Chinchilla之死:只要训练足够长时间,小模型也能超过大模型
2022年3月,DeepMind 一篇论文《Training Compute-Optimal Large Language Models》通过构建的 Chinchilla 模型得出了一个结论:大模型存在训练不足的缺陷,模型大小和训练 token 的数量应该以相等的比例扩展。也就是说模型越大,所使用的训练 token 也应该越多。
但事实可能并非如此,近日,博主 Thaddée Yann TYL 写了一篇题为《Chinchilla 之死》的文章,其中分析解读了 OpenAI 与 DeepMind 几篇论文中的细节,得到了一个出人意料的结论:如果有充足的计算资源和数据,训练足够长时间,小模型的表现也可以超越大模型。
多算胜,少算不胜。——《孙子兵法》
为了避免将算力浪费于缓慢的收敛过程中,进行外推是非常重要的。毕竟,如果你不得不步行去珠穆朗玛峰,你不会只靠眼睛辨别方向,而是会使用 GPS。
但有时候,你又不得不把视线从 GPS 上移开,看看道路。有些东西是无法通过简单的公式推断出来的。对十九世纪的物理学家来说,紫外灾变( Ultraviolet catastrophe)便是如此;而现在,LLM 亦是如此。我们估计在中心位置附近有效的东西可能在远处会出现巨大的偏差……

Chinchilla 到底是什么?
更小的模型执行的乘法更少,因而训练得也更快。但是,按照理论,更小的模型最终会触及自身知识容量的极限,并且学习速度会变慢;而有更大知识容量的大型模型在经过给定的训练时间后会超过小模型,取得更好的性能表现。
在评估如何在训练期间获得最佳性价比时,OpenAI 和 DeepMind 都会试图绘制帕累托边界(Pareto frontier)。虽然他们没有明确说明他们使用了该理论来绘制,但 OpenAI 曾说过的一句话暗示存在这个隐藏假设:
我们预计更大模型的表现应当总是优于更小的模型…… 大小固定的模型的能力是有限的。
这一假设是他们计算帕累托边界的基石。在 Chinchilla 研究中,图2展示了不同大小的模型经过大量训练时的训练损失变化情况。初看之下,这些曲线与理论相符:更小的模型一开始的损失更低(表现更好),但损失降低的速度最终变慢并被更大模型的曲线超越。

比较许多不同模型大小的损失曲线的 Chinchilla 图。
在这幅图中,每当更小的模型输给一个更大的模型时,他们就会标记一个灰点。这些点连成的灰线便是帕累托边界,这是他们计算缩放定律(scaling laws)的方式。
这一假设有个问题:我们不知道如果让更小的模型训练更长时间会发生什么,因为他们在小模型被超越时就不再继续训练它们了。
接下来在看看 Llama 论文。
Chinchilla 会有 Llama 的视野吗?
今年初,Meta 训练了四个不同大小的模型。不同于其它研究,其中每个模型都被训练了非常长时间,较小的模型也一样。
他们公布了所得到的训练曲线:

四个不同大小的 Llama 模型的训练损失曲线
1. 每条曲线首先按照幂律大幅下降。
2. 然后损失开始近乎线性地下降(对应于一个相当恒定的知识获取率)。
3. 在这条曲线的最右端,直线趋势被稍微打破,因为它们稍微变更平缓了一些。
首先,对于曲线末端的变平情况,这里解释一下人们可能有的一个微妙的误解。这些模型都是通过梯度下降训练的并且使用了可变的学习率(大致来说,这个超参数定义了每次朝梯度方向前进的程度)。为了获得优良的训练效果,学习率必须不断降低,这样模型才能检测到源材料中更细微的模式。他们用于降低学习率的公式是最常用的余弦调度(cosine schedule)。

在余弦调度下,学习率与训练步数的函数关系:学习率首先线性增长,然后下降且下降速度变快,之后到达中途一个转折点,下降速度再减慢。
从这张图中可以看到,在训练结束时,余弦调度会停止降低学习率,此时已经得到一个很好的近乎线性的训练损失曲线。学习速度减慢就是这种做法造成的。模型并不一定不再具有以同样近乎线性的速率学习的能力!事实上,如果我们能为其提供更多文本,我们就能延长其余弦调度,这样其学习率就会继续以同样速率下降。
模型的适应度图景并不取决于我们供给它训练的数据量;所以学习率下降趋势的改变是没有道理的。
不过这并非本文的重点。
训练损失曲线可能在另一方向上也存在误导性。当然,它们训练使用的数据是一样的,但它们处理这些数据的速度不同。我们想知道的并不是模型的样本效率如何(在这方面,更大的模型显然可以从其所见数据中学到更多)。让我们想象一场比赛:所有这些模型同时开始起步,我们想知道哪个模型首先冲过终点线。换句话说,当在训练时间投入固定量的算力时,哪个模型能在那段时间内学到更多?
