EasyPhoto:开源本地化部署的「妙鸭相机」,真的要革了「海马体」们的命了?|手把手教你搭建「妙鸭相机」
【新智元导读】EasyPhoto作为妙鸭相机平替,有着不输妙鸭相机的生成质量,还有更好的定制化空间和本地部署的优势。
年初由ChatGPT引发的AI浪潮奔涌至今,除了OpenAI推出的当红炸子鸡之外,中文互联网内热度最高的产品,非前段时间霸屏的「妙鸭相机」莫属了。
只要上传20张自己的自拍照,就可以拥有一个专属的数字分身。用户只用挑选自己喜爱的写真模板,就可以得到一张张专业质感的写真。(9块9的体验售价)

最高峰的时候,用户交了钱之后需要等接近10个小时才能获得自己的数字分身和写真。网传一个月流水超过1000万人民币。
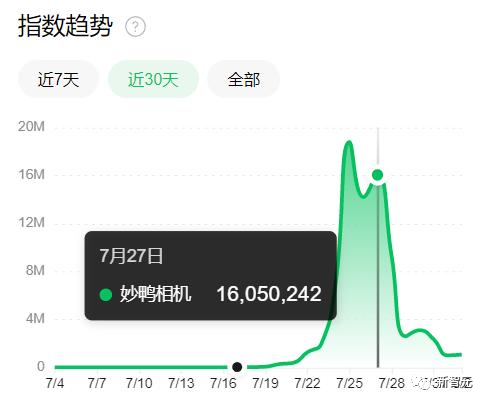
但从上边的「妙鸭相机」搜索趋势图也能看出来,网红产品的宿命,很难逃开「火速蹿红」 「极速陨落」。
因为用户协议中关于用户数据极为离谱的「霸王条款」,加上傲慢的「不予退款」政策,爆火之后的妙鸭相机很快就被负面舆论反噬,热度也迅速下滑。
而如果用户能在本地部署一个「妙鸭相机」,就能完全不用忍受高峰期长达数个小时的「排队取照」,也完全不用担心自己的照片和用户数据被开发者滥用。
由国内一个团队推出的EasyPhoto,就瞄准了这个痛点,在Github上开源了一个由Stable Diffusion作为基础,开源且支持本地化部署的「妙鸭相机」。
