腾讯 AI Lab联合多家学术机构发布大模型幻觉问题评估
要点:
1、大模型幻觉主要分为与输入、上下文及事实冲突的三类,研究热点在第三类。
2、相比传统模型,大模型幻觉评估面临数据规模大、通用性强、不易察觉等新难题。
3、缓解幻觉可从预训练、微调、强化学习、推理等方面入手,但仍有可靠评估等挑战。
近年来,大规模语言模型在许多下游任务上表现强劲,但也面临着一定的挑战。其中,大模型生成的与事实冲突的“幻觉”内容已成为研究热点。近期,腾讯 AI Lab 联合国内外多家学术机构发布了面向大模型幻觉工作的综述,对幻觉的评估、溯源、缓解等进行了全面的探讨。
论文链接:https://arxiv.org/abs/2309.01219
Github 链接:https://github.com/HillZhang1999/llm-hallucination-survey
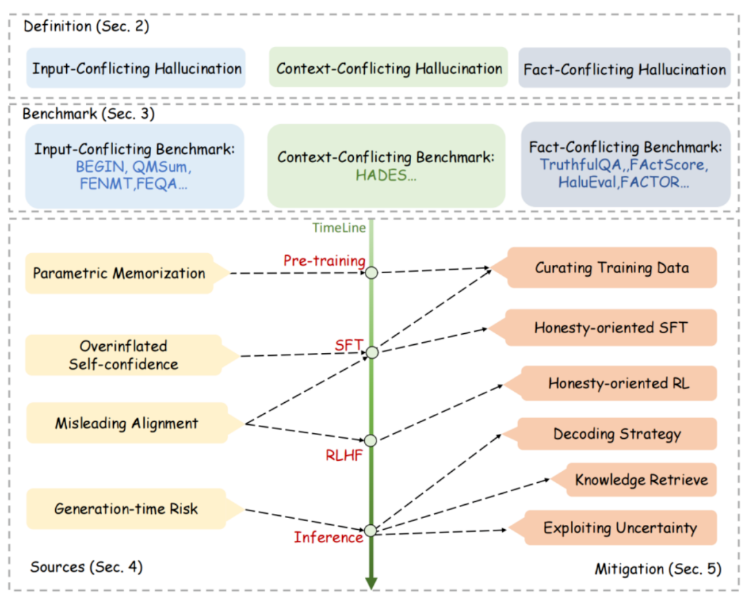
研究者根据大模型幻觉与用户输入、模型生成内容及事实知识的冲突,将其分为三大类。目前研究主要集中在与事实知识冲突的幻觉上,因为这最易对用户产生误导。与传统语言生成任务中幻觉问题不同,大模型幻觉面临数据规模巨大、模型通用性强以及幻觉不易被察觉等新难题。
针对大模型幻觉的评估,已提出多种生成式和判别式的基准,以问答、对话等不同任务形式检验模型的幻觉倾向。这些基准各自设计了判定幻觉的指标,但可靠的自动评估仍有待探索。分析认为,海量低质训练数据以及模型对自身能力的高估是导致幻觉的重要原因。
为减少幻觉,可从预训练、微调、强化学习等多个阶段进行干预。预训练可关注语料质量;微调可人工检查数据;强化学习可惩罚过度自信的回复。此外推理阶段,也可通过解码策略优化、知识检索、不确定度测量等方式缓解幻觉。尽管取得一定进展,可靠评估、多语言场景、模型安全性等方面仍存在诸多挑战。总体来说,大模型幻觉的评估与缓解仍有待深入研究,以促进大模型的实际应用。
综艺抢人抢广告主,爱奇艺腾讯视频对垒
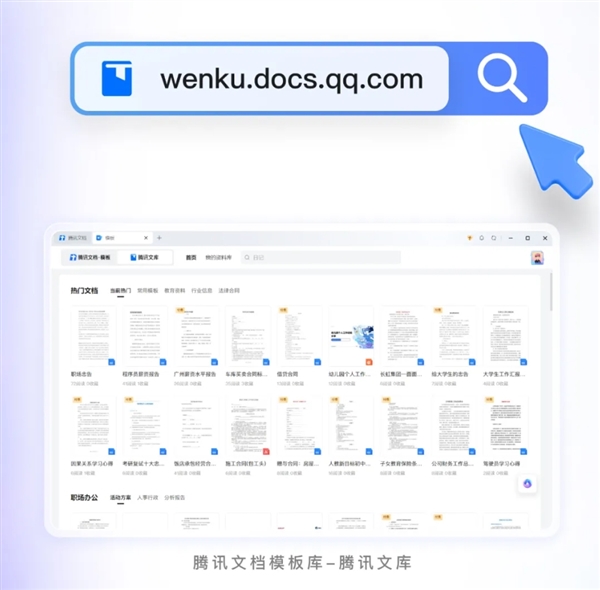
长视频平台的综艺大战,愈演愈烈。8月16日,爱奇艺单口喜剧竞演节目《喜剧之王单口季》正式开播,四天之后,腾讯视频脱口秀节目《脱口秀和Ta的朋友们》也官宣上线。综艺战事升级,两大长视频平台在脱口秀节目上演正面对垒。0001腾讯文库正式发布:汇集亿级专业文档 一键转文档编辑