幸好我们可以把这些损失曲线与 Meta 提供的另一些数据组合起来看:每个模型训练所用的时间。
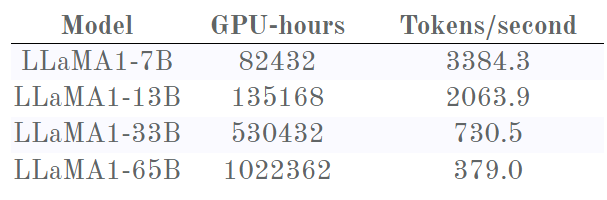

先来谈谈上面我们看过的那张 Chinchilla 图,其仅占这张图左侧的一小部分。在这一小部分,可以看到 Chinchilla 记录的相同行为。以7B 版本为例:其损失的下降速度一开始比更大的模型快得多,然后减慢;之后13B 版本模型超过了它,率先到达1.9。
然后,抵达边境之地,意外的转折出现了:7B 版本进入了近乎线性的疆域,损失稳步下降,看起来似乎走上了反超13B 版本之路?如果能训练7B 版本更长时间,说不好会发生什么。
但是,13B 和33B 版本之间似乎也有类似的现象,其中13B 版本起初的 Chinchilla 减慢也使其呈现出近乎线性的趋势,这时候13B 版本的损失下降速度似乎很快!33B 其实胜之不武,因为它超越13B 版本时已经用去了超过两倍的计算时间。
33B 和65B 版本之间也有同样的先减速再加速的现象,以至于33B 实际上从未被65B 超越。这幅图的内容击破了 OpenAI 和 Chinchilla 的假设:更大的模型并未取得胜利(至少说还没有)。他们检测到的这种减速实际上并不是由于达到了某个能力极限!
尽管如此,7B 模型的线还是有点不尽如人意。如果 Meta 能训练更长时间就好了……
不卖关子了:他们训练了!他们发布了 Llama2!
是时候证实我们的怀疑了

四个不同大小的 Llama2模型的训练损失曲线
同样,可以得到训练时间:
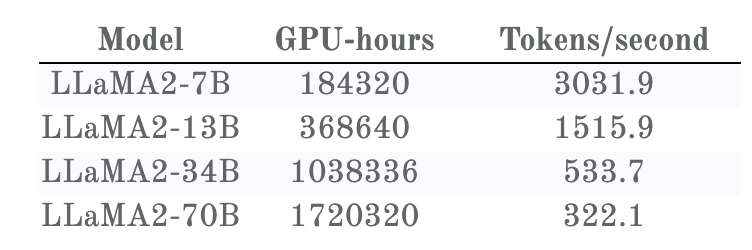
Llama2训练损失与所耗费的 GPU 时间
一眼便能看出,这里的训练损失曲线与 Llama1的不一样,即便这些基础模型是一样的。事实证明, Llama2的训练使用了双倍上下文大小和更长的余弦调度 —— 不幸的是,这会对所有模型大小产生负面影响。但是,更小的模型受到的影响比更大的模型更严重。由此造成的结果是:在 Llama1的训练时间,33B 模型总是优于65B 模型;而在 Llama2的训练时间,34B 模型则在重新超过70B 模型之前要略逊一筹。
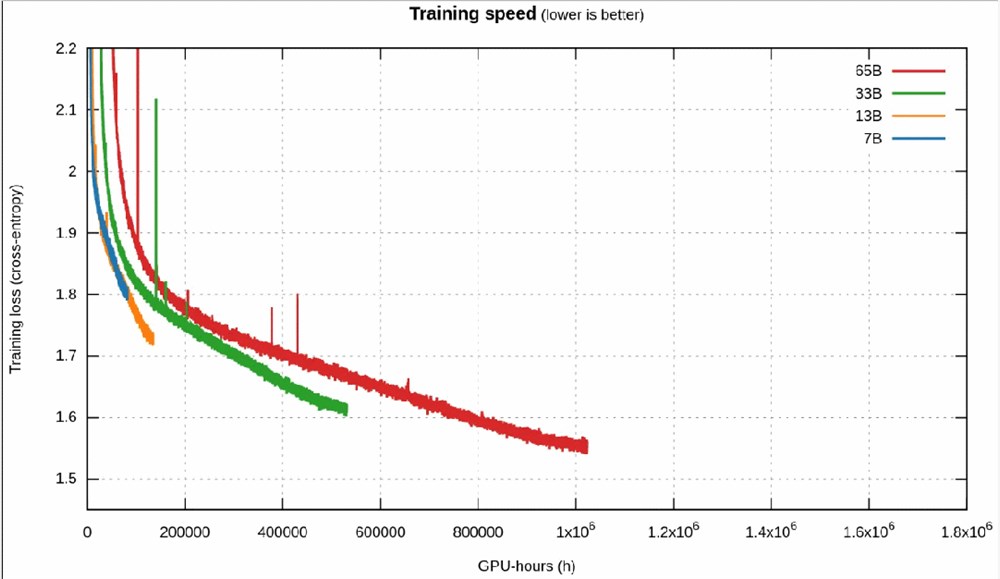
