谷歌证实大模型能顿悟,特殊方法能让模型快速泛化,或将打破大模型黑箱
【新智元导读】谷歌团队认为,模型泛化能力无处不在,只要摸清条件,模型就不是随机鹦鹉。
在特定情况下,人工智能模型会超越训练数据进行泛化。在人工智能研究中,这种现象被称为「顿悟」,而谷歌现在正在提供对最近发现的深入了解。
在训练过程中,人工智能模型有时似乎会突然「理解」一个问题,尽管它们只是记住了训练数据。在人工智能研究中,这种现象被称为「顿悟」,这是美国作家Robert A. Heinlein创造的一个新词,主要在计算机文化中用来描述一种深刻的理解。
当人工智能模型发生顿悟时,模型会突然从简单地复制训练数据转变为发现可推广的解决方案——因此,你可能会得到一个实际上构建问题模型以进行预测的人工智能系统,而不仅仅是一个随机的模仿者。
谷歌团队:「顿悟」是一种「有条件的现象」
「顿悟」在希望更好地理解神经网络学习方式的人工智能研究人员中引起了很大的兴趣。这是因为「顿悟」表明模型在记忆和泛化时可能具有不同的学习动态,了解这些动态可能为神经网络学习提供重要见解。
尽管最初是在单个任务上训练的小型模型中观察到,但谷歌的最新研究表明,顿悟也可以发生在较大的模型中,并且在某些情况下可以被可靠地预测。然而,在大型模型中检测这种顿悟动态仍然是一个挑战。
在这篇文章中,谷歌研究人员提供了有关这一现象和当前研究的视觉展示。该团队对超过1000个不同训练参数的小型模型进行了算法任务的训练,展示了「有条件的现象——如果模型大小、权重衰减、数据大小和其他超参数不合适,这种现象会消失。」
了解「顿悟」可能会改进大型AI模型
根据该团队的说法,仍然有许多未解之谜,例如哪些模型限制会可靠地引起「顿悟」,为什么模型最初更喜欢记住训练数据,以及研究中用于研究小型模型中这一现象的方法在大型模型中是否适用。
对「顿悟」的理解进步可能会为未来大型AI模型的设计提供信息,使它们能够可靠且快速地超越训练数据。

