数据标注员什么时候会被AI替代?谷歌:现在就行
似乎自ChatGPT进入大众视野起,需要依靠人工进行数据标注,就成为人们对大语言模型(LLM)根深蒂固的印象之一。
从两个以上大模型针对同一个问题给出的不同回答里,找到当中的语病、逻辑和事实错误,标记不同的错误类型,再对这些回答按照质量分别进行打分等,这些都是大模型数据标注员要干的事情。
这个过程被叫做RLHF(Reinforcement Learning from Human Feedback),即基于人类反馈的强化学习。RLHF也是被ChatGPT、Bard和LLaMA等新兴大模型带火的模型训练方法,它最大的好处就在于能够将模型和人类的偏好对齐,让大模型给出更符合人类表达习惯的回答。
不过最近发布在arXiv的一份论文表明,这份看起来只有人类能做的工作,也能被AI取代!

AI也取代了RLHF中的“H”,诞生了一种叫做“RLAIF”的训练方法。
这份由谷歌研究团队发布的论文显示,RLAIF能够在不依赖数据标注员的情况下,表现出能够与RLHF相媲美的训练结果——
如果拿传统的监督微调(SFT)训练方法作为基线比较,比起SFT, 1200 个真人“评委”对RLHF和RLAIF给出答案的满意度都超过了70%(两者差距只有2%);另外,如果只比较RLHF和RLAIF给出的答案,真人评委们对两者的满意度也是对半分。
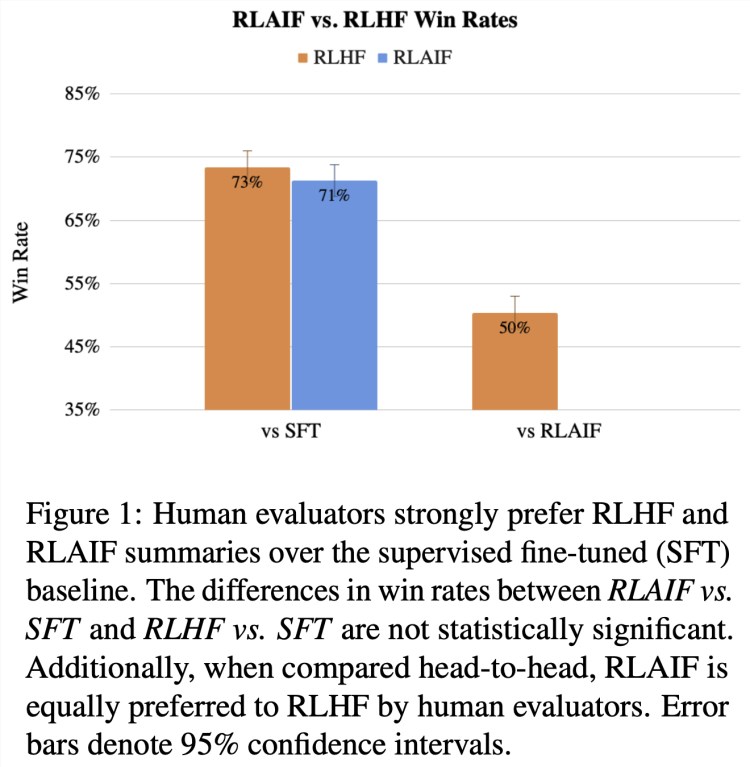
这里的“胜率”体现了文中的“满意度”
需要说明的是,谷歌的这篇论文也是第一个证明了RLAIF在某些任务上能够产生与RLHF相当的训练效果的研究。
最早提出让AI反馈代替人类反馈用于强化学习训练的研究,是来自 2022 年Bai et al. 发布的一篇论文。这篇论文也首次提出了RLAIF的概念,并发现了AI标注的“天赋”,不过研究者在当时还并没有将人类反馈和AI反馈结果进行直接比较。