更重要的是,对训练速度的比较强烈地佐证了之前对 Llama1的猜想:
1. 一开始时,更小的模型快于更大的模型。
2. 然后,更小的模型速度变慢,并被更大的模型超越(按照 Chinchilla)。
3. 但再然后,模型进入近乎线性的区域,这时候更小的模型能更快地下降,获取更优的知识,它们再次超越更大的模型。
这就带来了一个有关训练方法的结论:与普遍的看法相反,更大的模型会产生更差的结果。如果你必须选择一个参数大小和数据集,你可能最好选择7B 模型,然后在数万亿 token 上训练7epoch。
请看看7B 模型近乎线性的区域,然后将其模式外推给70B 模型,看看70B 模型训练停止时的情况:如果将70B 模型的训练资源花在7B 模型上,可能会达到更低的困惑度!
从 Llama2的曲线还能看到另一点:Llama1曲线末端的学习减速实际上是余弦调度造成的。在 Llama2的训练中,在对应于1万亿 token 读取数的位置,就完全没有这种减速。
事实上,原因可能是这样的:在同一位置, Llama27B 模型的质量低于 Llama17B 模型,可能是因为其余弦调度被拉长了!
现在我们回到那篇 Chinchilla 论文来论证这一点。在该论文的附录 A 的图 A1中,他们给出了一个不同余弦调度参数的消融实验,换句话说就是对学习率曲线使用不同的延展方式。
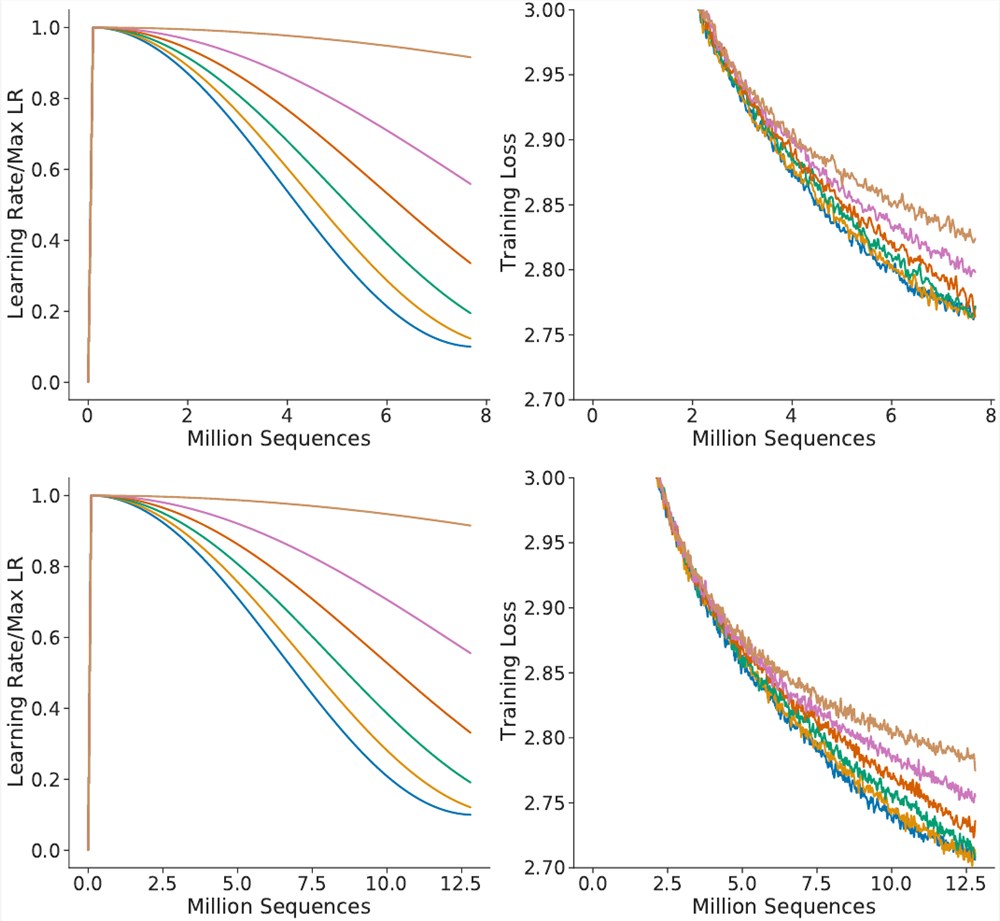
Chinchilla 余弦调度消融研究
他们指出,当学习率曲线没有延展时,能实现最低的损失。这得到了图表的支持,但其中也有不对劲的地方。在读取了600万 token 后,上图模型的训练损失低于2.8;与此同时,在相同的位置,下图模型的训练损失还更好。然而这两个模型的差异仅仅是余弦调度!由于下图模型注定会处理更多训练数据,所以就计算了「未拉伸的」余弦调度更多步骤,这实际上产生了拉伸效果。如果学习率遵循分配给更少训练步骤的余弦调度,其在同等训练时间下的损失会更低。
更广泛地说,这会引出一个有待解答的问题:如果余弦调度不是最优的,那么曲线的尾部形状应该是什么样子?
原文链接:
https://espadrine.github.io/blog/posts/chinchilla-s-death.html
把热爱当成事业,这位头部生活博主是如何炼成的?
