OpenAI科学家最新演讲:GPT-4即将超越拐点,1000倍性能必定涌现!
【新智元导读】GPT-4参数规模扩大1000倍,如何实现?OpenAI科学家最新演讲,从第一性原理出发,探讨了2023年大模型发展现状。
「GPT-4即将超越拐点,并且性能实现显著跳跃」。
这是OpenAI科学家Hyung Won Chung在近来的演讲中,对大模型参数规模扩大能力飙升得出的论断。
在他看来,我们所有人需要改变观点。LLM实则蕴藏着巨大的潜力,只有参数量达到一定规模时,能力就会浮现。

Hyung Won Chung将这次演讲题目定为「2023年的大型语言模型」,旨对LLM领域的发展做一个总结。
在这个领域中,真正重要的是什么?虽然「模型扩展」无疑是突出的,但其深远的意义却更为微妙和细腻。
在近一个小时的演讲中,Hyung Won Chung从三个方面分享了自己过去4年从业以来对「扩展」的思考。
都有哪些亮点?
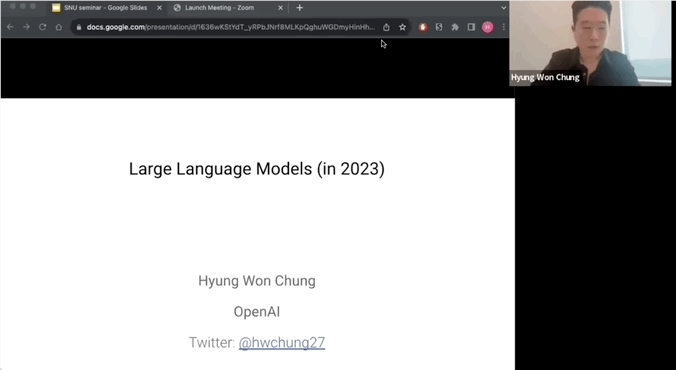
参数规模越大,LLM势必「涌现」
Hyung Won Chung强调的核心点是,「持续学习,更新认知,采取以“规模”为先的视角非常重要」。
因为只有在模型达到一定规模时,某些能力才会浮现。
多项研究表明,小模型无法解决一些任务,有时候还得需要依靠随机猜测,但当模型达到一定规模时,就一下子解决了,甚至有时表现非常出色。
因此,人们将这种现象称之为「涌现」。
即便当前一代LLM还无法展现出某些能力,我们也不应该轻言「它不行」。相反,我们应该思考「它还没行」。
一旦模型规模扩大,许多结论都会发生改变。
这促使许多研究人员能够以一个新的视角去看待这个问题,即推理思路的根本性转变,从「一些方法现在不起作用」,到「一些方法只是在当前不起作用」。
也就是,最新方法可能不适用于当前模型,但是3-5年后,可能变得有效。
有着新颖视角的AI新人,通常可以带做出有影响力研究。那是因为他们不受一种直觉和想法的束缚,即经验丰富的人可能已经尝试过但发现不成功的方法。
Hyung Won Chung表示,自己平时在实验过程中,会记录下失败的过程。每当有了新的模型,他就会再次运行实验,再来查验哪些是成功的,哪些是失败的,以此往复。
这样一来,就可以不断更新和纠正自我认知和理解,适应技术的日新月异。
目前,GPT-3和GPT-4之间的能力仍然存在显著差距,尝试去弥合与当前模型的差距可能是无效的。
那么,已经有了规模的发展性观点后,我们该如何扩大参数规模?
第一性原理看Transformer
迄今为止,所有大模型背后的架构都是基于Transformer搭建的。想必很多人已经对下图的样子熟记于心。

这里,Hyung Won Chung从第一性原理出发探讨Transformer的核心思想,并强调了Transformer内部架构细节并非关注重点。
他注意到,许多LLM的研究者不熟悉扩展的具体操作。因此,这部分内容主要是为那些想要理解大型模型训练含义的技术人员准备的。
从功能性角度来看,可以把Transformer看作带有矩阵乘法一种简洁的序列到序列的映射,并可以进行相应数组转换。