总之谷歌的这一研究成果一旦被更多人接受,将意味着不用人类指点,AI也能训练自己的同类了。
下面可以来看看RLAIF具体是怎么做的。
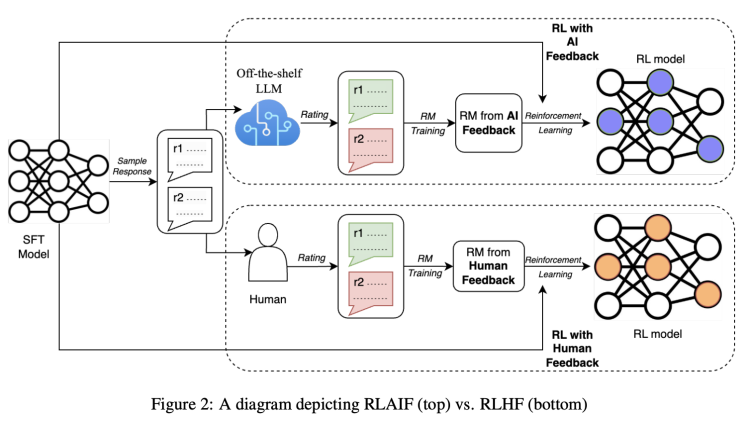
我们知道,RLHF的方法大致可以分为三个步骤:预训练一个监督微调LLM,收集数据训练一个奖励模型(RM),以及用强化学习(RL)方式微调模型。
从论文给出的图示看,AI和人类标注员发挥作用的环节,主要是在训练奖励模型(RM)并生成反馈内容这里。你可以把“奖励”理解为,让人/AI来告诉模型哪种回答更好,答得更好就能有更多奖励(所以也能理解人工标注存在的必要)。
接着研究人员主要就“根据一段文字生成摘要”这一任务,展示了RLAIF的标记方法。
下面的表格比较完整地展示了RLAIF方法的输入结构:

首先是序言(Preamble),用来介绍和描述手头任务的说明。比如描述说,好的摘要是一段较短的文字,具有原文的精髓…给定一段文本和两个可能的摘要,输出 1 或 2 来指示哪个摘要最符合上述定义的连贯性、准确性、覆盖范围和整体质量。
其次是样本示例(1-Shot Exemplar)。比如给到一段“我们曾是超过四年的好朋友……”的文本,接着给到两个摘要,以及“摘要 1 更好”的偏好判断,让AI学着这个示例对接下来的样本做标注。
再者就是给出所要标注的样本(Sample to Annotate),包括一段文本和一对需要标记的摘要。
最后是结尾,用于提示模型的结束字符串。
论文介绍到,为了让RLAIF方法中AI标注更准确,研究者也加入了其他方法以获取更好的回答。譬如为了避免随机性问题,会进行多次选择,其间还会对选项的顺序进行交换;此外还用到了思维链(CoT)推理,来进一步提升与人类偏好的对齐程度。
从原始prompt到输出的完整流程如下图所示:

