大模型RoBERTa:一种稳健优化的 BERT 方法
要点:
1. BERT模型的出现在自然语言处理领域取得了显著进展,但研究人员继续对其配置进行实验,希望获得更好的性能。
2. RoBERTa是一种改进的BERT模型,通过多个独立的改进来提高性能,包括动态遮蔽、取消下一句预测、训练更长的句子、增加词汇量和使用更大的批次。
3. RoBERTa的性能在流行的基准测试中超越了BERT模型,虽然其配置更复杂,但只增加了15M个额外的参数,保持了与BERT相当的推理速度。
BERT模型在自然语言处理(NLP)领域具有举足轻重的地位。尽管BERT在多个NLP任务中取得了卓越的成绩,但研究人员仍然致力于改进其性能。为了解决这些问题,他们提出了RoBERTa模型,这是一种对BERT进行了多个改进的模型。
RoBERTa是一个改进的BERT版本,通过动态遮蔽、跳过下一句预测、增加批量大小和字节文本编码等优化技巧,取得了在各种基准任务上的卓越性能。尽管配置更复杂,但RoBERTa只增加了少量参数,同时保持了与BERT相当的推理速度。
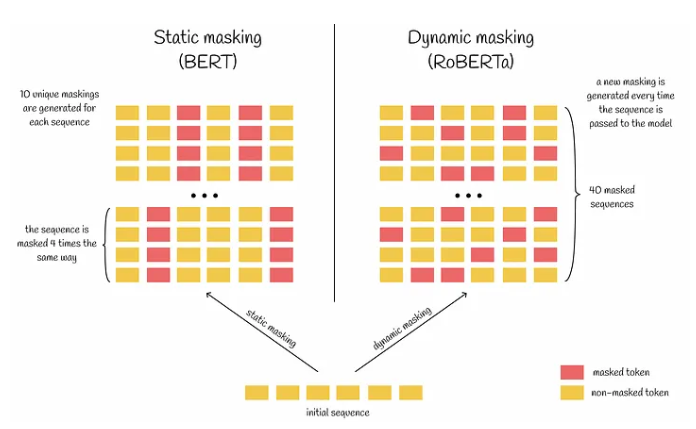
RoBERTa模型的关键优化技巧:
1. 动态遮蔽:RoBERTa使用动态遮蔽,每次传递序列给模型时生成独特的遮蔽,减少了训练中的数据重复,有助于模型更好地处理多样化的数据和遮蔽模式。
2. 跳过下一句预测:作者发现跳过下一句预测任务会略微提高性能,并且建议使用连续句子构建输入序列,而不是来自多个文档的句子。这有助于模型更好地学习长距离依赖关系。
3. 增加批量大小:RoBERTa使用更大的批量大小,通过适当降低学习率和训练步数,这通常有助于提高模型性能。
4. 字节文本编码:RoBERTa使用字节而不是Unicode字符作为子词的基础,并扩展了词汇表大小,这使得模型能够更好地理解包含罕见词汇的复杂文本。
总的来说,RoBERTa模型通过这些改进在流行的NLP基准测试中超越了BERT模型,尽管其配置更复杂,但只增加了15M个额外的参数,保持了与BERT相当的推理速度。这为NLP领域的进一步发展提供了有力的工具和方法。
近期值得购入的折叠机是哪款?华为用市场份额告诉你
站长网2023-08-22 22:30:440000阿里云开源通义千问Qwen-72B、Qwen-1.8B、音频大模型Qwen-Audio
阿里云开源通义千问720亿参数模型Qwen-72B、18亿参数模型Qwen-1.8B及音频大模型Qwen-Audio。据悉,阿里云本次开源的模型中除预训练模型外,还同步推出了对应的对话模型,面向72B、1.8B对话模型提供了4bit/8bit量化版模型,便于开发者们推理训练。站长网2023-12-01 09:08:040001年轻人“双标”预制菜:可以主动买,拒绝餐厅“喂”
年轻人对预制菜的态度,有点“言行不一”,这从近期过年预制菜的讨论中就能看出。春节将近,预制年菜、年夜饭预制礼盒等话题,成了应景的讨论热点。先是天猫预制年菜的广告遭群嘲,今年除夕不放假的打工人纷纷破防,“广告太阴间了”“年夜饭还是吃点好的吧”又有辛巴关于“让孩子吃一个好的预制菜是可以的,更健康更卫生”“老干妈、奶粉是预制菜”等言论引发网友“声讨”。站长网2024-01-31 14:35:010000OpenAI推出DALL·E 3识别器、媒体管理器
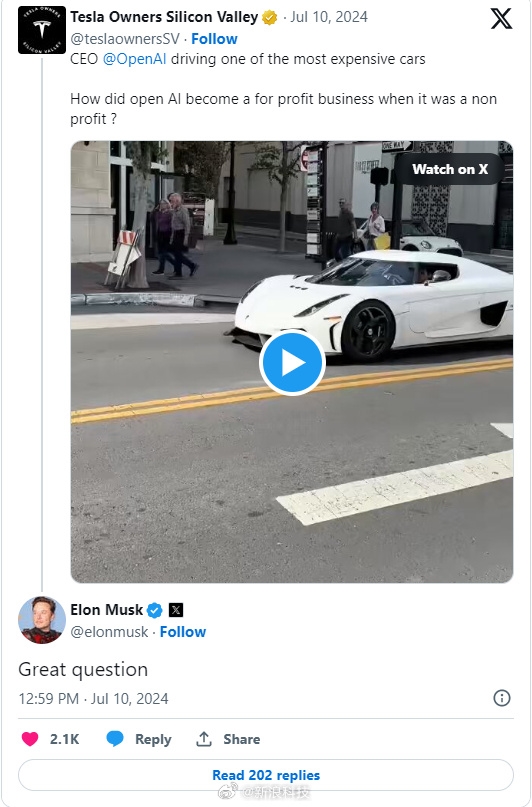
5月8日,OpenAI在官网宣布,将推出面向其文生图模型DALL·E3的内容识别器,以及一个媒体管理器。随着ChatGPT、DALL·E3等生成式AI产品被大量应用在实际业务中,人们越来越难分辨AI和人类创建内容的区别,这个识别器可以帮助开发人员快速识别内容的真假。站长网2024-05-08 21:42:500001OpenAI创始人开科尼赛格跑车遭质疑 马斯克神补刀
快科技7月12日消息,日前,OpenAICEO萨姆奥特曼(SamAltman)驾驶全球最贵跑车的视频引发了热议。视频中,奥特曼驾驶着一辆科尼赛格雷吉拉(KoenigseggRegera)跑车在街头行走,这辆车是世界上最稀有、最昂贵的跑车之一,其售价高达210万欧元,并且全球限量供给。在社交平台上,有网友嘲讽道,谁会想到,一份非营利性工作的薪水有这么高。”站长网2024-07-13 10:12:110000