首个千亿生物医药ChatGPT来了!清华AIR聂再清:这个行业未来的“Killer APP”
制药行业的“专家版ChatGPT”,终于来了!
就在这两天,首个生物医药的千亿参数大模型产品ChatDD发布,不仅制药各阶段知识“样样通”,还能和药学专家进行对话,瞬间秒懂一些行业神秘“黑话”。

这和AlphaFold2直接加个Chat功能还不太一样——
现阶段大模型虽然能在药物发现上做得不错,但要么只涉及单个模态,要么不具备直接对话能力。
ChatDD则兼具多模态和对话双重特点,顺便还能给医药界学生“解个惑”。
做出这个产品背后的水木分子,是今年6月新成立的一家公司。清华大学智能产业研究院院长张亚勤院士指出:
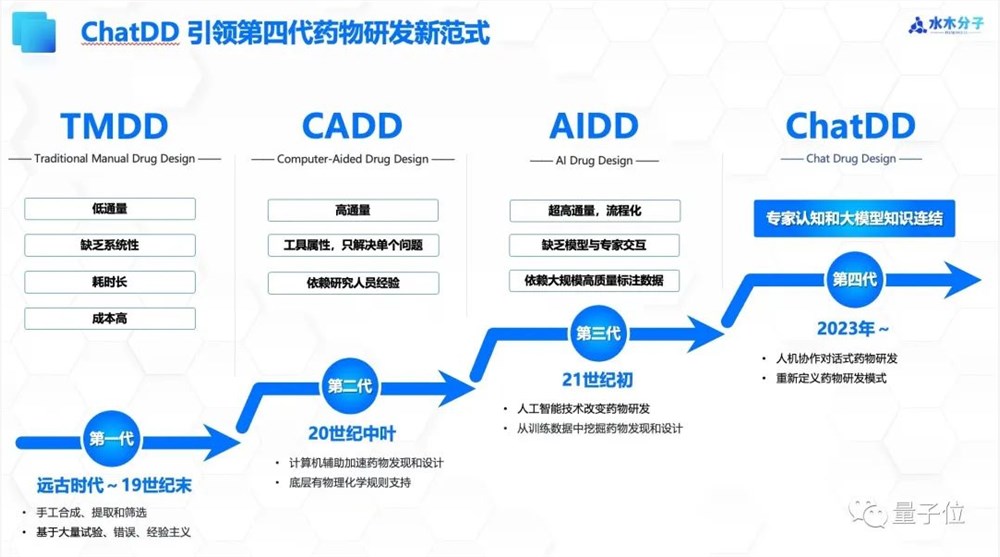
ChatDD通过人机协作对话方式有效地将专家知识与大模型知识相联结,开拓了继传统药物研发TMDD、CADD、AIDD之后的第四代药物研发新模式。
所以,它究竟在什么功能上做到“划时代”?
我们和清华AIR教授、水木分子首席科学家聂再清聊了聊,详细了解了ChatDD的来龙去脉。
ChatDD是一个什么样的产品?