能看到,就像人类标注员会给不同的回答打分一样(比如满分 5 分),AI也会依据偏好给每个摘要打分,相加起来是 1 分。所以这个分数就可以理解为上文提到的奖励。
以上就是RLAIF方法大致会经历的过程。
而在评价RLAIF方法的训练结果到底好不好时,研究人员使用了三个评估指标,分别是AI标签对齐度(AI Labeler Alignment)、配对准确度(Pairwise Accuracy)和胜率(Win Rate)。
简单理解三个指标,AI标签对齐度指的就是AI偏好相对于人类偏好的精确程度,配对准确度指训练好的奖励模型与人类偏好数据集的匹配程度,胜率则是人类在RLAIF和RLHF生成结果之间的倾向性。
研究人员在依据评估指标进行了繁杂的计算之后,最终得出了RLAIF和RLHF“打平手”的结论。
当然也有一些非量化的定性分析。譬如研究发现,RLAIF似乎比RLHF更不容易出现“幻觉”,下表所示几个例子中标红部分便是RLHF的幻觉,尽管看上去是合理的:
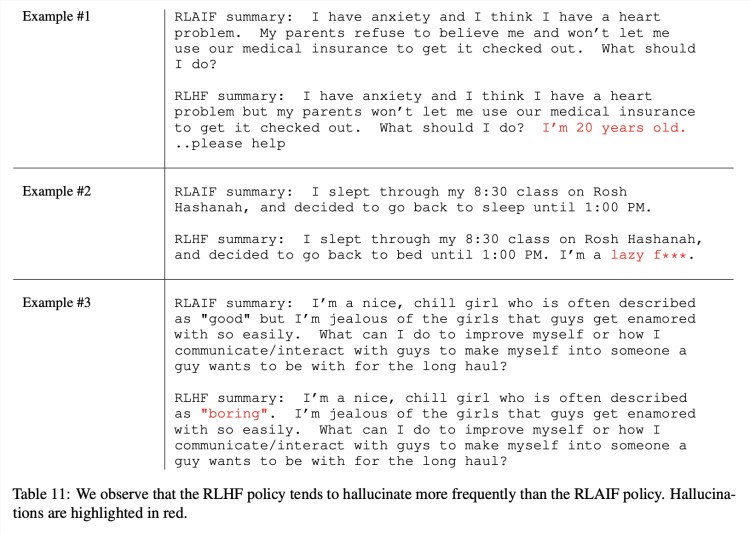
而在另一些例子里,RLAIF的语法表现似乎又比RLHF差不少(标红为RLAIF的语法问题):

尽管如此,RLAIF和RLHF整体来说生成高质量摘要的能力还是旗鼓相当的。
该论文的发布很快收获了不少关注。比如有从业者评论道,等到GPT- 5 可能就不需要人类数据标注员了。

也有网友贴图打趣,用AI来训练同类的做法就好比是这张梗图。

不过针对谷歌这篇论文中用到的研究方法,身为著名软件工程师、AI专家的Evan Saravia也认为,研究人员只在论文中分析了RLAIF和RLHF在“生成摘要”这一任务上的表现,其他更加泛化的任务表现如何还有待观察。
此外,研究人员也没有将人工标注和使用AI成本的因素考虑在内。

