【RVC教程】 AI 实时变声器使用教程|AI降噪|音频跳线
我自己的配置是:
CPU:13700kf
内存:80G
显卡:RTX3080
以下是会用到的工具及软件(下载链接)
NVIDIA Broadcast(输入声音降噪)
/geforce/broadcasting/broadcast-app/
RVC语音转换(变声器)
GitHub项目开源地址:https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
变声器框架:花儿不哭
Voicemeeter Potato(虚拟声卡)
/Voicemeeter/potato.htm
这里为了方便学习,我已经整理好了所有用到的软件
链接:https://pan.baidu.com/s/1QZp1thWs5AGwlV70rZ8Huw?pwd=59bg
完整图文教程在群里!!!
下载完这4个文件
这些先把这两个软件安装了(应该会让你重启电脑,如果没让你重启,也最好手动重启一下)
使用NVIDIA Broadcast降噪
然后打开NVIDIA Broadcast
把麦克风源改成你的输入设备
如果不知道哪个是输入设备,可以打开声音设置
看哪个有显示波形哪个就是输入设备
这个噪声消除是默认打开的,你也可以调节它的强度
使用RVC实时语音转换(变声器)
然后我们打开RVC
点击以后会弹出cmd以及前端
在使用过程中cmd和前端都不能关
加载模型
1.Hubert模型,在RVC-beta内,往下拉找到它
(提醒一下所有的模型文件库必须设置英文)
2.pth文件,(声音模型文件)
刚刚网盘下载的文件中有,请放在英文路径的模型文件夹中!!!
3.index文件,(声音特征索引文件)同上
4.npy文件,可以忽视,
音频设置
这样输入设置设置为nvidia broadcast的麦克风(因为这是nvidia broadcast降噪过的输出源)
然后我们在把输出设备调整为VoiceMeeter Input(这是Voicemeeter Potato安装后的跳线通道)
注:这里选择输入输出设备的时候注意看后面是否有带(MME),选择带(MME)的
参数设置(该参数部分参考:Abbott风)
1.响应阈值
尽量拉满-60,这里说一下,同时开多个ai处理软件,对显存要求比较高,尽量8gb以上,不然打游戏都会卡的。
在提醒一下RVC在运行时主要对CPU有一定的要求,CPU差的话它的延时(推理时间)就会很长
2.音调设置
男转女一般在 12,在这附近左右调整可以变粗或变细,选好之后就不要动了。
女转男一般在-12,
3.index rate
这东西左边是接近底模的音色,右边是接近模型的音色。如果调高不影响口齿,可以略微调高,一般0.3-0.5都是可以的。如果模型效果不理想尽量往左。
4.采样长度
尽量调低一些,只要不卡,0.3以上都可以。我一般就默认1.0
5.淡入淡出长度
可以理解为尾音的长短,小了声音清脆但容易断字,大了声音连贯但音色会糊。根据自己听感来。
6.额外推理时长
一般2种选择,当采样长度比较大的适合,可以保持采样长度一样的数值,但是说话会比较干,没什么拖音。
另外一种选择,可以考虑公式:采样长度 额外推理时长=2这个公式,一般效果效果还不错,说话连续性更强。
推理这个参数有点像压限器的释放时长,如果你想你的尾音拖的比较长就拉到1.5左右,如果想清爽点,吐字如机关枪,那就往低了拉,一般到采样长度左右就行。
7.输入降噪 输出降噪
下面的输入输出降噪建议不要开(影响变声效果,而且影响推理时间,所以这里用了nvidia broadcast的ai降噪)
使用Voicemeeter Potato(虚拟声卡)做音频跳线操作
然后打开Voicemeeter Potato
你可以把这些默认点亮的A1、B1关掉(划线的是要关的)
我们点右上角A1
我们可以看到这里有很多的输出设备,选择你要输出的设备就可以了
下面是整个声音源的转换流程图
下面是声音模型的训练教程
训练声音模型
打开文件夹里的这个程序
会自动打开cmd跳转到网页端(前端)
使用的时候cmd不要关
进来以后这样一个界面,我们点击“训练”
采样这边越高越好(不过要看你的训练素材,如果训练素材采样不好,再高也没有用)
这是你的CPU线程数一般默认最高就好了
用于声音训练的文件夹(这里是文件夹,就算只有一条用于训练的声音也要在音频文件的上层建立一个文件夹)
里面放好声音源
一般wav格式的声源最好,MP3也行(MP3格式的采样率不高,有wav格式优先wav格式)
这里可以鼠标右键复制文件地址
我一般就选择这个(13700kf无所畏惧)
这里我一般就这么设置
保存频率:默认是5,不过我一般设置20
总训练轮数:1000
不过这个训练轮数不是越高越好的,训练轮数多了会过拟合 反正就是模型效果会变差,
而且训练时间是真的慢,10分钟的训练音源(干净的人声)RTX3080跑1000轮要一个小时左右,
不过如果真的要炼一个非常好的声音,推荐音源都是在一个小时以上的(音源干净非常重要)
每张显卡的batch_size:这是调整训练时显存占用的,你调的越大训练的越快,不过重点就是看你的显卡了
像我RTX3080 10G 给20就跑满了,再高就会报错或无法训练
然后这个,我推荐打开“是”,
不开的话非常容易满硬盘(500轮就100G了)
然后我推荐把这个RVC软件放在固态里面的,可以加速训练时间
下面这两个是预训练的底模路径(大佬可以自行调整)
底模路径就在RVC文件夹里
打开可以看到预训练的底模
设置好这些就可以开始训练了
训练的时候它会帮你把完整的音频文件拆开(在logs文件夹里)
点你命名的那个模型名的文件夹
这两个文件夹里面是拆好的音频文件
然后 训练完后在你命名的模型名文件夹里,有这个added开头的文件,这是模型的声音特征索引文件
如果训练完没有的话可以点这个,重新训练一份声音特征索引(这个声音特征索引,训练几秒钟就好了)
看右下角输出信息,显示训练完成就好了
使用模型推理查看训练效果
然后可以去模型推理查看训练效果
选择你刚刚训练出来的模型
变调:男转女 12,女转男-12
然后选择你的原声录音,添加到待处理音频文件路径中(这里是音频文件,不是文件夹)
提取算法选择 harvest
点击这个index路径选择框,选择训练好的模型声音特征索引,这个声音特征索引要跟你训练出来的声音模型是匹配的,用不匹配的模型声音特征索引转换出来的声音会很奇怪
这边设置好以后转换就可以了,稍等一会右侧就会出现播放按钮
Python中的中文文本情感分析:6种方法详解!