先来看看ChatDD能做哪些事儿,具体又能用在哪里。
它的外观和ChatGPT有点像,是一个网页版,同样能通过对话来实现各种功能。
对话能力上,不仅英文总结不错,中文对话也来得,直接hold住“疾病画像”这样的专业黑(术)话(语):

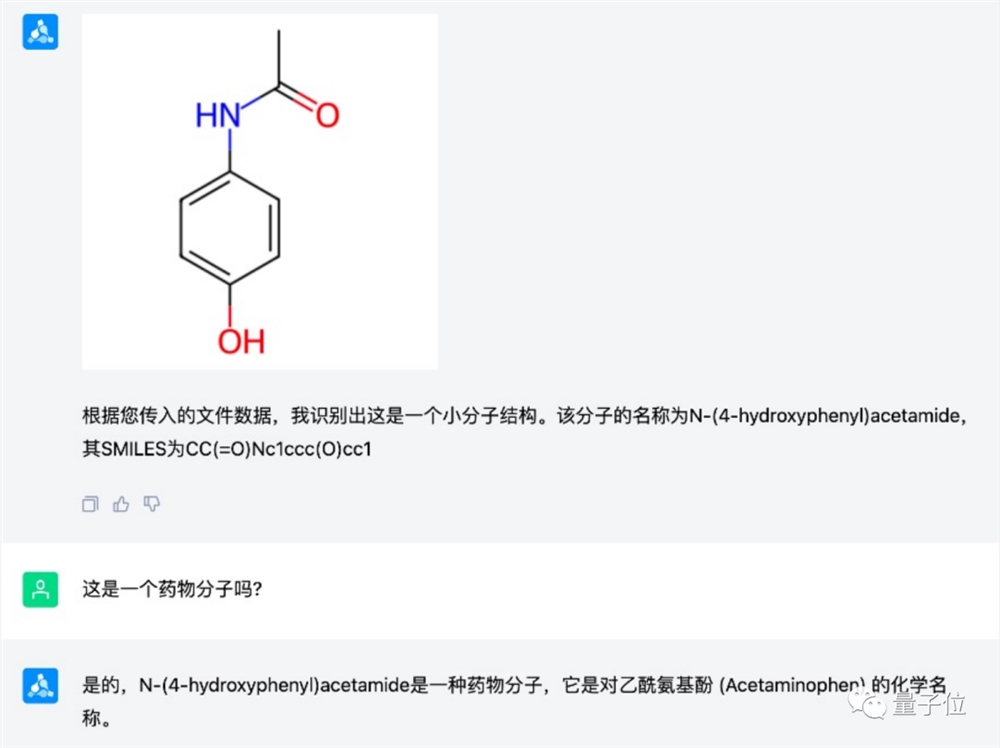
如果有看不懂的分子,可以直接一键上传相关文件,让它来负责解读这种分子的作用:
试试更复杂一点的任务,例如计算亲和力问题,大模型竟然直接“推荐”了一个工具,并快速计算出结果:

此外,也不用担心问答内容超出ChatDD训练数据截止日期,毕竟它还学会了自己联网、或是从数据库中查找答案。
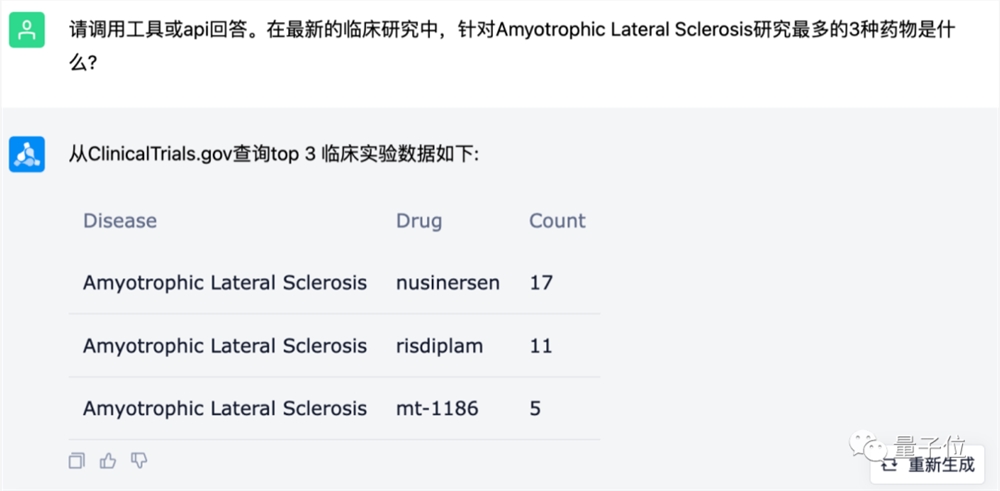
总结来看,ChatDD虽然用法上像ChatGPT,但在生物医药这块是“专业的”。
无论是掌握的多模态(小分子 大分子 文本)医药专业知识量,还是对行业的理解程度、完成任务的能力,ChatDD都要比ChatGPT“更像个学医药的人”。
与同行AI不同的是,ChatDD的“业务范围”,涵盖了制药的前、中、后期三个阶段。
此前的医药行业AI,即使是大模型,往往也只能用于制药的部分阶段,例如前期的药物发现,或是中期的临床前研究。占研发成本大部头的后期临床试验,几乎无人问津。
而ChatDD不仅能参与药物发现、立项、商业智能(BI,Business Inteligence)、临床试验各环节,还能帮助提升成功率。
聂再清介绍表示,ChatDD用于后期临床试验设计,也是大伙儿最期待的功能。
首先,药物在临床试验阶段的通过率,往往并不高。
尤其二期到三期临床,通过率只有34%,三期到四期通过率也不高。但临床试验加上前中期的费用往往又极高,一旦不通过,就是几亿美元成本“打水漂”。
其次,药物通过率不高的原因,(除非药物本身不行)很大程度上是因为没找到适合“对症下药”的患者。
药厂通常会从临床信息数据库中,筛选适合用药的病人。
假设这个药物对数据库中5%的患者有效,那么从这5%的患者中挑选进行临床试验,肯定比剩下95%的患者有效率高。
在综合各方面信息做判断这件事上,ChatDD往往比人类更适合筛选出“对症下药”的患者。
聂再清特意举了一个例子,来表明ChatDD的能力:

注意这里未来会是“私有化部署的合作伙伴的单细胞RNA测序数据”,现在因为没有,所以我们用了水木分子收集到的公开数据计算出来的。
这样的ChatDD,背后功能究竟是怎么实现的?
