谷歌的野心:通用语音识别大模型已经支持100+语言
谷歌表示,推出通用语音模型(USM)是其未来支持1000种语言的关键一步。
去年11月,谷歌宣布推出「1000种语言计划」,旨在构建一个机器学习 (ML) 模型,支持世界上使用最广泛的1000种语言,从而为全球数十亿人带来更大的包容性。然而,其中一些语言的使用人数不到两千万,因此核心挑战是如何支持使用人数相对较少或可用数据有限的语言。
现在,谷歌公开了更多有关通用语音模型 (USM) 的信息,这是支持1000种语言的第一步。USM 包含一系列 SOTA 语音模型,带有20亿参数,经过1200万小时的语音和280亿个文本句子的训练,涵盖300多种语言。USM 不仅可以对英语和普通话等广泛使用的语言执行自动语音识别(ASR),还可以对阿姆哈拉语、宿雾语、阿萨姆语、阿塞拜疆语等使用人数很少的语言执行自动语音识别。
谷歌证明了利用大型未标记的多语言数据集来预训练模型的编码器,并用较小的标记数据集进行微调,能够让模型识别使用人数非常少的语言。此外,谷歌的模型训练过程可以有效地适应新的语言和数据。

USM 支持的语言示例。
当前的挑战
为了实现「1000种语言计划」,谷歌需要解决 ASR 中的两个重大挑战。
首先,传统的监督学习方法缺乏可扩展性。将语音技术扩展到多种语言的一个基本挑战是获得足够的数据来训练高质量的模型。使用传统方法,音频数据需要手动标记,这既费时又昂贵;或者从已有数据中收集可用数据,但这对于使用人数很少的语言来说很难找到。
相比之下,自监督学习可以利用纯音频数据,这些数据包含大量不同的语言,使得自监督学习成为实现跨数百种语言扩展的好方法。
另一个挑战是,在扩大语言覆盖范围和提升模型质量的同时,模型必须以计算高效的方式进行改进。这就要求学习算法具有灵活性、高效性和泛化性。更具体地说,算法需要能够使用来自各种来源的大量数据,在不需要完全重新训练的情况下启用模型更新,并推广到新的语言和用例。
解决方法:带有微调的自监督学习
USM 使用标准的编码器 - 解码器架构,其中解码器可以是 CTC、RNN-T 或 LAS。对于编码器,USM 使用 Conformer 或卷积增强型 transformer。Conformer 的关键组件是 Conformer 块,它由注意力模块、前馈模块和卷积模块组成。它将语音信号的 log-mel 声谱图作为输入并执行卷积下采样,之后应用一系列 Conformer 块和投影层以获得最终嵌入。
USM 的训练流程如下图所示:
第一步先从对涵盖数百种语言的语音音频进行自监督学习开始。
第二步是可选步骤,谷歌通过使用文本数据进行额外的预训练来提高模型的质量和语言覆盖率。是否采用这个步骤取决文本数据是否可用。