同样也是通过5-20张自己照片的训练,本地部署的模型就能通过EasyPhoto推理出堪比「妙鸭相机」的写真风照片。
而且相比于妙鸭相机,它还支持生成多人的照片。同时,用户还可以自己选择除了SD之外的其他模型来生成写真照片。
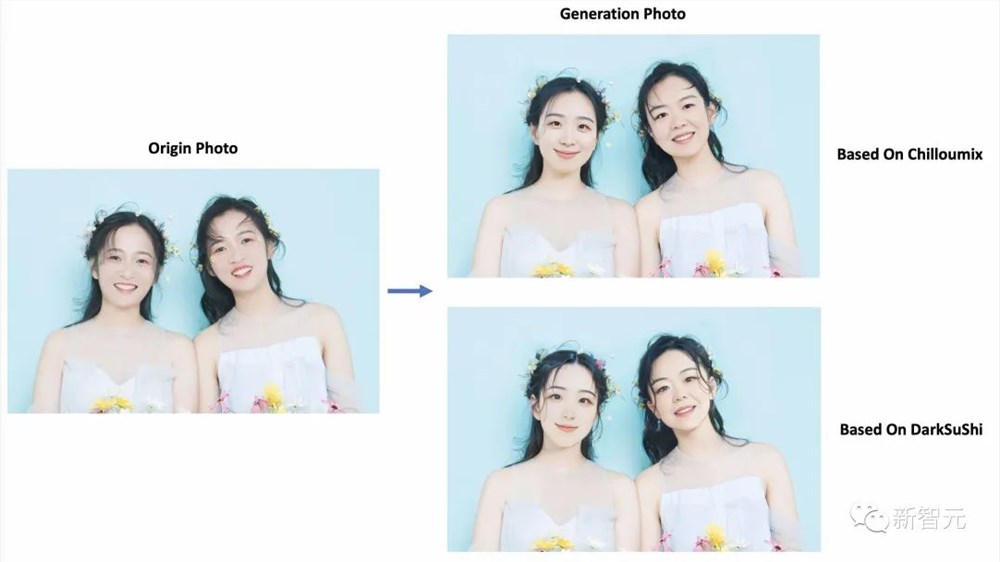
对于那些动手能力强的用户,EasyPhoto相当于一个加强版且免费的妙鸭相机。
甚至,只要自己有足够的算力资源,这个通用的「AI写真生成框架」可以直接向其他用户提供和妙鸭相机类似的AIGC服务。
使用指南
模型训练
EasyPhoto训练界面如下:
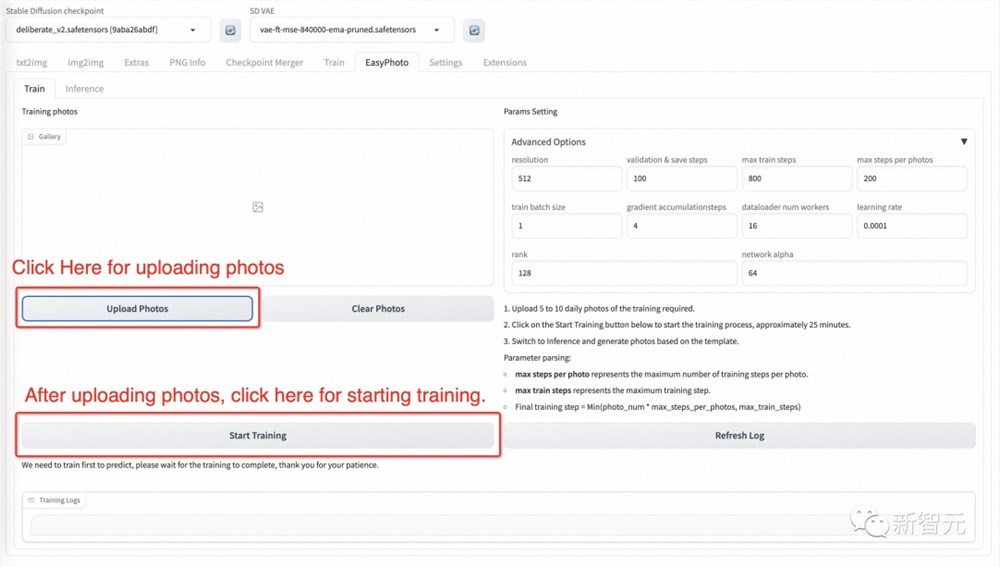
左边是训练图像,只需点击上传照片即可上传图片,点击清除照片即可删除上传的图片;
右边是训练参数,不能为第一次训练进行调整。
点击上传照片后,用户就可以开始上传图像这里最好上传5到20张图像,包括不同的角度和光照。最好有一些不包括眼镜的图像。如果所有图片都包含眼镜眼镜,则生成的结果可以容易地生成眼镜。
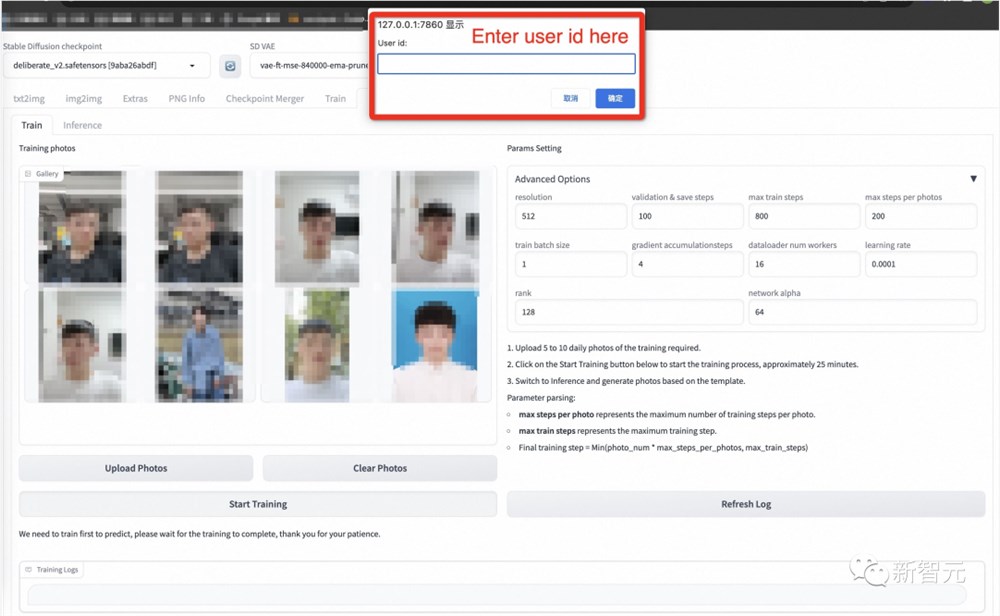
然后点击下面的「开始训练」,此时,需要填写上面的用户ID,例如用户名,才能开始培训。
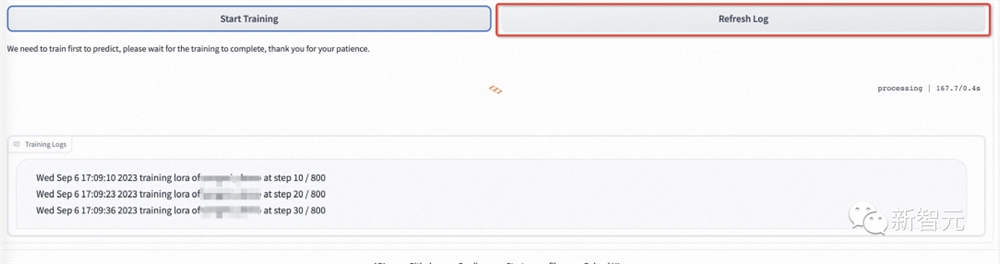
模型开始训练后,webui会自动刷新训练日志。如果没有刷新,请单击「Refresh Log」按钮。