医学院博士后负责数据构建
ChatDD背后的底座,取名ChatDD-FM,参数量达到千亿级别。
这次推出的ChatDD-FM-100B,是全球首个千亿参数多模态生物医药对话大模型,其在C- Eval评测中达到全部医学4项专业第一、也是唯一平均分超过90分的模型。
联想到团队前不久发的BioMedGPT-10B,其自然语言模态的大模型同样基于LLaMA2架构,这二者是否有什么联系?
聂再清表示,ChatDD-FM和BioMedGPT,在受众和用途上都不太一样,“有点像ChatGPT和GPT-3.5的区别,前者在对话和意图对齐能力上有更大提升”。
BioMedGPT主要用于科研领域,更擅长英文生物医药科研任务,适合直接拿来作为生物医药领域的相关科研任务的基础模型。
ChatDD-FM主要给国内医药行业“打辅助”,侧重中文对话能力,融入了更多专家的对话模式和经验。
技术上,ChatDD-FM相比BioMedGPT,主要增强了三大方面,模态、训练数据和参数量级——
模态上,增加了蛋白质结构数据;训练上,增加了用于中文、专家对话和调用工具能力的数据;参数量级上,从百亿增加到千亿。
让ChatDD-FM提升“专业度”、说话像“行内人”的秘诀,依旧在于高质量数据上。
这些数据主要分为两部分。
第一部分,是预训练用的医药知识数据,主要目的是让ChatDD-FM提升专业素养,几个月内掌握行业知识。
由于之前业内缺少相关(大小分子等多个模态和自然语言对齐)数据集、尤其是中文数据,所以团队又自己收集整理了一系列训练数据集。
首先,和厂商合作翻译专业英文期刊、整理中文期刊,收集带有中文专业名词的大量数据,降低大模型没见过的专业词汇比率;
然后,找来一批医学院博士和博士后,设计一套系统对这些数据进行整理,直到它们可以被喂给大模型使用。
聂再清强调,这些博士不是在做数据标注,毕竟相比有监督学习,自监督学习更重要的是清洗、查找数据的工作:
这些期刊数据当然不是一个人一篇一篇地看,那绝对不行,也不是一个字一个字敲进去,也肯定不行。
毕竟大模型最主要的能力还是来源于自监督学习,所以更多是让他们进行数据清洗和查找的工作。
当然,医药界期刊总是在更新,因此这部分的工作也会持续进行。
第二部分,是“专家数据集”,专门用于提升ChatDD-FM的对话能力。
ChatDD的用户,会有不少医药领域的专业用户,为了让它能无缝读懂业内人的“专言专语”,就必须要先了解专家们平时都会怎么说话。
团队为此找了一些专家,“观察”他们平时是怎么提问的,根据这些问题整理了一套数据集,专门喂给ChatDD。
这样医药专业的用户在使用时,不仅能像和同事聊天一样直接提问,也能选择“提示词模板”直接换词填充。
此外,为了进一步增强模型解决实际医药任务的能力,团队也接入了不少实用工具和开源算法,解决用户遇到的问题,主要分为查询和计算两大类,如知识库查询工具、或靶点亲和力计算工具。
但,ChatDD-FM作为大模型,总归绕不过幻觉这个问题。
此前发布BioMedGPT时,聂再清就曾表示过不用害怕科研、药物发现等阶段的“幻觉”。现在发布商业版ChatDD-FM,是否还这么想?
