「教科书级」数据能有多大作用?微软超强小模型引热议
随着大模型掀起新一轮 AI 热潮,人们开始思考:大模型的强大能力来源于什么?
当前,大模型一直在由不断增加的「大数据」来推动。「大模型 大数据」似乎已经成为构建模型的标准范式。但随着模型规模和数据量的不断增长,算力的需求会迅速膨胀。一些研究者尝试探索新思路。
6月,微软发布了一篇题为《Textbooks Are All You Need》的论文,用规模仅为7B token 的「教科书质量」数据训练了一个1.3B 参数的模型 ——phi-1。尽管在数据集和模型大小方面比竞品模型小几个数量级,但 phi-1在 HumanEval 的 pass@1上达到了50.6% 的准确率,在 MBPP 上达到了55.5%。
phi-1证明高质量的「小数据」能够让模型具备良好的性能。最近,微软又发表了论文《Textbooks Are All You Need II: phi-1.5technical report》,对高质量「小数据」的潜力做了进一步研究。

论文地址:https://arxiv.org/abs/2309.05463
模型简介
架构
研究团队使用 phi-1的研究方法,并将研究重点放在自然语言常识推理任务上,创建了拥有1.3B 参数的 Transformer 架构语言模型 phi-1.5。phi-1.5的架构与 phi-1完全相同,有24层,32个头,每个头的维度为64,并使用旋转维度为32的旋转嵌入,上下文长度为2048。
此外,该研究还使用 flash-attention 进行训练加速,并使用 codegen-mono 的 tokenizer。

