接触到最前沿的科技技术和应用,参与到华为公司的全球研发和创新项目中,同时还有机会获得丰厚的奖金和荣誉。站长网2023-05-19 09:56:580000