聂再清表示,现阶段ChatDD-FM可以根据不同的需求,调整大模型出现幻觉的情况。
例如在做商业智能的时候,就尽可能降低大模型的幻觉,做到每一句话都有来源可追溯;
但在做药物发现的时候,只要有实验人员把关,都可以去适当提升幻觉,增加一部分模型想象力来“换换思路”,或许能试出有意思的结果。
后期,ChatDD-FM理论上甚至能做到“一键更改回答出现幻觉的比率”。

“对制药行业有划时代意义”
ChatDD背后的公司水木分子,目前已完成千万级种子轮融资。
水木分子自定义为“大模型时代的CRO公司”,即利用大模型或AI技术,帮助别人更好更快地制药。
公司的盈利方式目前有三种,包括ToB付费会员(按使用次数收费)、私有化部署和制药分成。
已经有制药厂商找来合作了——复星医药计划对ChatDD进行私有化部署,用于辅助药物立项等阶段。
药物立项,涉及大量资料查找和判断,包括查找有无药物相关(官能团、分子结构保护等)专利,还要根据大量文献和实时市场信息等资料判断是否值得立项。ChatDD能通过整合文献和相关专利,生成一个完整的参考报告。
ChatDD的出现,聂再清认为对于行业而言有跨时代意义:
它真正将专家的经验和直觉、以及大模型的“智力涌现”能力融会贯通了起来。
此前,制药行业经历了三个阶段,分别是TMDD(Traditional Manual Drug Design)、CADD(Computer-Aided Drug Design)和AIDD(AI Drug Design)。
但无论是人工试验,还是计算或AI辅助药物研发设计,都需要大量人力去“学会如何使用”模型,尚未出现一个能和科研人员直接对话的系统。
现在,ChatDD的出现真正改变了这一现状。
它不仅能将制药的知识经验集成到大模型中,通过提示词就能激发调用出来,还能通过学习专家对话方法掌握专业沟通能力,“相当于把人和机器最powerful的地方做了个融合。”
不过,要完全实现ChatDD的全部潜能,真正进入比较成熟的阶段,聂再清认为至少还有10年的黄金时代。
一方面,对于生物医药行业来说,人类对于蛋白质、细胞、小分子之类的理解也还远远不够,在这个学科方面仍然可以做出很多成绩和进展;
另一方面,对AI行业来说,无论是数据还是算法,也都还没发展到足够成熟的阶段。
数据上,目前生物医药领域内各模态和自然语言对齐的数据还很少。
(就像图文一样,虽然文字和图像各自的数据很多,但图文对齐如VQA的数据却相对要少很多)
对此依旧需要不断收集整理出PQA(蛋白质问答)、MQA(小分子问答)等模态的数据,来让多模态大模型的效果变得更好。
模型上,大模型目前的效果还不是最好的,无论是单模态还是多模态,都值得继续去探索。
所以,公司的下一步计划,就是继续优化模型、增加更多模态,并找到更多的场景落地需求。