训练数据
phi-1.5的训练数据是由 phi-1的训练数据(7B token)和新创建的「教科书质量」数据(大约20B token)组成的。其中,新创建的「教科书质量」数据旨在让模型掌握常识推理,研究团队精心挑选了20K 个主题来生成新数据。
值得注意的是,为了探讨网络数据(LLM 常用)的重要性,该研究还构建了 phi-1.5-web-only 和 phi-1.5-web 两个模型。
研究团队表示:创建强大且全面的数据集需要的不仅是原始计算能力,还需要复杂的迭代、有效的主题选择,以及对知识的深入了解,具备这些要素,才能确保数据的质量和多样性。
实验结果
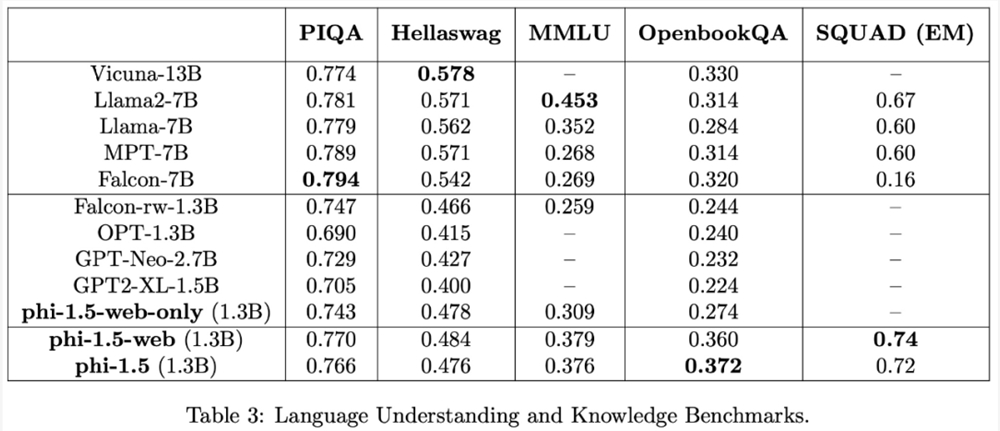
对于语言理解任务,该研究在多个数据集(包括 PIQA、Hellaswag、OpenbookQA、SQUAD 和 MMLU)上评估了一些模型。评估结果如下表3所示,phi-1.5的性能可以媲美5倍大的模型:
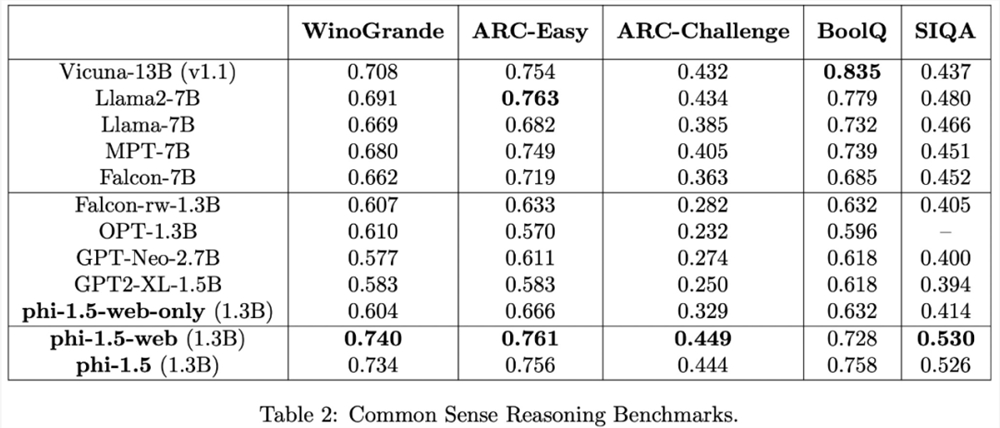
在常识推理基准上的测试结果如下表所示:
在更复杂的推理任务(例如小学数学和基础编码任务)上 phi-1.5还超越了大多数 LLM:
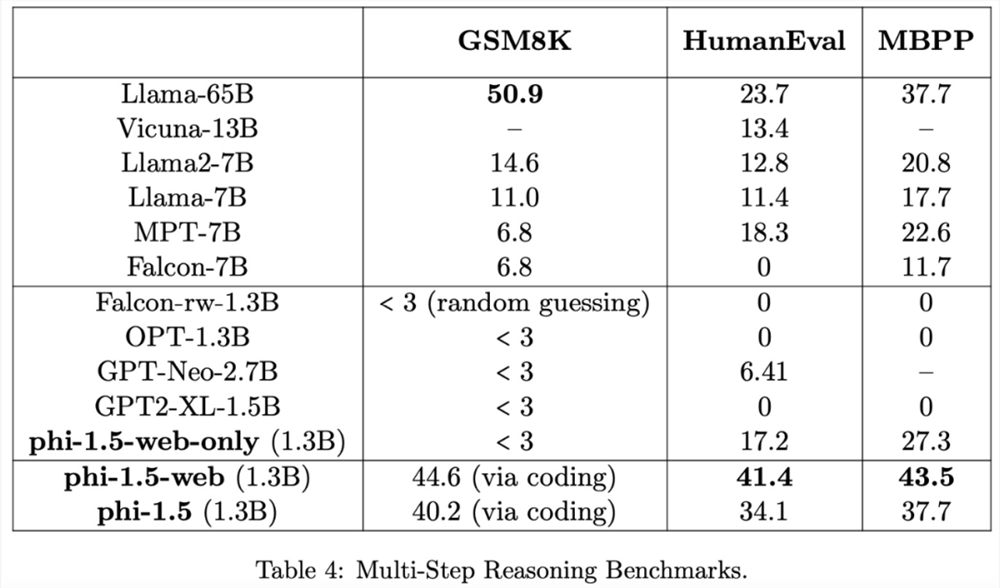
研究团队认为,phi-1.5再次证明了高质量「小数据」的力量。

质疑与讨论
或许是因为「大模型 大数据」的理念太深入人心,这项研究遭到了机器学习社区一些研究人员的质疑,甚至有人怀疑 phi-1.5直接在测试基准数据集上训练了。