在2021年,研究人员在对一系列微型模型进行玩具任务训练时发现:一组模型,在经过更长时间的训练后,突然从仅仅「记住」之前的训练数据,转变为在未见过的输入上表现出正确的泛化能力。
这种现象被称为「顿悟」,并引发了一系列的兴趣和研究。
更复杂的模型是否也会在经过更长时间的训练后突然表现出泛化能力呢?
大型语言模型看起来似乎具有很强的对外部世界的理解能力,但可能模型只是在重复记忆训练过的海量文本数据的片段,而没有真正理解其内容。
到底如何判断它们是在泛化还是在记忆?
在这篇文章中,研究人员将研究一个微型模型的训练动态过程,并对其找到的解决方案进行逆向工程——在此过程中,研究人员将阐述这个令人振奋的新兴机制中那些能被研究人员理解的部分。
虽然如何将这些技术应用于当今最大的模型,现在还没有头绪。但从小模型入手可以更容易地培养直觉,随着研究人员的逐步努力,关于大型语言模型的这些关键问题也将最终获得解答。
顿悟模加法
模加法是检测「顿悟」最好的方法。
(模加法指的是两个数据相加,如果合大于某一个值,结果就自动回归某一个值。以12小时计时为例,时间相加超过12点之后就会自动归零,就是一个典型的模加法。)
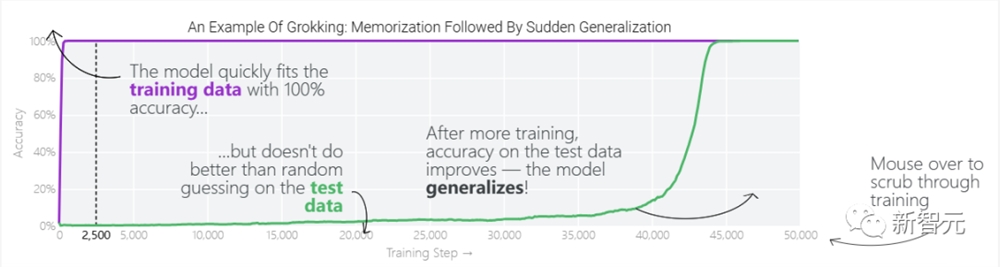
突然的泛化往往发生在在对于训练数据的记忆之后,模型一开始的输出与训练数据吻合,但随着训练不断持续,和测试数据的吻合度不断提高,出现了泛化。这个过程就叫做「顿悟」
上图来自于一个被训练来进行预测a b mod67(即a b的合超过67之后就会归零的模加法)的模型。
研究人员首先随机将所有成对数据分成测试数据集和训练数据集。
在训练过程中,训练数据被用来调整模型,让模型输出正确答案,而测试数据仅用于检查模型是否已经学会了一个通用的解决方案。
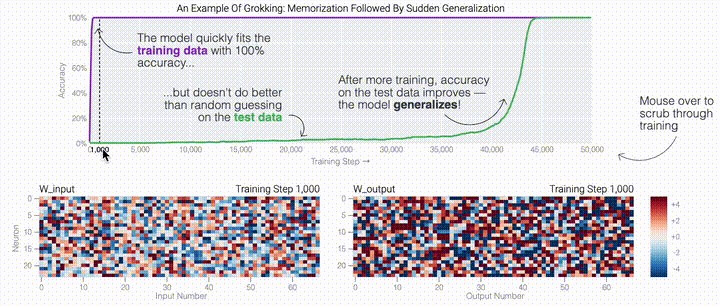
模型的架构也很简单:
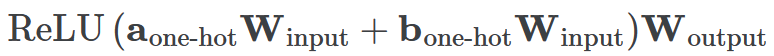
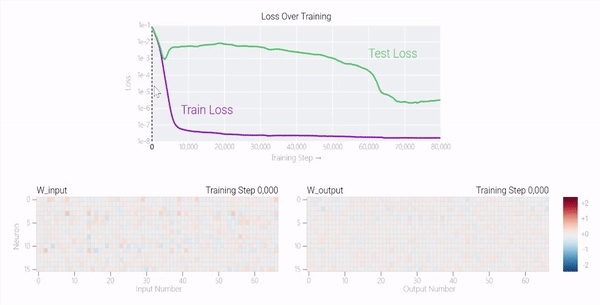
一个具有24个神经元的单层MLP。模型的所有权重如下面的热图所示;通过将鼠标悬停在上面的线性图上,可以看到它们在训练过程中如何变化。
模型通过选择与输入a和b对应的两列

,然后将它们相加以创建一个包含24个独立数字的向量来进行预测。接下来,它将向量中的所有负数设置为0,最后输出与更新向量最接近的
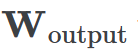
列。
模型的权重最初非常嘈杂,但随着测试数据上的准确性提高和模型逐渐开始泛化,它们开始展现出周期性的模式。
在训练结束时,每个神经元,也就是热图的每一行在输入数字从0增加到66时会多次在高值和低值之间循环。
如果研究人员根据神经元在训练结束时的循环频率将其分组,并将每个神经元分别绘制成一条单独的线,会更容易看出产生的变化。
这些周期性的模式表明模型正在学习某种数学结构;当模型开始计算测试样本时出现这种现象,意味着模型开始出现泛化了。
但是为什么模型会抛开记忆的解决方案?而泛化的解决方案又是什么呢?
在0和1的数列中训练模型泛化
同时解决这两个问题确实很困难。研究人员可以设计一个更简单的任务,其中研究人员知道泛化解决方案应该是什么样的,然后尝试理解模型最终是如何学习它的。
研究人员又设计了一个方案,他们先随机生成30个由0和1组成的数字组成一个数列,然后训练一个模型去预测数列中前三个数字中是否有奇数个1,如果有奇数个1,输出就为1,否则输出为0。
例如,010110010110001010111001001011等于1。
000110010110001010111001001011等于0。
基本上这就是稍微复杂一些的异或运算,略微带有一些干扰噪声。
而如果一个模型产生了泛化能力,应该就只关注序列的前三位数字进行输出;如果模型是在记忆训练数据,它就会使用到后边的干扰数字。
研究人员的模型仍然是一个单层MLP,使用固定的1,200个序列进行训练。
起初,只有训练数据准确性增加了,说明模型正在记忆训练数据。
与模算数一样,测试数据的准确性一开始基本上是随机的。
但是模型学习了一个泛化解决方案后,测试数据的准确性就急剧上升。