训练 pipeline 的最后一步是使用少量有监督数据微调下游任务(例如,ASR 或自动语音翻译)。
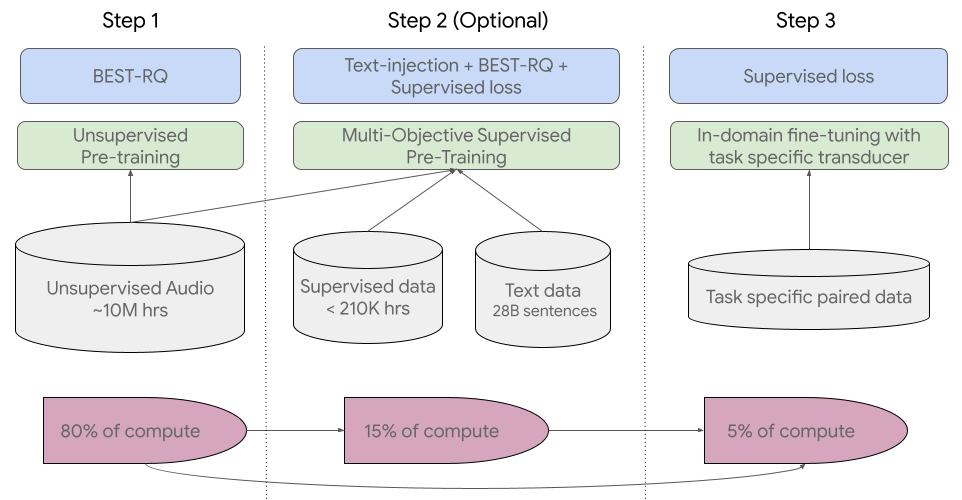
USM 的整体训练流程。
第一步中谷歌使用了 BEST-RQ,因为它已经在多语言任务上展示了 SOTA 结果,并且在使用大量无监督音频数据时被证明是有效的。
在第二步中,谷歌使用了多目标有监督预训练来整合来自额外文本数据的知识。USM 模型引入了一个额外的编码器模块将文本作为输入,并引入了额外的层来组合语音编码器和文本编码器的输出,然后再在未标记语音、标记语音和文本数据上联合训练模型。
凭借在预训练期间获得的知识,最后一步 USM 模型仅需来自下游任务的少量有监督数据即可获得良好的模型性能。
主要结果展示
YouTube Captions 测试集上不同语言的性能
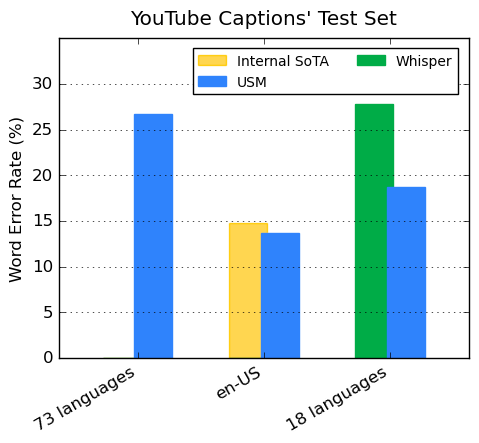
谷歌的编码器通过预训练整合了300多种语言,并通过在 YouTube Caption 多语言语音数据上微调证明了该预训练编码器的有效性。监督式 YouTube 数据包括73种语言,每种语言平均具有不超过3000小时的数据。尽管监督数据有限,USM 仍在73种语言中平均实现了低于30% 的词错率(WER,越低越好),这是以往从未实现的里程碑。对于 en-US,与当前谷歌内部 SOTA 模型相比,USM 的 WER 相对降低了6%。
谷歌还与 OpenAI 近期发布的大模型 Whisper (large-v2) 进行了比较,后者使用超过400k 小时的标注数据进行训练。为了便于比较,谷歌仅使用 Whisper 可以成功解码且 WER 低于40% 的18种语言。结果如下图所示,USM 的平均 WER 比 Whisper 低了32.7%。
对于下游 ASR 任务的泛化性能
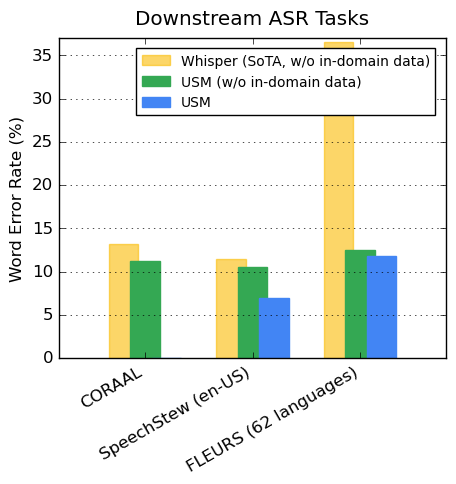
对于公开可用的数据集,USM 在 CORAAL(非裔美国人土语)、SpeechStew(en-US)和 FLEURS(102种语言)数据集上显示出了较 Whisper 更低的 WER。USM 在接受和没有接受域内数据训练的情况下都实现了更低的 WER。具体结果如下图所示。
自动语音翻译(AST)性能
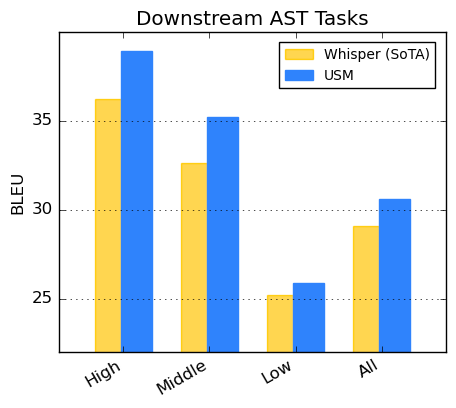
对于语音翻译,谷歌在 CoVoST 数据集上进行微调。谷歌的模型(包括通过 pipeline 第二阶段的文本)在有限监督数据下实现了 SOTA 性能。此外,为了评估模型性能的广度,谷歌根据资源可利用性将 CoVoST 数据集中的语言分为了高(high)、中(medium)和低(low),并计算相应的 BLEU 分数(越高越好)。
