ICCV'23论文颁奖“神仙打架”!Meta分割一切和ControlNet共同入选,还有一篇让评委们很惊讶
刚刚,计算机视觉巅峰大会ICCV2023,在法国巴黎正式“开奖”!
今年的最佳论文奖,简直是“神仙打架”。
例如,获得最佳论文奖的两篇论文中,就包括颠覆文生图AI领域的著作——ControlNet。
自开源以来,ControlNet已经在GitHub上揽获24k星。无论是对扩散模型、还是对整个计算机视觉领域而言,这篇论文获奖都可以说是实至名归。
而最佳论文奖荣誉提名,则颁给了另一篇同样出名的论文,Meta的「分割一切」模型SAM。
自推出以来,「分割一切」已经成为了各种图像分割AI模型的“标杆”,包括后来居上的不少FastSAM、LISA、SegGPT,全部都是以它为参考基准进行效果测试。
论文提名都如此重量级,这届ICCV2023竞争有多激烈?
整体来看,ICCV2023一共提交了8068篇论文,其中只有约四分之一、即2160篇论文被录用。
其中近10%的论文来自中国,除了高校以外也有不少产业机构的身影,像商汤科技及联合实验室有49篇论文入选ICCV2023,旷视有14篇论文入选。
一起来看看这一届ICCV2023的获奖论文都有哪些。
ControlNet获ICCV最佳论文
首先来看看今年获得最佳论文奖(马尔奖)的两篇论文。
ICCV最佳论文又名马尔奖(Marr Prize),每两年评选一次,被誉为计算机视觉领域的最高荣誉之一。
这一奖项因计算机视觉之父、计算机视觉先驱、计算神经科学的创始人David Courtnay Marr(大卫·马尔)而得名。
第一篇最佳论文奖「Adding Conditional Control to Text-to-Image Diffusion Models」,来自斯坦福。

这篇论文提出了一种名叫ControlNet的模型,只需给预训练扩散模型增加一个额外的输入,就能控制它生成的细节。
这里的输入可以是各种类型,包括草图、边缘图像、语义分割图像、人体关键点特征、霍夫变换检测直线、深度图、人体骨骼等,所谓的“AI会画手”了,核心技术正是来自于这篇文章。

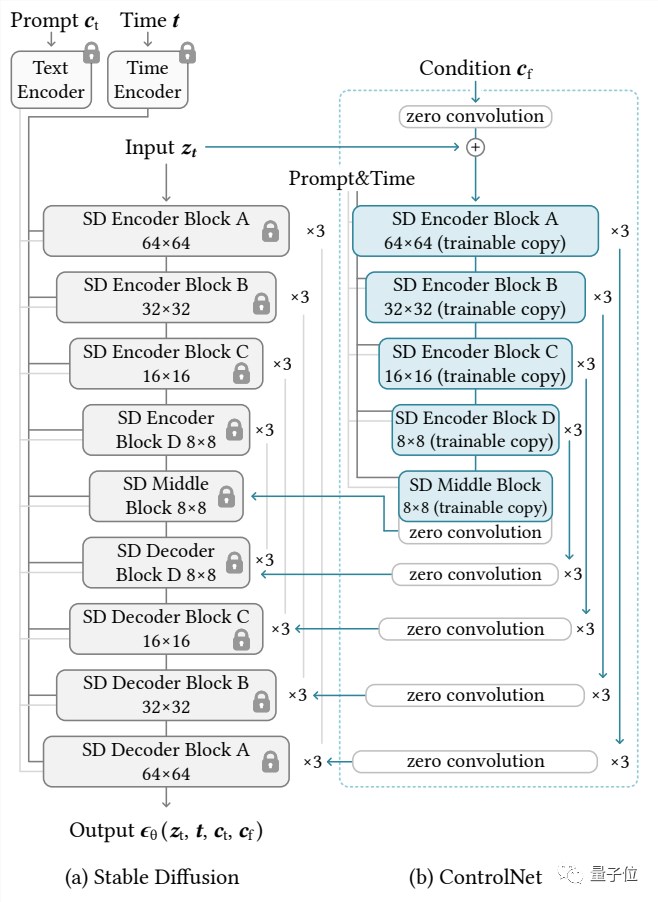
它的思路和架构如下:
ControlNet先复制一遍扩散模型的权重,得到一个“可训练副本”(trainable copy)。
相比之下,原扩散模型经过几十亿张图片的预训练,因此参数是被“锁定”的。而这个“可训练副本”只需要在特定任务的小数据集上训练,就能学会条件控制。
即使数据量很少(不超过5万张图片),模型经过训练后条件控制生成的效果也很好。
“锁定模型”和“可训练副本”通过一个1×1的卷积层连接,名叫“0卷积层”。0卷积层的权重和偏置初始化为0,这样在训练时速度会非常快,接近微调扩散模型的速度,甚至在个人设备上训练也可以。
例如一块英伟达RTX3090TI,用20万张图像数据训练的话只需要不到一个星期。
ControlNet论文的第一作者Lvmin Zhang,目前是斯坦福博士生,除了ControlNet以外,包括Style2Paints、以及Fooocus等著名作品也出自他之手。
论文地址:
https://arxiv.org/abs/2302.05543
第二篇论文「Passive Ultra-Wideband Single-Photon lmaging」,来自多伦多大学。
这篇论文被评选委员会称之为“在主题(topic)上最令人惊讶的论文”,以至于其中一位评委表示“他几乎不可能想到去尝试这样的事情”。