下面的权重图标显示,在记忆训练数据时,模型看起来密集而嘈杂,有许多数值很大的权重(显示为深红色和蓝色方块)分布在数列靠后的位置,表明模型正在使用所有的数字进行预测。
随着模型泛化后获得了完美的测试数据准确性,研究人员看到,与干扰数字相关的所有权重都变为灰色,值非常低,模型权重全部集中在前三位数字上了。
这与研究人员预期的泛化结构相一致。

通过这个简化的例子,更容易理解为什么会发生这种情况:
其实在训练过程中,研究人员的要求是模型要同时完成两个目标,一个是尽量高概率地输出正确的数字(称为最小化损失),另一个是使用尽量小的全权重来完成输出(称为权重衰减)。
在模型泛化之前,训练损失略微增加(输出准确略微降低),因为它在减小与输出正确标签相关的损失的同时,也在降低权重,从而获得尽可能小的权重。

而测试数据损失的急剧下降,让模型看起来像是似乎突然开始了泛化,但其实不是,这个过程在之前就已经在进行了。
但是,如果观察记录模型在训练过程中的权重,大部分权重是平均分布在这两个目标之间的。
当与干扰数字相关的最后一组权重被权重衰减这个目标「修剪」掉时,泛化马上就发生了。

何时发生顿悟?
值得注意的是,「顿悟」是一种偶然现象——如果模型大小、权重衰减、数据大小以及其他超参数不合适,它就不会出现。
当权重衰减过小时,模型无法摆脱对训练数据的过拟合。
增加更多的权重衰减会推动模型在记忆后进行泛化。进一步增加权重衰减会导致测试数据和训练数据的不准确率提高;模型直接进入泛化阶段。
当权重衰减过大时,模型将无法学到任何东西。
在下面的内容中,研究人员使用不同的超参数在「1和0」任务上训练了一千多个模型。
因为训练是有噪声的,所以每组超参数都训练了九个模型。

可以看到,这个「1和0」任务模拟出了模型的记忆和泛化,但为什么这种情况会发生在模加法中呢?
首先,让我们更多地了解一层MLP如何通过构建一个可解释的泛化解决方案来解决模加法。
五个神经元的模加法
举个例子,模加法问题a b mod67是周期性的。
从数学上讲,可以将式子的和看成是将a和b绕在一个圆圈上来表示。
泛化模型的权重也具有周期性,也就是说,解决方案可能也会有周期性。