如下图所示,USM 在所有语言细分中超越了 Whisper。
未来将支持1000种语言
USM 的开发是实现「谷歌组织全球信息并使人人皆可访问」使命的关键努力。谷歌相信,USM 的基础模型架构和训练 pipeline 奠定了将语音建模扩展到未来1000种语言的根基。
争造第一个“国产ChatGPT”,大厂们拼了
2023年开年,ChatGPT属实火了,大厂们也没闲着,纷纷开始了第一波火速布局。从微软、谷歌,到百度、京东、科大讯飞、腾讯等,都先后宣布与ChatGPT结合上线的业务线。其中,百度更是在刚刚结束的2022年第四季度财报会议上,对其“中国版”ChatGPT业务——文心一言寄予厚望。站长网2023-03-11 09:06:270004辣眼睛的丑东西,如何成为一种潮流?
美的东西总是千篇一律,丑的东西往往万里挑一。不知从何时起,丑东西逐渐脱离了观众的审美盲区,大有发展成主流的趋势。最近,第三届淘宝丑东西颁奖盛典刚刚落下帷幕,今年获得“年度五丑”的作品再度刷新了观众对于“丑”的认知,这也令观众意识到,丑东西似乎并不存在天花板。站长网2023-03-06 15:25:590002B站去年净亏损75亿!全年给Up主分了91亿,网友:我只知道B站广告越来越多了
高企的内容和流量成本下,尽管营收增长,哔哩哔哩的亏损再度扩大。最新公布的2022年度业绩显示,B站2022年营收219亿元人民币,较2021年增长约13%,净亏损为75亿元人民币,较2021年68亿元扩大约10%。站长网2023-03-04 09:37:080000这款“克隆版”ChatGPT开发成本仅需30美元,还开源了!
站长之家(ChinaZ.com)3月29日消息:前不久,斯坦福科学家仅用600美元就克隆了OpenAI的ChatGPT的报道引发了不少关注,现在有开发团队仅用30美元成本就开发出了似于ChatGPT的聊天机器人。这是怎么做到的呢?(相关文章阅读《意不意外!斯坦福科学家仅用600美元就克隆了OpenAI的ChatGPT》)开发成本仅为30美元站长网2023-03-29 17:32:310000我在支付宝开直播,帮人做招聘
“具体招聘哪些岗位?”“有五险一金吗?”“住宿免费吗?”一连串的直播实时互动,成为不少人在直播间找工作的新方式。新方式背后是新变化。“短视频用户规模达10.12亿,并向各类网民群体渗透;网络直播用户规模达7.51亿,成为网络视听第二大应用。”当不断逼近天花板的短视频用户渗透率遇上4亿蓝领从业者,一个新赛道也正在长成——直播带岗。站长网2023-04-05 09:52:150001