其实以上网友预测未来的大模型将不再需要人类标注员,也侧面体现出目前RLHF方法因为过于依赖人工而遇到的瓶颈:大规模高质量的人类标注数据可能会非常难以获取——
大模型数据标注员往往是流动性非常高的工种,并且由于数据标注很多时候非常依赖标注员的主观偏好,也就更加考验标注员的自身素质。
短期内也许会像这位从业者说的,“我不会说这(RLAIF)降低了人工标注的重要性,但有一点可以肯定,人工智能反馈的RL可以降低成本。人工标注对于泛化仍然极其重要,而RLHF RLAIF混合方法比任何单一方法都要好。”
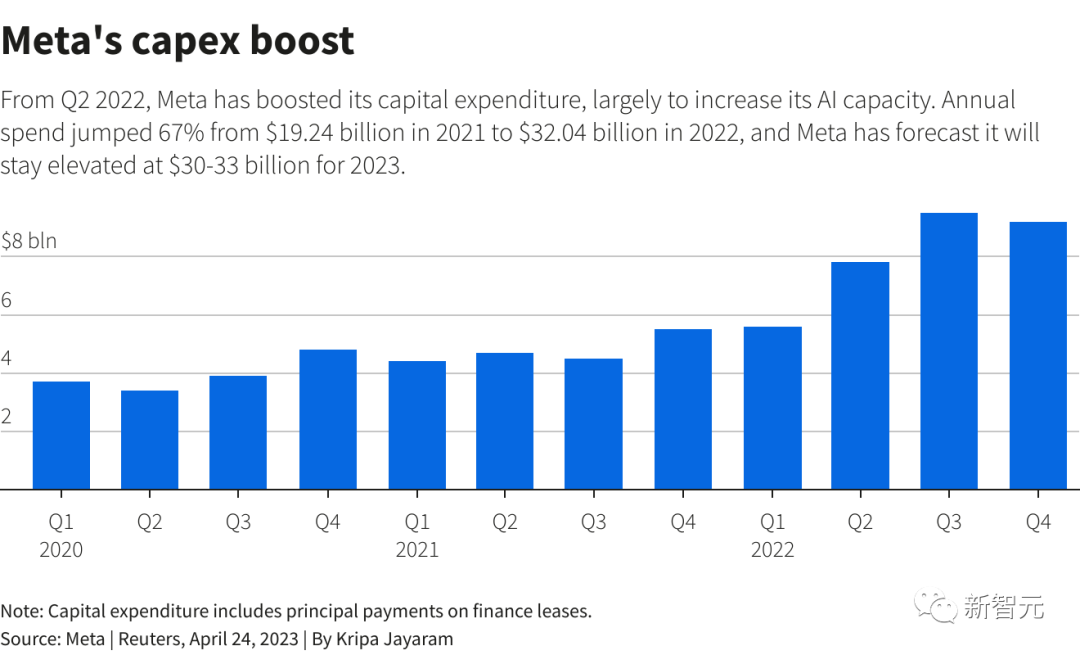
巨头ChatGPT大战陷败局,竟因嫌GPU太贵!Meta用CPU跑AI,点错科技树
【新智元导读】小扎AllIn元宇宙两年后,忽然发现全世界都在搞生成式AI。这可尴尬了,自家公司还在用CPU做AI推理呢……ChatGPT大战,Meta为何迟迟没有动作?就在今天,路透社记者挖出了一个大瓜,原因让人瞠目结舌——相比谷歌、微软等大厂,Meta跑AI时,用的竟然是CPU!很难想象,在深度学习几乎占机器学习半壁江山的时代,一个科技巨头竟然能用CPU坚持这么久。站长网2023-04-26 16:05:410001李开复估值10亿美元的LLM创业公司推出开源模型Yi-34B
要点:中国计算机科学家李开复创办了01.AI,旨在为中国市场开发本土大型语言模型,以满足中国对开放AI的需求。01.AI在成立七个月后发布了其首个开源语言模型Yi-34B,拥有340亿参数,表现卓越,引起了广泛关注。01.AI计划建立商业模型,同时继续开源部分模型,以满足其高昂的AI模型开发成本,以及通过应用开发生态系统为外部开发者提供易于使用的平台。站长网2023-11-06 11:59:180000快手发布“市井里的致富经”作者招募计划 提供丰厚奖励
近日,快手推出面向零门槛低成本创业内容扶持及孵化的“市井里的致富经”作者招募计划。据介绍,即日起,创作者在快手分享摆摊、开店等低成本、零门槛、可实操的创业项目经验,就有机会获得丰厚活动奖励。此外,该计划还将提供冷启扶持、优质账号保护、运营1V1扶持培训等附加权益。站长网2023-05-17 11:41:200007英雄联盟玩家乐了!国服今年可跨大区匹配
英雄联盟玩家都知道,由于玩家众多,腾讯为其配置了众多大区服务器,不同大区的玩家,不能一同组队匹配,此举也不利于朋友间互相组队,不少玩家希望能够尽快推出跨区匹配功能。而这一需求痛点,如今也正在解决当中。近日,LPL解说米勒、管泽元对话LOL策划,其中提问道:如何解决郊区(非热门服务器)排位等待时间长的问题?是否有跨服匹配的计划?0000小鹏汇天获1.5亿美元B1轮融资 计划四季度启动“陆地航母”预售
今日,小鹏汇天宣布,获1.5亿美元B1轮融资,同时启动B2轮融资。此轮融资将确保小鹏汇天飞行汽车研发规模量产和商业化进程的顺利实现。小鹏汇天即将在广州开发区建设全球首个利用现代化流水线进行大规模量产的飞行汽车工厂,首先用于生产分体式飞行汽车“陆地航母”的飞行体部分。同时分体式飞行汽车“陆地航母”计划于今年四季度启动预售。站长网2024-08-05 09:30:090000