研究人员训练了一个更简单的模型,利用cos和sin构建一个嵌入矩阵,将a和b放在一个圆上。

模型只用了5个神经元就完美地找到了解决方案。
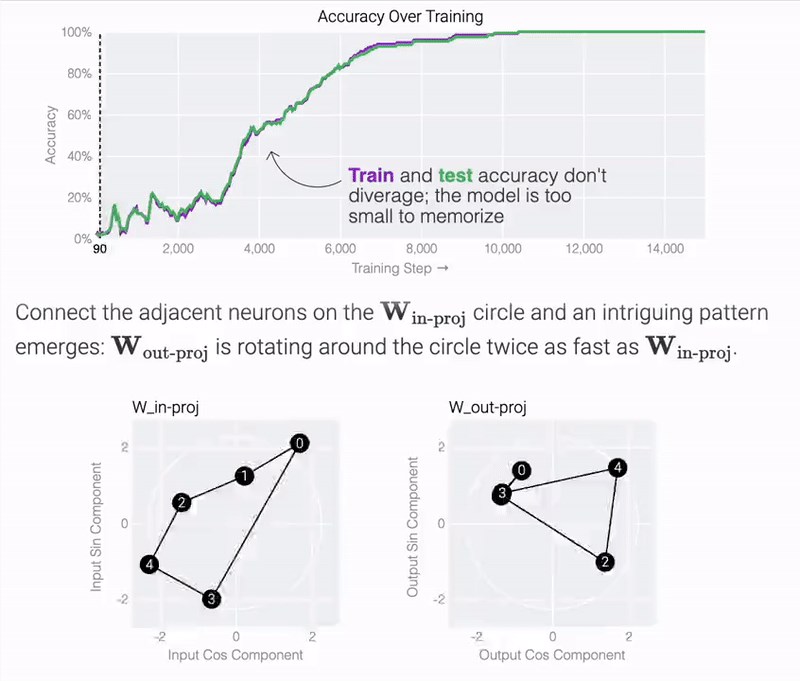
然后还是回到a b mod67的问题上,研究人员从头训练模型,没有内置周期,这个模型有很多频率。
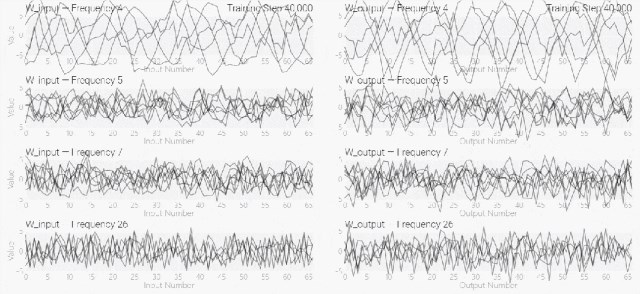
然后研究人员使用离散傅里叶变换分离出频率,会分离出输入数据中的周期性模式。
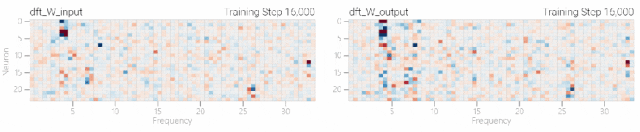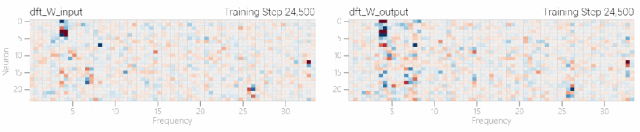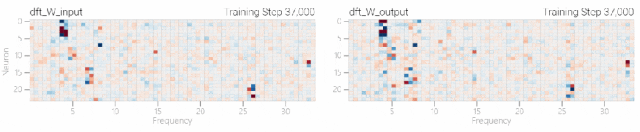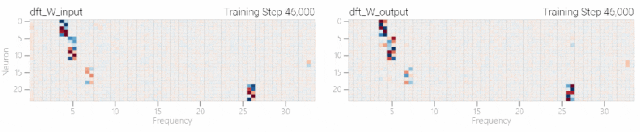
而结果就和之前在数列中数1的任务一样,随着模型的泛化,权重会迅速衰减到很低。
而且在不同的频率任务中,模型也都出现了「顿悟」
进一步的问题
什么原因导致泛化的出现?
虽然研究人员现在对用单层MLP解决模加法的机制以及它们在训练过程中出现的原因有了深入的了解,但仍然存在许多关于记忆和泛化的有趣的悬而未决的问题。
从广义上讲,权重衰减确实会导致多种模型不再记忆训练数据 。
其他有助于避免过度拟合的技术包括 dropout、较小的模型,甚至数值不稳定的优化算法 。
这些方法以复杂、非线性的方式相互作用,使得很难预先预测最终什么原因和方式会导致泛化。