所以,扩大Transformer的规模就是,让很多很多机器高效地进行矩阵乘法。

通过将注意力机制拆分为单独的头,利用多台机器和芯片,并使用GSP MD方法进行无需通信的并行化。
然后借助Jax的前端工具PJ将阵列轴映射到硬件,可以实现大型语言模型的并行化。
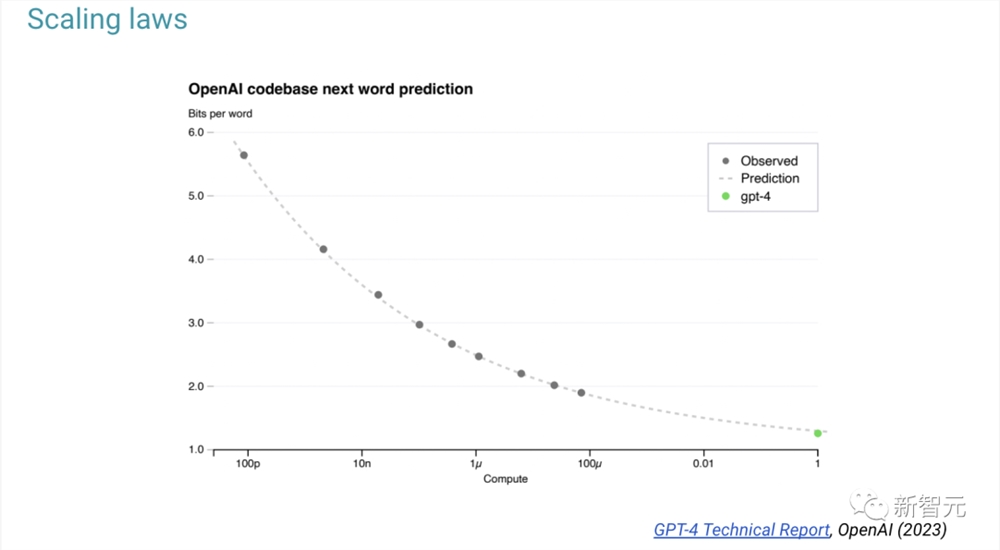
预训练模型的规模将跨越数量级,缩放法则是用小规模模型开发的。
1万倍GPT-4,让神经网络学习目标函数
再进一步扩展模型规模时,设想是GPT-4的10000倍,应该考虑什么?
对Hyung Won Chung来说,扩展不只是用更多的机器做同样的事情,更关键的是找到限制进一步扩展的「归纳偏差」(inductive bias)。
总之,扩展并不能解决所有问题,我们还需要在这大规模工程的工作中做更多研究,也就是在后训练中的工作。
你不能直接与预训练模型对话,但它会在提示后继续生成,而不是回答问题。即使提示是恶意的,也会继续生成。
模型后训练的阶段的步骤包括,指令调优——奖励模型训练——策略模型训练,这也就是我们常说的RLHF。

尽管RLHF有着一些弊端,比如奖励模型容易受到「奖励黑客」的影响,还有开放的研究问题需要解决,但是我们还是要继续研究RLHF。
因为,最大似然法归纳偏差太大;学习目标函数(奖励模型)以释放缩放中的归纳偏差,是一种不同的范式,有很大的改进空间。

另外,RLHF是一种有原则的算法 ,需要继续研究,直到成功为止。
总之,在Hyung Won Chung认为,最大似然估计目标函数,是实现GPT-410000倍规模的瓶颈。
使用富有表达力的神经网络学习目标函数,将是下一个更加可扩展的范式。随着计算成本的指数级下降,可扩展的方法终将胜出。
「不管怎么说,从第一原理出发理解核心思想是唯一可扩展的方法」。
参考资料:
https://twitter.com/xiaohuggg/status/1711714757802369456?s=20
https://twitter.com/dotey/status/1711504620025942243
https://docs.google.com/presentation/d/1636wKStYdT_yRPbJNrf8MLKpQghuWGDmyHinHhAKeXY/edit#slide=id.g27b7c310230_0_496
AI视野:小红书内测群聊AI对话功能;OpenAI中断开发新AI模型;B站现新型直播间“AI杠精”;AI会玩《精灵宝可梦》
🤖📱💼AI应用ChatGPT正式引入Bing网络搜索功能OpenAI宣布正式在ChatGPT引入了Bing搜索引擎功能,使其具备实时联网搜索功能,同时DALL-E3进入测试版。【AiBase提要】:🚀OpenAI正式引入Bing搜索引擎功能到ChatGPT,实现实时联网搜索,解除了过去的数据截止日期限制。站长网2023-10-19 15:22:420000谷歌要求 Android 应用更好地审查 AI 生成内容
划重点:1.🚫Android应用必须改进对AI生成内容的审查,提供用户举报方式。2.📢使用AI生成内容的应用必须在明年初前添加报告不良内容的按钮。3.🔒Google将限制应用程序对用户照片和视频的访问权限,以保护用户隐私。站长网2023-10-26 10:18:460001文心一言用户规模达4500万 插件超过500个
在昨天的百度世界2023大会上,文心大模型4.0正式发布,开启邀请测试据官方介绍,文心大模型4.0在9月已开始小流量上线,过去一个多月效果又提升了近30%。据称,文心大模型4.0的理解、生成、逻辑、记忆四大能力都有显著提升,其中理解和生成能力的提升幅度相近,而逻辑和记忆能力的提升则更大,逻辑的提升幅度达到理解的近3倍,记忆的提升幅度也达到了理解的2倍多。站长网2023-10-18 23:19:320000Stability AI 推出商业版会员计划,对AI模型的商业使用收费
划重点:-📌StabilityAI推出商业版会员计划,针对AI模型的商业使用收费。-📌会员计划分为免费、月费20美元和企业版三个层级。-📌StabilityAI希望通过收费会员计划为未来的研发提供资金支持。站长网2023-12-20 09:48:280000OpenAI发布实时API公测版 3家语音API合作者揭晓
近日,OpenAI发布了其实时API公开测试版,为开发者提供了构建基于GPT-4大型语言模型的高交互性AI应用程序的机会。该API允许开发者在应用程序中创建低延迟、多模态的实时交互体验,为AI应用领域带来了一次重大革新。0000