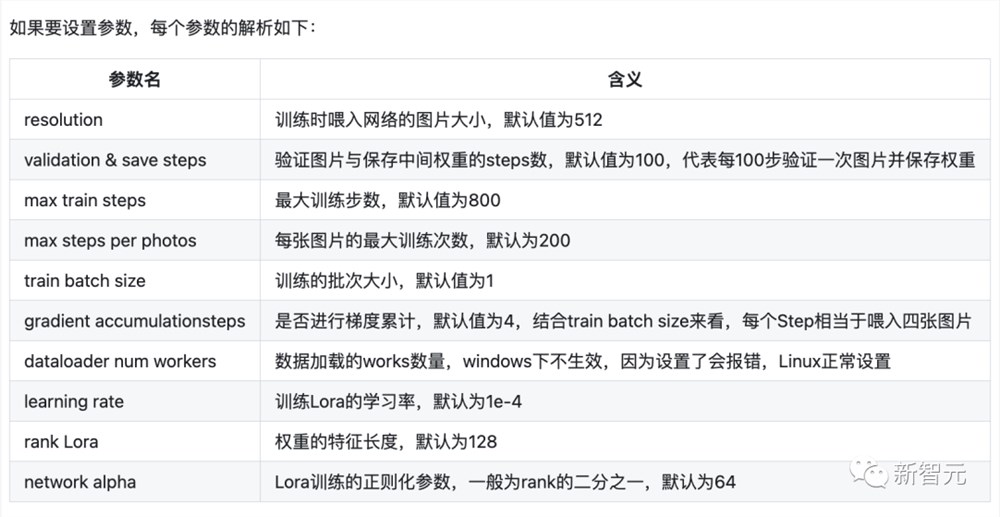
如果要设置参数,每个参数的解析如下:
2.人物生成a.单人模版
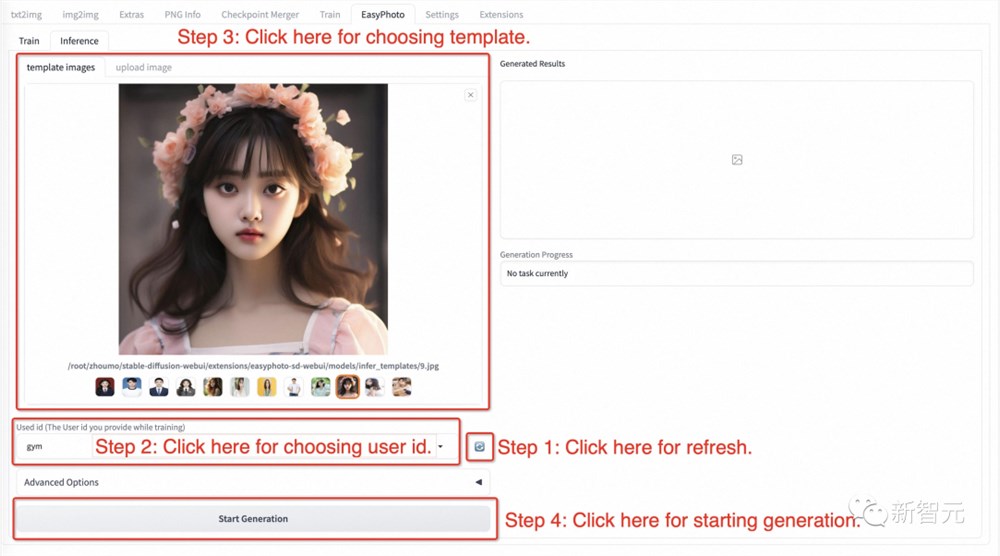
步骤1:点击刷新按钮,查询训练后的用户ID对应的模型。
步骤2:选择用户ID。
步骤3:选择需要生成的模板。
步骤4:单击「生成」按钮生成结果。
b.多人模板
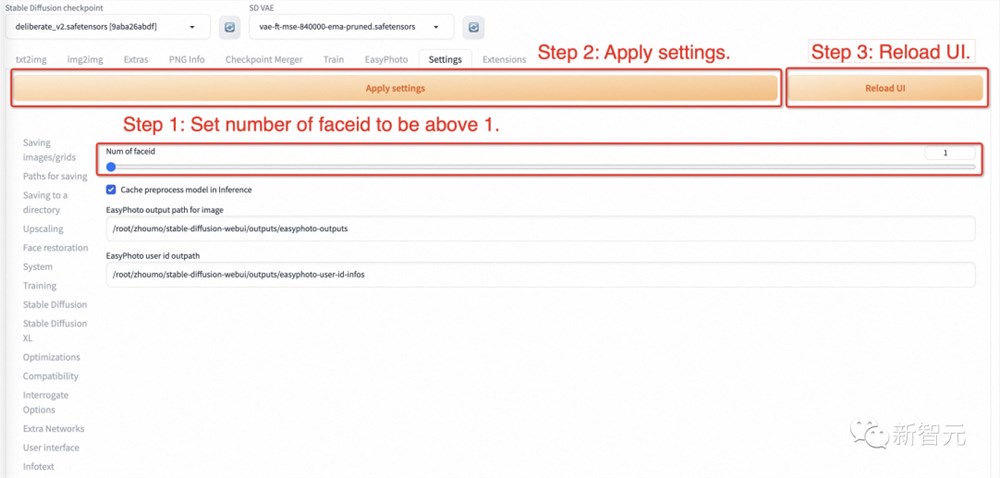
步骤1:转到EasyPhoto的设置页面,设置num_of_Faceid大于1。
步骤2:应用设置。
步骤3:重新启动webui的ui界面。
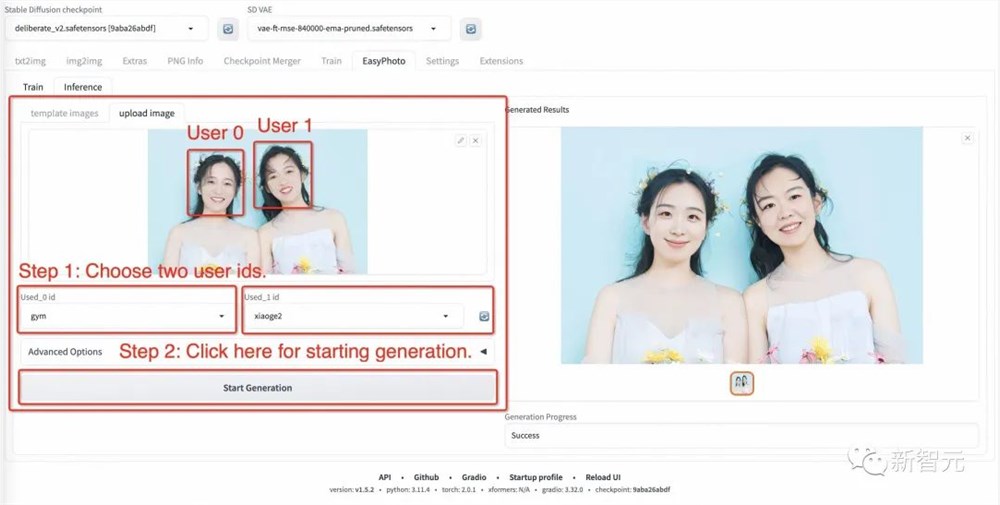
步骤4:返回EasyPhoto并上传多人模板。
步骤5:选择两个人的用户ID。
步骤6:单击「生成」按钮。执行图像生成。
算法详细信息
架构概述
在人工智能肖像领域,团队希望模型生成的图像逼真且与用户相似,而传统方法会引入不真实的光照(如人脸融合或roop)。
为了解决这种不真实的问题,团队引入了Stable Diffusion模型的图像到图像功能。
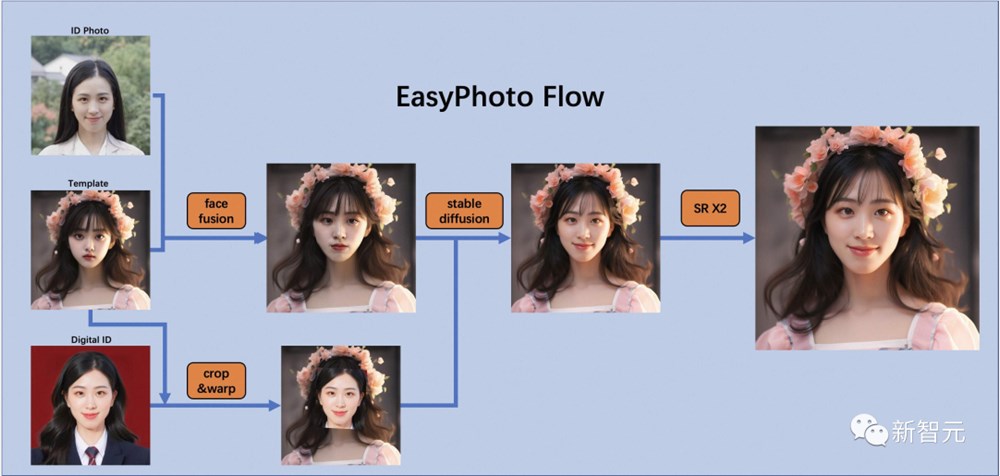
生成完美的个人肖像需要考虑所需的生成场景和用户的数字二重身。