对于ChatDD最终形态的设想,聂再清表示:
它会成为一个各模态(大小分子、蛋白质结构、DNA、单细胞等)和自然语言全部对齐的生物医药基础大模型产品。
他也在发布会上预言,这个产品会成为生物医药行业的大模型“Killer APP”。
到那时候,才会真正打破医药界的“双十定律”,高性价比的实现人机协作新药研发。
—完—
Sora给中国AI带来的真实变化
OpenAI的最新技术成果——文生视频模型Sora,在春节假期炸裂登场,令海内外的AI从业者、投资人彻夜难眠。如果你还没有关注到这个新闻,简单介绍一下:Sora是OpenAI使用超大规模视频数据,训练出的一个通用视觉模型,可以理解和模拟运动中的物理世界,生成不同时间、纵横比和分辨率的视频,最大版本的Sora能够生成长达一分钟的高保真视频。站长网2024-02-20 14:18:470000暂停元宇宙、进军AI、复刻推特,Meta亏损两年终盈利
近日,互联网与社交媒体巨头Meta发布了2023年Q2季度财报。在连续两年的亏损后,Meta终于交出了一份不错的成绩单。站长网2023-08-04 11:11:270000科大讯飞星火认知大模型V2.0发布 代码能力10月24日全面超越ChatGPT
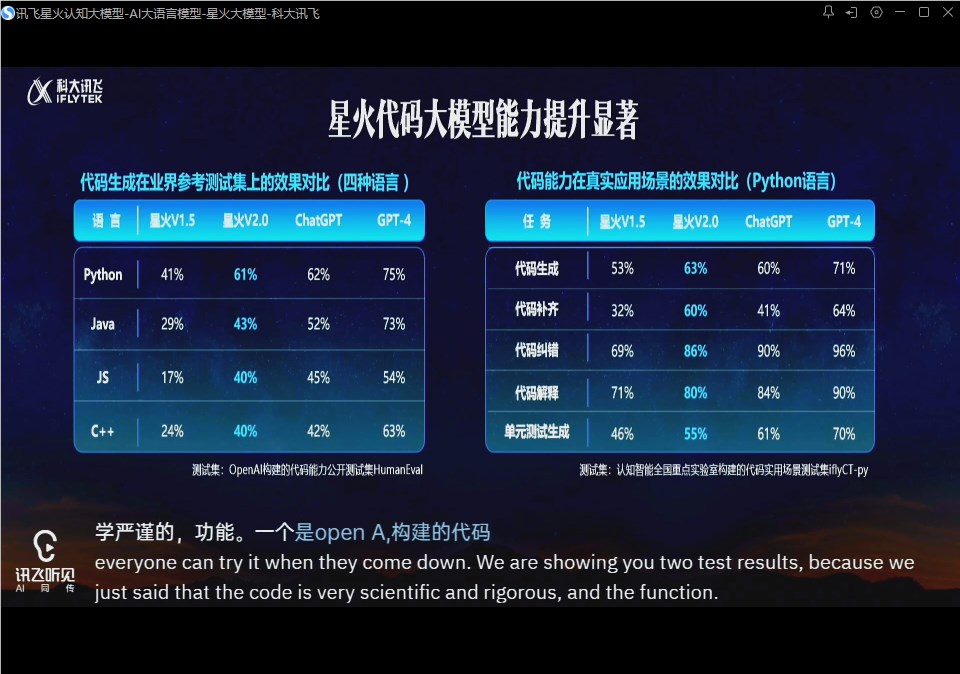
今日下午,科大讯飞发布了星火认知大模型V2.0,重磅推出代码能力、多模态能力。据介绍,从测试集上的效果对比来看,星火V2.0的Python和C语言代码编写能力已经高度逼近ChatGPT,差距仅为1%和2%。此外,科大讯飞还定下了明确的目标,计划在今年10月24日之前超越ChatGPT的各项代码能力,并在明年上半年正式对标GPT4。站长网2023-08-15 16:26:560000卢伟冰:小米MIX Fold 3将搭载徕卡光学全焦段四摄
小米卢伟冰宣布,北京亦庄小米智能工厂的「小米智能制造数智系统」2.0正式上线,首款量产机型将是小米MIXFold3。据卢伟冰透露,新制造系统升级非常大,简单说就是更智能、更精密,精度达到微米级,让小米新一代的折叠旗舰做到更薄、更坚固的同时,首次装载进了徕卡光学全焦段四摄。站长网2023-07-04 17:12:130000AI解决方案提供商「清昴智能」完成千万元天使轮融资
2023年6月,AI推理部署解决方案提供商「清昴智能」宣布完成数千万元天使轮融资,由绿洲资本独家领投,此次融资资金主要用于算法研发、产品开发和团队扩充。清昴智能成立于2022年10月,清昴智能创始团队来自于清华计算机系。清昴智能的使命是降低包括基础模型在内的AI使用和落地成本,通过针对模型的推理和部署环节进行优化来降低AI模型的使用门槛。清昴智能的愿景是让AI能够运行在任何设备上。站长网2023-06-25 23:21:350000