为什么记忆比概括更容易?
一种理论:记忆训练数据集的解决方法可能比泛化解决方法多得多。
因此从统计上看,记忆应该更有可能先发生。
有研究表明泛化与结构良好的表示相关。然而,这不是必要条件;一些没有对称输入的 MLP 变体在求解模加法时学习的「循环」表示较少 。
研究人员还观察到,结构良好的表示并不是泛化的充分条件。
比如这个小模型(没有权重衰减的情况下训练)开始泛化,然后切换到使用周期性嵌入进行记忆。
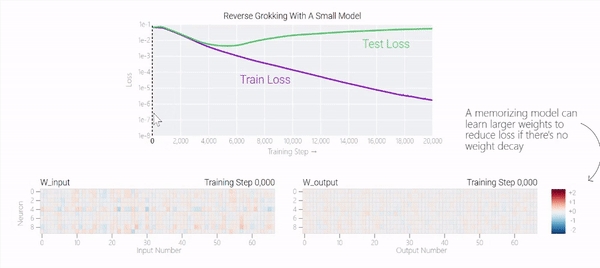
甚至可以找到模型开始泛化的超参数,然后切换到记忆,然后再切换回泛化!
而较大的模型呢?
首先,之前的研究证实了小型Transformer和MLP算法任务中的顿悟现象。
涉及特定超参数范围内的图像、文本和表格数据的更复杂的任务也出现了顿悟
研究人员认为:
1)训练具有更多归纳偏差和更少移动部件的更简单模型,
2)用它们来解释更大模型难以理解的部分是如何工作的
3)根据需要重复。
都可以有效帮助理解更大的模型。
而且本文中这种机制化的可解释性方法可能有助于识别模式,从而使神经网络所学算法的研究变得容易,甚至有自动化的潜力。
参考资料:
https://pair.withgoogle.com/explorables/grokking/
AI涂鸦风靡小红书,草图秒变服装设计稿!网友:AI真的懂我
最近打开小红书,发现被各种涂鸦包围了……小红书@柔随手画的几笔涂鸦,交给AI,然后就变成了服装设计图。小红书@明玥几时有想要在裙子上加玫瑰花,只要画几个红色的圆圈,AI就懂了:小红书@拿辣条辣死你如果你是有点绘画功底的专业人士,精心设计了这样一件优雅的紫色旗袍,那么AI也能帮你生成模特上身图,背景都配好了。小红书@干饭选手又困了0000百度将发布全球首个AI原生地图 百度地图V19版本10月17日推出
百度将在10月17日发布百度地图V19版本,该版本将从“新交互”和“新导航”两个主要方面进行全面升级。其中,最引人注目的是,百度地图V19将基于文心大模型进行重构,并推出全新的“AI向导”。这个“AI向导”拥有多轮自然语言交互能力,使得用户与地图之间的交互体验更加接近真人交流。站长网2023-10-12 17:21:310000?签约OR孵化,MCN机构该如何平衡商业效率?
在刚刚过去的4月,由克劳锐出品的《2023中国内容机构(MCN)行业发展研究白皮书》重磅发布,白皮书在引发业内热议的同时也为中国MCN机构的发展给出了可能的方向。在白皮书发布后,克劳锐以“实现增长,路在何方”为主题发起系列直播,通过对话MCN机构创始人,探讨MCN机构们当前关注的重点行业问题。0000AI日报:Claude上线数据分析功能;KREA AI推出视频延展功能;Midjourney新增图像编辑器;苹果悬赏百万寻找AI漏洞
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、重磅更新!Claude上线数据分析功能,轻松解析数据、自动编写代码!站长网2024-10-25 16:21:000002“你可能患了血癌……” 医生诊断错误,而 ChatGPT 是对的!
皮肤发烫且伴有发热症状,医护人员诊断后称无明显异常,ChatGPT建议可能是“血癌”……站长网2025-04-26 15:56:250000