使用一个预先准备好的模板作为所需的生成场景,并使用一个在线训练的人脸 LoRA 模型作为用户的数字二重身,这是一种流行的Stable Diffusion微调模型。
项目团队使用少量用户图像来训练用户的稳定数字二重身,并在推理过程中根据人脸 LoRA 模型和预期生成场景生成个人肖像图像。
训练细节
首先,对输入的用户图像进行人脸检测,确定人脸位置后,按照一定比例截取输入图像。
然后,使用显著性检测模型和皮肤美化模型获得干净的人脸训练图像,该图像基本上只包含人脸。
然后,项目团队为每张图像贴上一个固定标签。这里不需要使用标签器,而且效果很好。最后,项目团队对Stable Diffusion模型进行微调,得到用户的数字二重身。
在训练过程中,会利用模板图像进行实时验证,在训练结束后,项目团队会计算验证图像与用户图像之间的人脸ID差距,从而实现Lora融合,确保项目团队的Lora是用户的完美数字二重身。
此外,项目团队将选择验证中与用户最相似的图像作为face_id图像,用于推理。
推理细节a.第一次扩散:
首先,将对接收到的模板图像进行人脸检测,以确定为实现Stable Diffusion而需要涂抹的遮罩。
然后,将使用模板图像与最佳用户图像进行人脸融合。人脸融合完成后,将使用上述遮罩对融合后的人脸图像进行内绘(fusion_image)。
此外,还将通过仿射变换(replace_image)把训练中获得的最佳face_id图像贴到模板图像上。