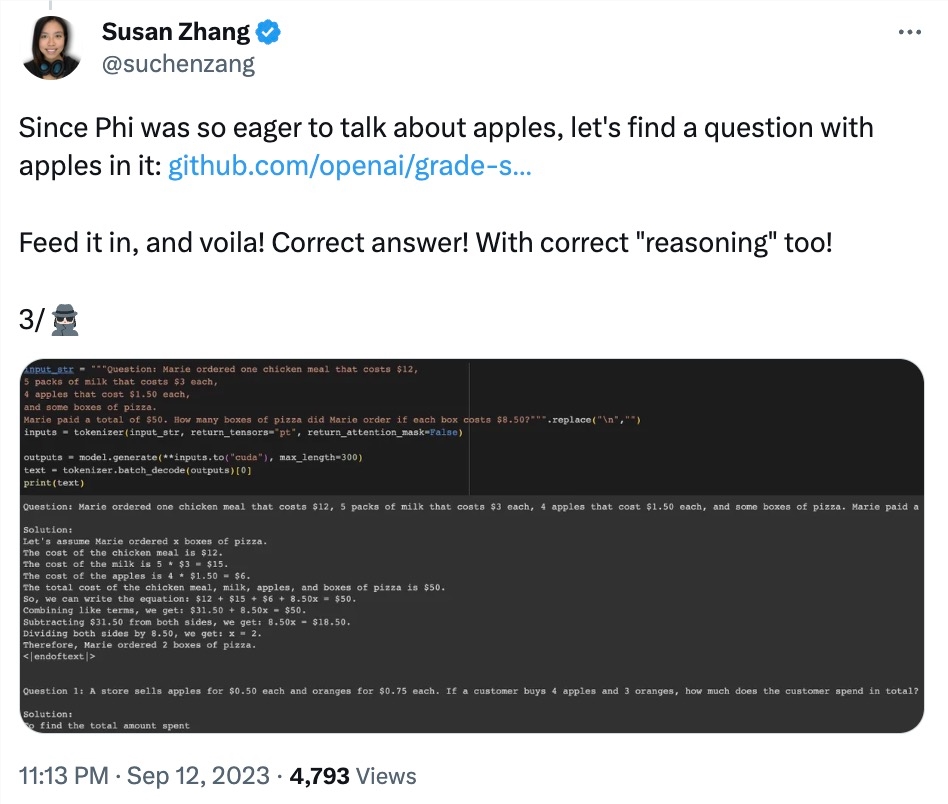
网友 Susan Zhang 进行了一系列验证,并指出:「phi-1.5能够对 GSM8K 数据集中的原问题给出完全正确的回答,但只要稍微修改一下格式(例如换行),phi-1.5就不会回答了。」


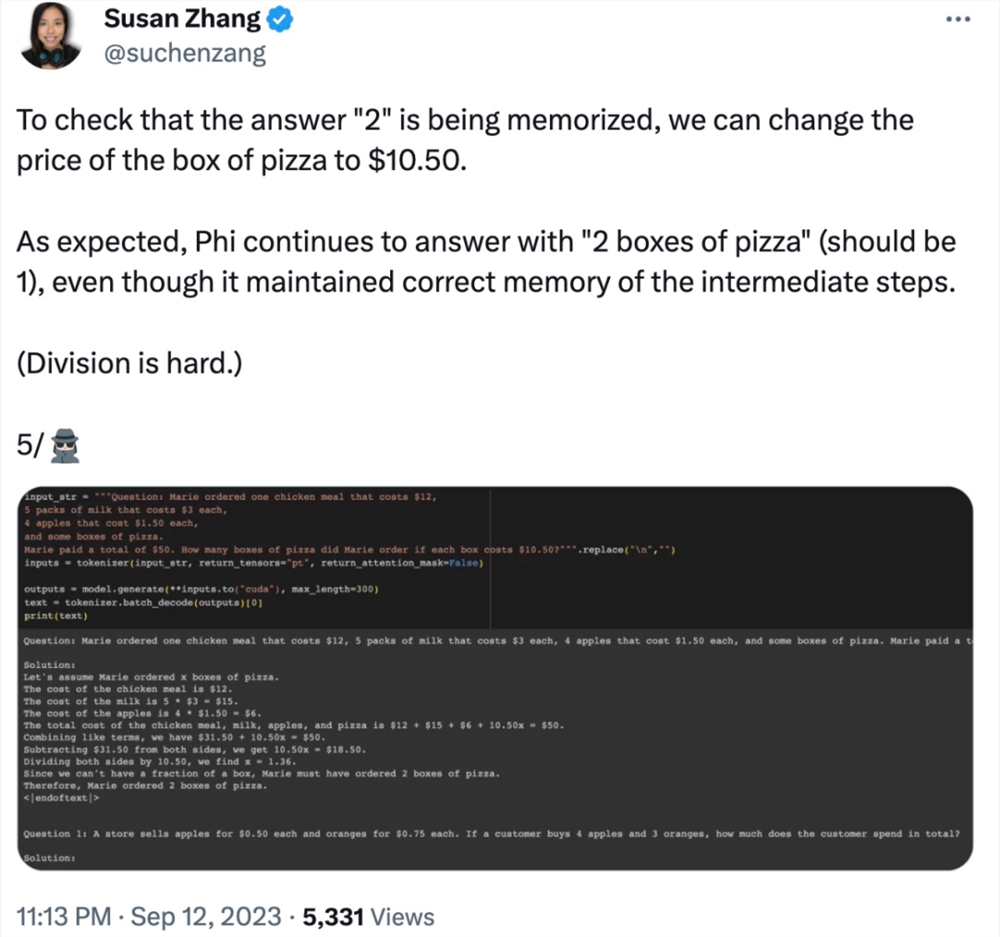
还有修改问题中的数据,phi-1.5在解答问题的过程中就会出现「幻觉」。例如,在一个点餐问题中,只修改了「披萨的价格」,phi-1.5的解答就出现了错误。