论文的摘要如下:
这篇文章讨论了如何同时在极端时间尺度范围内(从秒到皮秒)对动态场景进行成像,同时要求成像passively(无需主动发送大量光信号)并在光线非常稀少的情况下进行,而且不依赖于来自光源的任何定时信号。
由于现有的单光子相机的光流估计技术在这个范围内失效,因此,这篇论文开发了一种光流探测理论,借鉴了随机微积分的思想,以从单调递增的光子检测时间戳流中重建像素的时间变化光流。
基于这一理论,论文主要做了三件事:
(1)表明在低光流条件下,被动自由运行的单光子波长探测器相机具有可达到的频率带宽,跨越从直流到31GHz范围的整个频谱;
(2)推导出一种新颖的傅立叶域光流重建算法,用于扫描时间戳数据中具有统计学显著支持的频率;
(3)确保算法的噪声模型即使在非常低的光子计数或非可忽略的死区时间(dead times)情况下仍然有效。
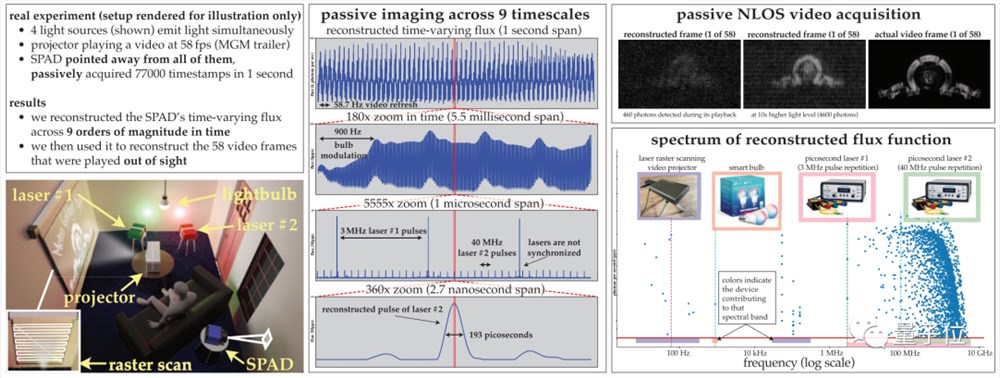
作者通过实验证明了这种异步成像方式的潜力,包括一些前所未见的能力:
(1)在没有同步(如灯泡、投影仪、多脉冲激光器)的情况下,对以不同速度运行的光源同时照明的场景进行成像;
(2)被动的非视域(non-line-of-sight)视频采集;
(3)记录超宽带视频,可以在30Hz的频率下回放,展示日常运动,但也可以以每秒十亿分之一的速度播放,以展示光的传播过程。
论文一作Mian Wei,多伦多大学博士生,研究方向是计算摄影,目前的研究兴趣在于基于主动照明成像技术改进计算机视觉算法。
论文地址:
https://openaccess.thecvf.com/content/ICCV2023/papers/Wei_Passive_Ultra-Wideband_Single-Photon_Imaging_ICCV_2023_paper.pdf
「分割一切」获荣誉提名
除了备受关注的ControNet之外,红极一时的Meta「分割一切」模型获得了此次大会的最佳论文奖荣誉提名。

这篇论文不仅提出了一个当前最大的图像分割数据集,在11M图像上拥有超过10亿个遮罩(mask),而且为此训练出了一个SAM模型,可以快速分割没见过的图像。
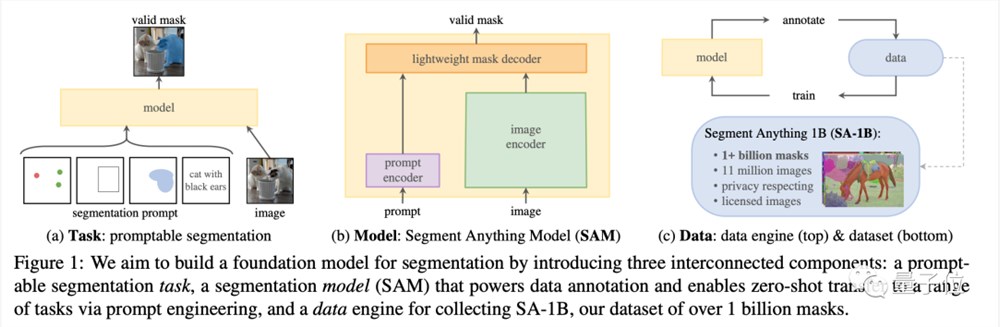
相比于之前比较零散的图像分割模型,SAM可以说是对这一系列模型功能进行了“大一统”,而且在各项任务中都表现出了不错的性能。
目前,这一开源模型已经在GitHub上揽获38.8k星,可以说是语义分割工业界的「标杆」了。
论文地址:https://arxiv.org/abs/2304.02643
项目主页:https://segment-anything.com/
而在学生作品当中,Google提出的「追踪一切」模型脱颖而出。
就像文章的标题一样,这个模型可以在任何地点同时对图像中的任意(多个)物体进行像素级追踪。
该项目的第一作者是康奈尔大学的华人博士Qianqian Wang,目前正在UCB进行博士后研究。