然后,将对其应用Controlnets,在融合图像中使用带有颜色的canny提取特征,在替换图像中使用openpose提取特征,以确保图像的相似性和稳定性。
然后,将使用Stable Diffusion结合用户的数字分割进行生成。
b.第二次扩散:
在得到第一次扩散的结果后,将把该结果与最佳用户图像进行人脸融合,然后再次使用Stable Diffusion与用户的数字二重身进行生成。第二次生成将使用更高的分辨率。
参考资料:
https://github.com/aigc-apps/sd-webui-EasyPhoto
大模型浪潮推动之下,数据中心的“液冷时代”将给谁带来机会?
随着AI、云计算、区块链等技术的快速发展,数据资源的存储、计算与应用需求加速扩张。尤其是自去年年底以来,由ChatGPT引起的大模型浪潮,更是让数据处理热上加热,进一步催生了AI算力等大功率应用场景加速落地。作为信息基础设施中心及通信设备的数据中心承担的计算量越来越大,对计算效率的要求也越来越高,全球包括国内的数据中心有望迎来建设高峰。站长网2023-06-13 20:03:550001Her Trip Planner:专为女性冒险家设计的智能旅行规划平台
HerTripPlanner是专为女性冒险家设计的智能旅行规划平台,旨在重新定义旅行计划,提供无缝且安全的旅行体验。该平台的主要特点和功能包括轻松的旅行计划、安全优先考虑、个性化推荐和用户利益,旨在为女性冒险家提供独特而安全的旅行体验。站长网2023-09-18 17:12:130000我们尝试用AI创作了一条圣诞动画(附ChatGPT+Pika等制作流程全记录)