年轻人怎么利用视频号创业或者增加收入?《2023数字生态就业创业发展报告》显示,视频号诞生的这三年多以来,已经催生了就业收入机会1894万个。这其中大多数是年轻人,他们有的是全职做,也有的兼职玩,不同的人有不同的入局方式。在【明析视频号】专栏的第二个专题里,我们采访了三位取得结果的年轻博主。站长网2023-07-12 15:39:560000抵制AI剽窃 各行业艺术家共同制定AI使用策略
近日,数字版权组织“为未来而战”与音乐行业劳工组织“联合音乐家和联合工人”合作,发起了AIdayofaction运动,呼吁国会通过立法,阻止企业获得人工智能音乐及其他艺术作品的版权。这一倡议旨在通过禁止唱片公司等利用AI创作音乐进行版权保护,迫使它们继续让人类参与创作。类似的担忧也存在于其他创意产业。站长网2023-10-09 11:48:320000“模特不能太漂亮”,这家新店卖基础款服装年销千万
因为一条简单的“种草”文章,“00后”茹茹爱上了“90年代通勤穿搭”。在一场复古走秀里,模特穿着基础款服装——紧身打底衫、包裙、休闲衬衣、配上珍珠项链,没有繁复的修饰,但她举手投足间就展现出慵懒又精致的气质。茹茹花了将近1000元买了一件马甲和一件衬衫,“不算有性价比,但是能接受,虽然我穿不出模特的那种效果,但也喜欢上了这种风格”。0000“离谱的AI扩图”火了!张张那叫一个出其不意
家人们,真的是要被抖音AI扩图给笑死了——主打一个看完让人“意想不到”、“一肚子气”~例如一对恩爱情侣的照片在AI扩图前是非常有信仰感的:△素材来源:抖音@快乐野人但在AI扩图一通“神操作”之下,画风简直是180度大反转:网友们在看过之后哭笑不得,打趣称“更虔诚”、“太励志”了😂。原本许多小伙伴们是想着用它来扩大原照片,但AI扩图给出的结果却主打一个离谱。站长网2023-12-06 09:16:090000遭 ChatGPT “诽谤”挪用资金,男子起诉 OpenAI
来自佐治亚州的一位名叫Walters的电台主持人起诉OpenAI,因为该公司的ChatGPT服务竟告诉一名记者马克沃尔特斯挪用了枪支权利非营利组织第二修正案基金会(SAF)的资金。据报道,Walters本周早些时候提起了可能是首例诽谤诉讼,指控ChatGPT损害了他的声誉,并提出索赔。站长网2023-06-09 23:45:290005