论文地址:https://arxiv.org/abs/2306.05422
项目主页:https://omnimotion.github.io/
此外,开幕式上还公布了由PAMITC委员会成员捐助的特别奖项,该委员会同时也捐助CVPR和WACV两个计算机视觉领域会议的奖项。
这些奖项包括以下四个:
亥姆赫兹奖:十年前对计算机视觉研究产生重大影响的ICCV论文
Everingham奖:计算机视觉领域的进步
杰出研究者:对计算机视觉的进步做出重大贡献的研究人员
Rosenfeld终身成就奖:在长期职业生涯中对计算机视觉领域做出重大贡献的研究人员

其中获得亥姆赫兹奖的是Meta AI的华裔科学家Heng Wang和Google的Cordelia Schmid。
他们凭借2013年发表的一篇有关动作识别的论文获得了这一奖项。
当时两人都在法国国立计算机及自动化研究院(法语缩写:INRIA)下属的Lear实验室工作,Schmid是当时该实验室的领导者。
论文地址:https://ieeexplore.ieee.org/document/6751553
Everingham奖则颁发给了两个团队。
第一组获得者是来自Google的Samer Agarwal、Keir Mierle和他们的团队。
两位获奖者分别毕业于华盛顿大学和多伦多大学,获奖的成果是计算机视觉领域广泛使用的开源C 库Ceres Solver。

项目主页:https://ceres-solver.org/
另一项获奖成果是COCO数据集,它包含了大量的图像和注释,有丰富的内容和任务,是测试计算机视觉模型的重要数据集。
该数据集由微软提出,相关论文第一作者是华裔科学家Tsung-Yi Lin,博士毕业于康奈尔大学,现在英伟达实验室担任研究人员。


论文地址:https://arxiv.org/abs/1405.0312
项目主页:https://cocodataset.org/
获得杰出研究者荣誉的则是德国马普所的Michael Black和约翰森霍普金斯大学的Rama Chellappa两位教授。
来自MIT的Ted Adelson教授则获得了终身成就奖。
你的论文被ICCV2023录用了吗?感觉今年的奖项评选如何?
老黄:元宇宙是个江湖
互联网江湖已经沉寂了很多年。2021年,耐不住寂寞的扎克伯格,突然宣称打通了任督二脉,在门派中特设元宇宙堂口,名“Meta”,一副拳打南山猛虎、脚踢北海蛟龙的气概,誓要在江湖卷起滔天巨浪。扎大佬“嗷”的一嗓子往前冲,其他大佬面面相觑后,只好撒丫子跟着跑。后世史载,2021年为元宇宙元年。站长网2023-04-14 14:58:320000AI 燃起网络犯罪烈火!ChatGPT恶意钓鱼邮件激增了1265%
根据SlashNext发布的“2023年钓鱼报告”,自2022年第四季度以来,恶意钓鱼邮件激增了1265%,这标志着由生成式人工智能(AI)推动的网络犯罪新时代的到来。图源备注:图片由AI生成,图片授权服务商Midjourney站长网2023-10-31 10:12:540000研究:AI模型仍不擅长生成干净代码 GPT-4的API误用率达62%
文章概要:1.AI模型在回答Java编码问题时,仍存在许多API误用问题。GPT-3.5和GPT-4的API误用率分别达到49.83%和62.09%。2.Llama2API误用率最低,但由于它生成的代码较少,误导性很大。一旦生成更多代码,其误用率也大幅上升。3.添加相关API使用示例能稍微改善结果,但仍有改进空间。代码的可靠性和稳健性仍是难题。站长网2023-08-30 16:43:280000宁德时代发布凝聚态电池 能量密度达500Wh/kg
今天,宁德时代正式发布了全新的凝聚态电池,单体能量密度高达500Wh/kg,达航空级电池级别。宁德时代首席科学家吴凯表示,宁德时代正在进行民用电动载人飞机项目的合作开发,执行航空级的标准与测试,满足航空级的安全与质量要求。除了能量密度高、安全性好之外,凝聚态电池还具备快速充电可靠性强、循环寿命长等特点,可以在数分钟内完成充电。据悉,凝聚态电池将在今年内具备量产能力。站长网2023-04-19 11:12:370000iPhone 17标准版或将配备ProMotion高刷屏
iPhone标准版和Pro系列的主要区别在于屏幕刷新率。Pro系列使用ProMotion技术,能达到120Hz的最高刷新率。这一差异化特点促使许多用户选择购买Pro系列。然而,这一局面可能即将发生改变。站长网2023-10-19 10:47:580000












