FC-CLIP彻底改变全景分割:统一的单级AI 框架
要点:
1、全景分割将语义分割和实例分割相结合,对图像进行精细分割标注,但受限于数据集标注成本。
2、FC-CLIP通过冻结卷积CLIPbackbone实现掩码生成和CLIP文本对齐分类的单阶段统一,突破闭词汇限制。
3、FC-CLIP设计简单高效,参数和计算量都大大减少,性能显著提升,可扩展到开放词汇场景。
全景分割是将图像分割成有意义的部分或区域的基础计算机视觉任务,对各种应用如医学图像分析和自动驾驶具有关键作用。全景分割将语义分割的对每个像素进行对象分类,和实例分割的对同类不同实例进行区分相结合,目标是为每个实例生成不重叠的掩码并赋予类别标签。
多年来,研究者不断提升全景分割模型性能,重点关注全景质量指标。但是基于闭词汇的限制严重制约了这些模型的实际应用,因为数据集细颗粒度标注的高成本限制了语义类别数目。这成为全景分割应用的关键难题。

项目地址:https://github.com/bytedance/fc-clip
计算机视觉社区探索开放词汇分割来克服闭词汇的限制。这种范式利用单词的文本嵌入作为类别标签嵌入,大大增强了模型处理更广泛类别的能力。CLIP等多模态预训练模型利用其从海量互联网数据中学习对齐图像文本特征表示的能力,在开放词汇分割中显示出巨大潜力。
近期的两阶段方法如SimBaseline和OVSeg改编了CLIP进行开放词汇分割,但固有的低效和分割与分类不一致的问题仍然存在。提出单阶段统一框架FC-CLIP正是为解决这一关键问题。
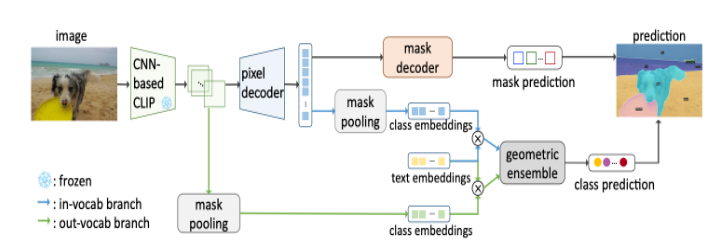
FC-CLIP在共享的冻结卷积CLIP backbone上无缝集成了掩码生成和CLIP分类。这种设计基于以下核心思路:
冻结的CLIP backbone保留了预训练的图像文本对齐,支持开放词汇分类。
添加轻量级解码器后,CLIP backbone可作为强大的掩码生成器。
卷积CLIP在输入尺寸放大时泛化能力提升,适合密集预测任务。
单一冻结卷积CLIP backbone带来极简但高效的设计。相较先前方法,FC-CLIP参数和计算量大幅减少,训练时间也更短,实用性强。在多个数据集上,FC-CLIP都显著提升了状态转换水平。
FC-CLIP开创性的单阶段框架统一了掩码生成和文本匹配分类,具有巨大的潜力推动全景分割向开放词汇场景扩展,实现真正的图像理解和交互。这项突破性工作为端到端的单阶段全景分割方法提供了范例,值得进一步改进和扩展。
96核Zen4史无前例 AMD下代锐龙线程撕裂者被偷跑:再等4个月
快科技5月12日消息,AMD去年下半年发布了5nmZen4架构处理器,并且支持了DDR5、PCIe5.0等先进技术,现在已有桌面版、移动版、服务器版布局,再接下来还有一个大杀器锐龙线程撕裂者。当前的锐龙线程撕裂者还是锐龙5000系列,7nmZen3架构,最多64核128线程,但是相比Intel前不久发布的至强-3400系列,在DDR5、PCIe5.0及单核性能上都要落伍了。站长网2023-05-13 10:12:320001这个搞钱的生意太绝了!
各位村民好,我是村长。普通人绝对想不到或看不上这个生意!就算脑海里有这样的念头,也是一闪而过,最终没有落地。今天就和大家简短的聊一聊,文章不长。核心目的还是启发大家,做些思路延展,不要思维定式,多思考别人为什么能行。01大量真实的小需求今天要分享的这个生意是提供各种合同模板工具的,比如收入证明、工作证明、租房合同、离职证明、承诺保证书、授权委托等等。1、收入模式站长网2024-06-01 21:38:300001黑客大规模恶意注册与ChatGPT相似的域名 超65万个
**划重点:**1.🌐**恶意利用ChatGPT名声:**黑客注册大量与ChatGPT相似的域名,借助模型信誉欺骗用户,引发下载恶意内容、泄露敏感信息等问题。2.🌐**Cl0p勒索软件攻击:**俄罗斯Cl0p勒索软件组织利用MOVEit的零日漏洞,攻击全球企业和美国机构,新策略包括在勒索未付款时将数据泄露到公开网络。0000上热搜了!网友盘点iPhone羡慕安卓的功能:一只手都数不过来
快科技7月21日消息,微博话题iPhone羡慕安卓的功能”上了热搜榜。有网友盘点了国产安卓手机已有、iPhone却不具备的功能,轻松一盘点就多达十几项,具体如下:1、高频PWM调光/类DC调光;2、1英寸大底主摄;3、全功能NFC;4、红外遥控;5、快充;6、散热;7、USB3.2Gen1;8、应用多开;9、高刷策略;10、右侧返回;11、信号;12、长截屏;站长网2023-07-22 16:45:150000