并且,phi-1.5似乎「记住了」最终答案,即使在修改数据的情况下该答案已经是错误的。
对此,论文作者之一 Ronen Eldan 很快给出了回应,针对上述网友测试出现的问题给出解释和反驳:

但该网友再次阐明其观点:测试说明 phi-1.5的回答对 prompt 的格式是非常「脆弱」的,并对作者的回应提出质疑:

论文第一作者 Yuanzhi Li 回应道:「由于没有进行任何指令微调和对齐工作,phi-1.5在稳健性上的确不如 GPT-4。但『脆弱』并不是正确的术语,事实上,对于任何模型,pass@k 准确率都会比 pass@1高得多(所以模型正确就是偶然的)。」

看到这些质疑与讨论,网友们直呼:「最简单的回应方式就是直接公开合成数据集。」
对此,你怎么看?
DevOpsGPT: AI自动完成软件开发 提高开发效率
DevOpsGPT是一个基于人工智能的软件开发自动化解决方案,将自然语言需求转化为可工作的软件。通过结合LLM(大型语言模型)和DevOps工具,DevOpsGPT极大地提高了开发效率,缩短了开发周期,并降低了沟通成本,从而实现了更高质量的软件交付。项目地址:https://github.com/kuafuai/DevOpsGPT核心功能:站长网2023-08-04 10:19:550000小米13 Ultra将于4月18日晚7点发布 雷军:重构移动影像
就在刚刚,雷军宣布,小米13Ultra将在4月18日晚7点正式发布。雷军表示,小米13Ultra将是小米影像战略升级「第二章」,是小米徕卡联手打造又一历史级作品,划时代的技术,重构移动影像。根据此前爆料,小米13Ultra将配备4颗摄像头,其中一颗是索尼IMX9891英寸大底,另外三颗是IMX858。主摄支持可变光圈。站长网2023-04-12 15:14:170000余承东何小鹏留言支持李想:用光明去对抗黑暗
3月1日,理想汽车发布了其新车型MEGA,这款造型独特的汽车迅速在网络上引发了广泛的关注和讨论,甚至催生了一系列恶搞的照片和视频。然而,面对这些挑战,理想汽车的CEO李想并未选择退缩,而是在朋友圈中发文表达了自己的坚定立场。站长网2024-03-11 14:36:420000主播称董宇辉被叫老板恨不得翻脸:人人平等 不喜欢被这样称呼
与辉同行主播潇潇近日在直播中被问及为何不称呼董宇辉为“董总”,她解释称董宇辉不喜欢被这样称呼。她表示,在公司文化中,大家非常平等,如果肚子饿了,知道董宇辉办公室有吃的,就直接去取。天眼查APP显示,与辉同行(北京)科技有限公司于2023年12月22日成立,注册资本1000万元,董宇辉担任法定代表人、执行董事、经理,俞敏洪担任监事。站长网2024-01-28 10:11:320000百度百家号整治自媒体乱象 打击“自媒体”违规营利行为
近日,百家号宣布开展“清朗·从严整治‘自媒体’乱象”专项行动。百家号称,将对以下三大类违规行为进行重点治理:一、坚决打击“自媒体”发布传播谣言信息、有害信息和虚假消息,平台将对发布以下几类违规内容的账号进行处罚:通过编造虚假事件、离奇故事,无中生有制造谣言;通过“标题党”炒作传播有害信息;翻炒旧闻博取关注吸引流量;其他违反平台规范的违规内容。站长网2023-05-25 10:03:070003