快科技8月30日消息,腾讯今晚突然正式发布了一款重磅新品腾讯文库。腾讯号称为专业权威的内容消费与发布平台”,汇集海量优质内容,覆盖众多专业领域,无论是考试真题、法律合同还是求职简历都能快速找到。同时还搭载AI智能助手助力,支持一键总结、生成思维导图,快速掌握内容大纲。针对内容创作方面,腾讯文库还支持AI辅写。腾讯文库还可以无缝融合腾讯文档,随时随地点击即用。站长网2024-08-31 16:53:300000阿里魔搭社区开源知识检索模型Ziya-Reader
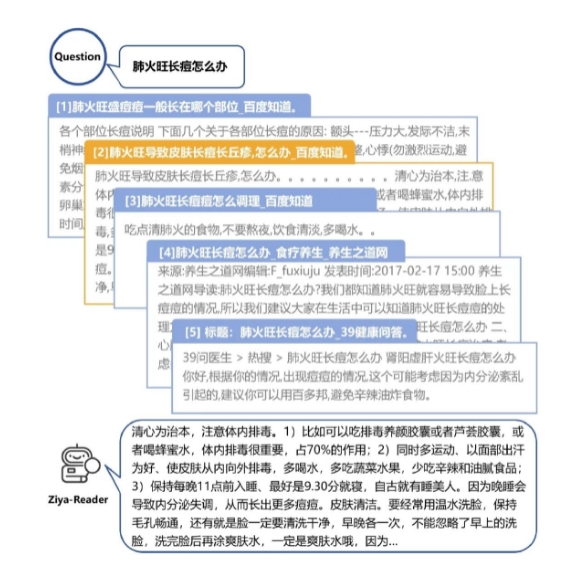
阿里魔搭社区宣布开源Ziya-Reader。Ziya-Reader是一个针对知识检索的开源模型。当前大模型在处理多文档任务时,如果正确答案不在第一个或末尾的文档中,准确率会急剧下降。为了解决这个问题,Ziya-Reader应运而生,它可以从多个候选中找到正确的答案。站长网2023-10-16 11:09:310000实时翻译工具Byrdhouse AI 可在视频通话中翻译100多种语言
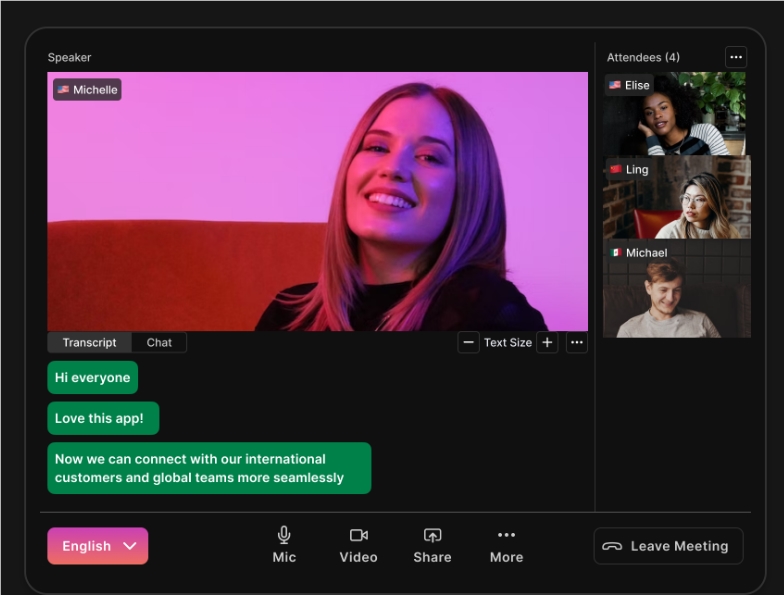
ByrdhouseAI是一个强大的工具,可以在视频通话中实时翻译100多种语言。它提供了语音翻译字幕和AI驱动的实时口译功能,让用户在会议或聊天中可以将自己的语言转换成另一种语言。此外,用户还可以选择翻译的声音是男声还是女声。体验地址:https://top.aibase.com/tool/byrdhouse站长网2024-01-17 14:22:490000我们花一个月调研了小红书种草的新机会和增长策略
随着618的临近,小红书再次成为了品牌重要的“营销战场”。面临着经济环境的不确定性,想必各大品牌都非常关注小红书种草的增长策略,希望能够挖掘出更多的增量空间。于是,我们最近启动了一个小红书种草的专项研究,通过一个月时间追踪平台的数据趋势、调研最佳实践案例,覆盖美妆、母婴、3C、服装等15个主流类目,探索了当前的挑战和创新的机会在哪里。以下为核心观点摘要1.“11”现状:挑战背后也有机遇站长网2023-05-17 17:15:290000