最近,AI视频生成领域可以说是迎来了一波小爆发,前有明星产品RunwayGen2,后有黑马Pika1.0爆火,随着越来越多的玩家和产品涌入AI视频赛道,视频创作的门槛似乎越来越低了。例如,今年圣诞节就有不少网友用Pika1.0整活,生成了各种脑洞大开的AI圣诞老人。话不多说,下面请看圣诞老人的多重人生🔽正在开圣诞摇滚专场的🎅🏻:站长网2023-12-25 18:52:230002努比亚Z60 Ultra官宣搭载Neovision泰山影像系统
努比亚将于12月19日14:00发布新款旗舰手机Z60Ultra,这款手机被官方宣传为“移动影像新标杆”。据努比亚官方介绍,Z60Ultra将采用全新的Neovision泰山影像系统,其中包含三个主摄像头,每个镜头都配备了OIS光学防抖功能。这三个摄像头分别是18mm50MP大底大光圈广角、35mm50MP高定光学、以及85mm64MP潜望式旗舰长焦。0000被微软“养大”的OpenAI,决定反噬微软
竞争近乎摊牌。8月29日,OpenAI发布了ChatGPT企业版,这是继个人用户争夺之后,OpenAI在企业用户争夺上与微软展开的正面交锋。由此,微软和OpenAI之间的“嫌隙”,双方都不再藏着掖着,被双方塑造成佳话的扶持故事迅速进入直接竞争的阶段。OpenAI和微软的裂痕最早要追溯到去年11月。0000