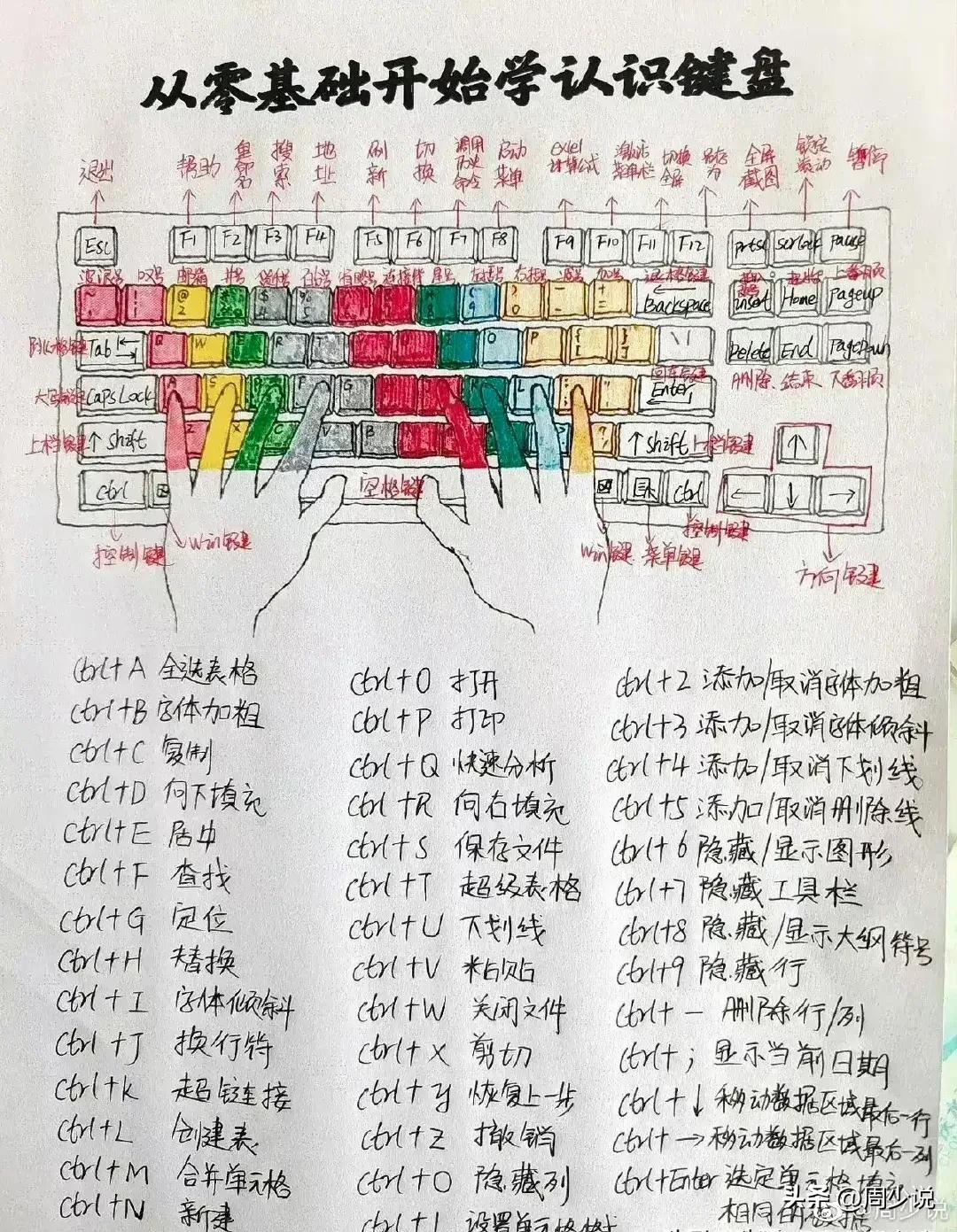
中文文本情感分析是一种将自然语言处理技术应用于文本数据的方法,它可以帮助我们了解文本中所表达的情感倾向。在Python中,有多种方法可以进行中文文本情感分析,下面将介绍其中的6种方式。基于情感词典的方法情感词典是一种包含了大量情感词汇的词典,其中每个词都被标记为积极、消极或中性。基于情感词典的方法是将文本中的每个词与情感词典中的词进行匹配,然后根据匹配结果计算文本的情感倾向。0000天呐!不愧是精通电脑的高手,原来早就把键盘上的功能全搞清楚了,并
天呐!不愧是精通电脑的高手,原来早就把键盘上的功能全搞清楚了,并且还详细写了出来,让人一看就懂,不得不说即使是电脑小白,也能看清楚明白。建议大家保存下来,尤其是办公室白领、学生或者是经常需要使用的人,尽早把这些快捷键和按键功能背书,不但可以快速提高工作效率,还能彻底解决日常遇见的问题,助你成为电脑高手,瞬间让你在同事与同学当中脱颖而出。站长网2023-07-30 15:31:570002这些网站,泰裤辣!
