DistilBERT:更小、更快、更便宜的大型语言模型压缩方法
站长网2023-10-08 09:56:450阅
要点:
1. 近年来,大型语言模型的发展迅猛,BERT成为其中最受欢迎和高效的模型,但其复杂性和可扩展性成为问题。
2. 为了解决这个问题,采用了知识蒸馏、量化和修剪等压缩算法,其中知识蒸馏是主要的方法,通过让较小的模型模仿较大模型的行为来实现模型压缩。
3. DistilBERT是从BERT中学习并通过包括掩码语言建模损失、蒸馏损失和相似性损失在内的三个组件更新权重,它比BERT小、快、便宜,但性能仍然相当。
近年来,大型语言模型的发展迅猛,BERT成为其中最受欢迎和高效的模型,但其复杂性和可扩展性成为问题。为了解决这些问题,市面上目前由三种常见的模型压缩技术:知识蒸馏、量化和剪枝。
知识蒸馏的目标是创建一个较小的模型,可以模仿较大模型的行为。为了实现这一目标,需要一个已经预训练好的大型模型(如BERT),然后选择一个较小模型的架构,并使用一个适当的损失函数来帮助较小模型学习。这里大模型被称为“教师”,较小模型被称为“学生”。知识蒸馏通常在预训练过程中应用,但也可以在微调过程中应用。
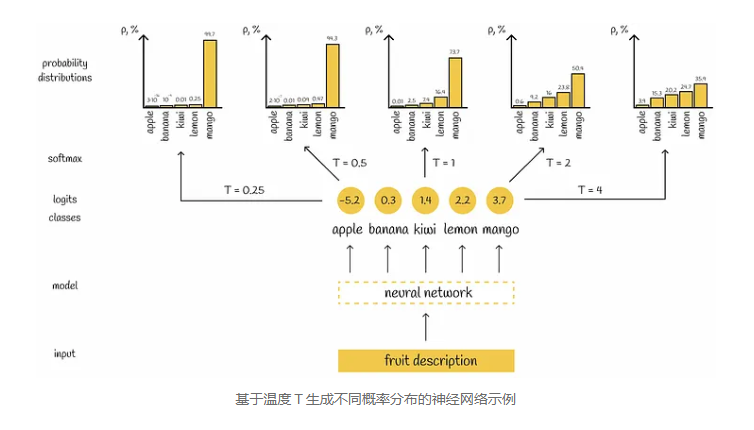
DistilBERT从BERT学习,并通过包括掩码语言建模(MLM)损失、蒸馏损失和相似性损失在内的三个组件的损失函数来更新其权重。文章解释了这些损失组件的必要性,并引入了softmax温度的概念,用于在DistilBERT损失函数中平衡概率分布。
DistilBERT的体系结构,包括与BERT相似但有一些差异的地方,以及在性能优化方面采用的一些最佳实践。最后,文章总结了BERT和DistilBERT在性能和规模方面的比较,指出DistilBERT在保持可比性能的同时,更小更快。
总之,DistilBERT通过知识蒸馏技术在保持性能的同时显著压缩了大型语言模型,为在资源受限设备上的部署提供了可能性。
0000
评论列表
共(0)条相关推荐
普华永道宣布对生成式 AI 进行重大投资 与微软和 ChatGPT 母公司 OpenAI 合作
普华永道会计师事务所(PwC)公布了在未来三年内为其美国业务投资10亿美元用于生成式人工智能(AI)技术的计划。普华永道与微软公司和ChatGPT的制造商OpenAI合作,旨在实现其税务、审计和咨询服务方面的自动化。这家会计和咨询巨头表示,周三宣布的的多年投资将包括资助聘请更多AI专业人员,培训现有员工的AI能力,以及针对AI软件制造商进行潜在收购。站长网2023-04-27 08:58:580003新茶饮迎来“报复性扩张”,海内外共赴万店目标?
新茶饮品牌的圈地运动再次被提上了日程。去年亏掉4.61亿元的奈雪的茶计划在2023年开店600家,营销“翻车”的沪上阿姨开始酝酿开万店的目标,就连一向“佛系”的茶颜悦色也发力在外省连开多店。经历了疫情期间的低调求生存之后,眼下看来已经到了新一轮的扩张期,品牌们既要在一二线城市站稳脚跟,还要到下沉市场去挖掘更多商机,更要重新拾起曾被搁置的出海计划。站长网2023-04-17 17:58:070000国产之光DeepSeek把AI大佬全炸出来了!671B大模型训练只需此前算力1/10,细节全公开
DeepSeek新版模型正式发布,技术大佬们都转疯了!延续便宜大碗特点的基础之上,DeepSeekV3发布即完全开源,直接用了53页论文把训练细节和盘托出的那种。怎么说呢,QLoRA一作的一个词评价就是:优雅。具体来说,DeepSeekV3是一个参数量为671B的MoE模型,激活37B,在14.8T高质量token上进行了预训练。0000理想汽车回应再遭王兴减持:个人行为 不涉及美团持股部分
香港联交所最新权益披露显示,美团的创始人、董事及控股股东王兴,近期对理想汽车的股票进行了再次减持。根据披露资料,王兴在3月26日至28日的短短三日内,分别出售了理想汽车95万股、141.39万股及179.84万股的普通股,总计减持了416.23万股。站长网2024-04-18 14:27:17000210万人围观竞拍,82年雪碧如何用老梗在抖音玩出新增长?
来瓶82年的雪碧不再是玩笑。曾经的网络热梗“1982年的雪碧”,被官方玩梗致敬,成为了⌈雪碧致敬1982⌋;抖音网友的DIY版“1982雪碧礼盒”开箱热潮,也成为了雪碧与抖音电商超级品牌日的灵感来源,创新推出了「雪碧致敬1982」抖音电商超级品牌日限定木桶礼盒。站长网2023-07-13 08:59:580000











