最先进的开源预训练大语言模型Lemur 平衡文本和代码功能
文章要点:
Lemur是首个在文本和代码任务上都表现卓越的开源预训练语言模型。
Lemur通过在大规模代码集上预训练,在文本理解和知识任务上保持竞争力的同时,在编程基准测试上超过其他模型。
Lemur填补了语言模型中文本和代码能力之间的空白,推动了开源LLM的发展。
随着语言和技术交叉的日益增多,对多功能和强大语言模型的需求也越来越大。传统的大型语言模型(LLMs)在文本理解或编码任务方面表现出色,但很少能够在两者之间达到平衡。这种不平衡为模型在文本推理和编码能力之间无法无缝切换留下了一定的空间。因此,Lemur和Lemur-chat应运而生,这两个开放预训练和监督微调LLMs的开创性贡献旨在弥合这一差距。
创建既能够熟练处理文本又能够处理代码的语言模型一直是一个长期存在的挑战。现有的LLMs通常专门用于文本理解或编码任务,但很少同时具备两者。这种专业化使得开发人员和研究人员需要在在两者之间进行选择。因此,需要一种LLMs,它能够提供全面的技能集,包括理解、推理、规划、编码和上下文基础。
项目地址:https://github.com/OpenLemur/Lemur
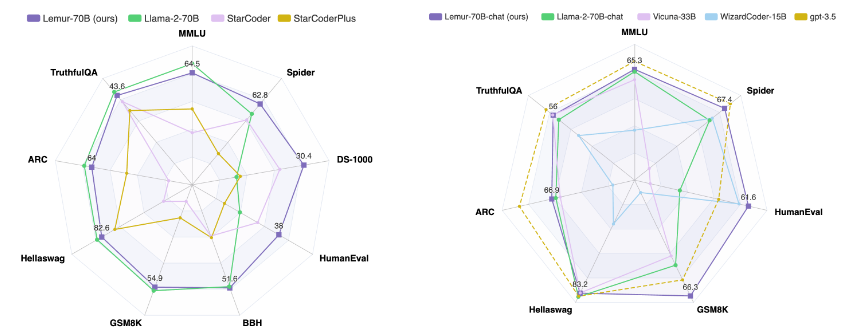
Lemur项目是由XLang Lab与Salesforce Research合作推出的,旨在解决语言模型技术中的关键差距。Lemur和Lemur-chat代表了一项开创性的努力,旨在开发开放的、预训练的和监督微调LLMs,其在文本和代码相关任务方面表现出色。这项工作的基石是对Llama2进行广泛的预训练,涉及约1000亿行代码密集型数据的大量语料库。这个预训练阶段之后是在约30万个公共教学和对话数据实例上进行的监督微调。结果是一个语言模型,具有增强的编码和基础能力,同时保持着竞争性的文本推理和知识性能。
Lemur和Lemur-chat的性能指标证明了它们的实力。Lemur在编码基准测试中超过了其他开源语言模型,证明了它的编码能力。同时,它在文本推理和知识性能方面保持了竞争优势,展示了它的多功能技能集。与此同时,Lemur-chat在各个方面显著优于其他开源监督微调模型,表明它在桥接对话环境中文本和代码之间的差距方面具有出色的能力。
Lemur项目是XLang Lab和Salesforce Research的协作研究成果,得到了Salesforce Research、Google Research和Amazon AWS的慷慨赠礼的支持。虽然朝着一个平衡的开源语言模型的旅程仍在持续,但Lemur的贡献已经开始重塑语言模型技术的格局。通过提供在文本和代码相关任务方面表现出色的模型,Lemur为寻求在语言和技术交叉领域中导航的开发人员、研究人员和组织提供了一个强大的工具。
总之,Lemur项目是语言模型领域创新的标志。它能够和谐地平衡文本和代码相关任务,解决了该领域长期存在的挑战。随着Lemur的不断发展和设立新的基准,它将推动代理模型的进一步研究,并为开源语言模型建立更强大和平衡的基础。有了Lemur,语言模型技术的未来将比以往任何时候都更加光明和多功能。
竞逐AI Agent时代
什么是更接近AGI的形态,是能用脑子思考的大模型,还是能用行动互动的Agent?随着技术不断进步,应用不断落地,人与机器的互动方式正在发生范式转变,这个答案成了两者的结合——AIAgent。AIAgent,又被称作是AI智能体,即一种能通过对环境的感知,进行思考决策并执行的智能体。与GPT等应用相比,AIAgent在思考与行动方式上和人类很相似,是人工智能机器人的初级形态。0000尴尬!谷歌手动删除搜索中奇怪的 AI 回答
划重点:-谷歌的AIOverview产品在推出时出现了一些怪异回答,导致谷歌需要手动禁用特定搜索的AIOverviews。-一些用户在社交媒体上发布了各种有趣的回答,但很快就被删除。-这个失误显示了AI领域竞争的艰难性,以及在AI技术完善之前进行优化的风险。站长网2024-05-27 14:56:160000闲鱼回应多用户未经本人允许挂售同事:不可售卖非个人资产
近日,闲鱼平台上出现了一股独特的“售卖”风潮,用户们纷纷将自己的公司、工作甚至同事作为折扣商品上架,引起了广泛关注。这些商品的售价从9.9元到80000元不等,数量已超过500条。站长网2024-06-12 15:55:300001售价超2万5!苹果内部员工测试Vision Pro:都说太重了
快科技6月27日消息,MarkGurman透露,苹果公司让内部员工体验VisionPro,一些员工在使用几个小时后反映设备太重了”。虽然苹果未公布VisionPro的具体重量,但是从它使用的金属铝、玻璃等材质来看,这款空间计算设备的重量一定不低。站长网2023-06-27 17:06:530000陪娃写作业不崩溃的家长,都在用AI神器
要问“家有神兽”的父母们,最着急上火、容易情绪崩溃的场景是什么?辅导孩子写作业,恐怕是最有共鸣的答案了。不知从什么时候起,网上开始流行各种陪娃写作业的心酸视频,最典型的是“渐崩式辅导作业”,起初父母都是心平气和的,慢慢地,开始气火攻心,对孩子又吼又叫。0001