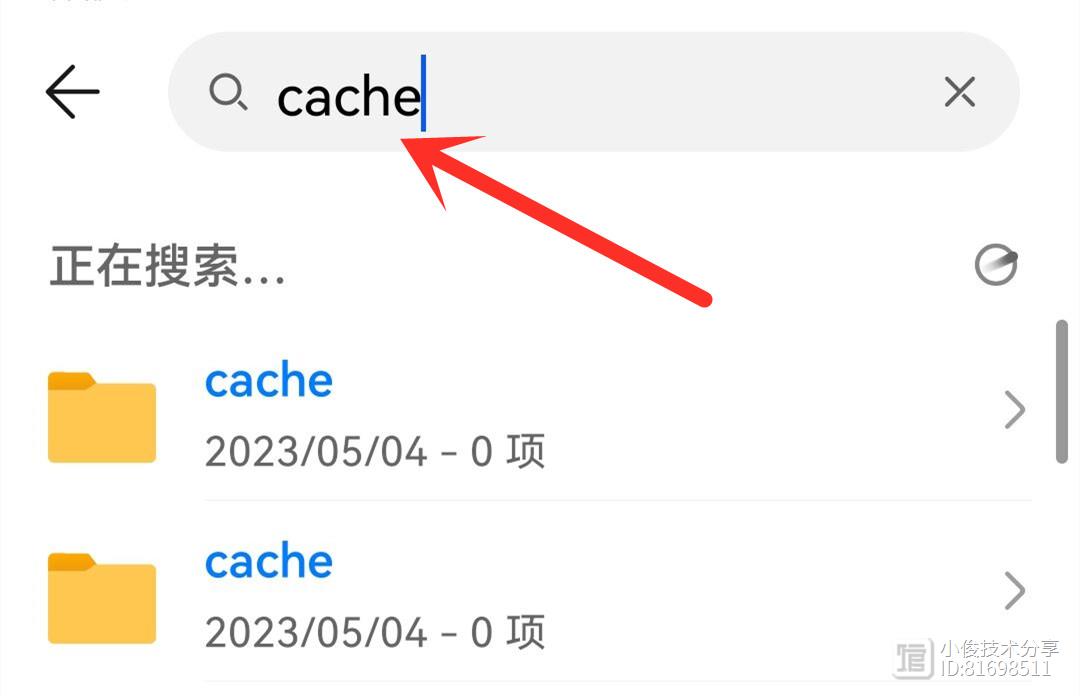
hello大家好,这里是日常爆肝更新的老Y工作室。老Y继续给大家分享有趣好玩的网站,今天带来4个,都是老Y在“业余”时间为大家寻找的,记得点赞在看01、相声随身听网址:/不可多见的可以免费听相声和评书的好网站,里面的资源非常多,喜欢相声和评书的小伙伴们不能错过。关键的是不但能听还可以免费下,良心。收听很简单,点击即可,在详细页里能够看到免费下载按钮。02、自我测试网址:/cn站长网2023-07-27 14:01:300000别再清理垃圾了,删除这6个地方,手机用多久都不会卡
平时大家在使用手机的时候啊,是不是经常会遇到内存爆满,内存不足的提示,那很多朋友一旦出现这些问题之后啊,就忍不住去对手机里面的一些照片和视频进行删除,以及呢卸载一些不常用的软件,最后呢再去把一些文件也进行删除,这样呢就可以有效释放手机内存空间,那今天小俊给大家分享的是如何一次性清理手机空间的正确方法,学会之后方法之后,瞬间可以清理出几G或者几十G的内存,接下来就跟着小俊一起来学习一下他的知识!站长网2023-07-28 09:00:400000微信只清空聊天记录和没删一样,教你正确清理方法,释放手机空间
站长网2023-07-28 08:50:190000