技术加速大模型推理
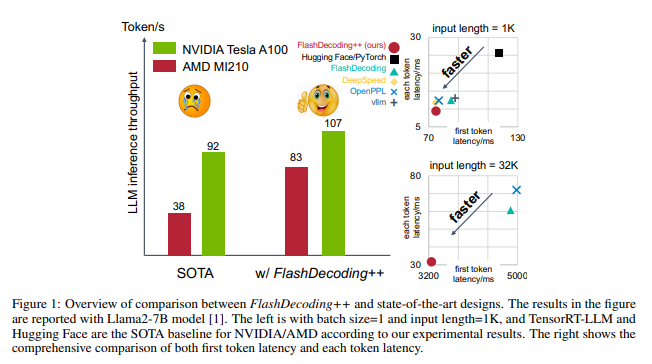
GPU推理提速4倍!FlashDecoding++技术加速大模型推理
要点:1.FlashDecoding是一种用于加速大模型(LLM)推理任务的新方法,可以将GPU推理提速2-4倍,同时支持NVIDIA和AMD的GPU。2.FlashDecoding的核心思想包括异步方法实现注意力计算的真正并行以及优化"矮胖"矩阵乘计算,以降低LLM的推理成本并提高推理速度。站长网2023-11-06 14:12:230000

热点
SAP 和 Databricks 使客户能够统一 AI 的数据
2025-02-15 10:22:44单月涨粉破百万,小红书迎来开门红
2025-02-18 09:18:45揭秘:苹果AI为何选阿里不选DeepSeek
2025-02-15 10:22:16AI+再升级!最强地级市下了一盘大棋
2025-02-18 09:14:00获英伟达买入 中国自动驾驶公司文远知行股价暴涨超100%
2025-02-15 10:22:15年入千万的AI恋爱键盘,可能会让你的crush拉黑你
2025-02-17 18:20:38不要学编程!大佬警告别报AI专业,全美15万IT精英被裁员,CS毕业即失业
2025-02-15 10:17:59一周涨粉150万,《好一个乖乖女》捧红“短剧新一哥” | 新榜对话
2025-02-17 18:09:09顺丰接收全球第100架波音767-300BCF:3月正式投入航线
2025-02-15 10:04:07微软开源创新框架:可将DeepSeek,变成AI Agent
2025-02-17 18:00:41
关注
单月涨粉破百万,小红书迎来开门红
2025-02-18 09:18:45三星Galaxy S25系列正式发布 Ultra顶配版售价13199元
2025-02-11 17:48:17AI+再升级!最强地级市下了一盘大棋
2025-02-18 09:14:00
数据 | 深挖2024涨粉最多的1000个抖音账号,我们总结了3大内容趋势
2025-02-11 17:47:46年入千万的AI恋爱键盘,可能会让你的crush拉黑你
2025-02-17 18:20:38全年免佣金!京东外卖启动餐饮商家招募
2025-02-11 17:41:02
一周涨粉150万,《好一个乖乖女》捧红“短剧新一哥” | 新榜对话
2025-02-17 18:09:09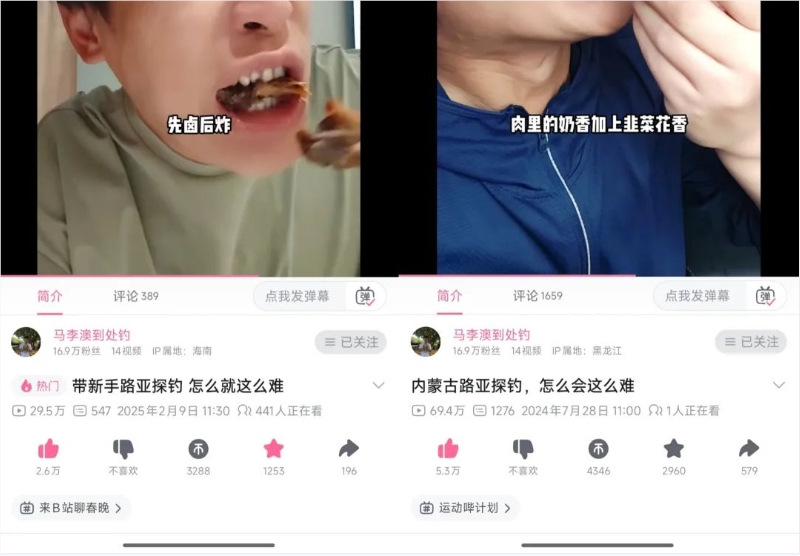
全网更新最慢钓鱼UP主@马李澳到处钓,如何靠“佛系”圈粉17万?丨金腰带
2025-02-11 17:40:32微软开源创新框架:可将DeepSeek,变成AI Agent
2025-02-17 18:00:41
两极反转,外国人开始在X上卖中国AI的课了?
2025-02-11 17:36:01