如何通过集成GPTCache来优化LLM应用的速度和降低成本
文章要点:
1. GPTCache可以显著减少延迟从而使LLM应用程序变得超快
2. 通过减少对LLM的调用,可以节省计算资源从而降低成本
3. GPTCache具有可扩展性,适用于各种规模的应用
在这个快节奏的软件工程世界,哪怕几毫秒的差异也可能决定用户体验的成败,所以优化语言机器学习模型(LLM)的应用速度和成本是很有必要的事情。GPTCache的出现为这些挑战提供了突破性的解决方案。本文旨在指导您将GPTCache集成到LLM应用中,从而实现100倍更快的响应速度和大幅降低成本。

注:图片由midjourney生成
目标
读完本文后,您应该能够将 GPTCache 集成到您的 LLM 应用程序中,从而实现无与伦比的速度和成本效率。
我们先来了解为什么GPTCache是一个游戏规则改变者。GPTCache大大减少了延迟通过缓存响应,使您的LLM应用程序快得惊人。通过减少对LLM的调用,您可以节省计算资源,进而节省资金。GPTCache旨在实现扩展,使其适用于小型和大型应用程序。
# 导入 GPTCache 库
from gptcache import GPTCache
# 初始化 GPTCache
缓存 = GPTCache()
接下来看看如何设置GPTCache:
第一步是安装GPTCache包;
pip 安装 gptcache
第二步是在应用程序中初始化GPTCache。
from gptcache import GPTCache
# 使用默认设置初始化
cache = GPTCache()
使用GPTCache的最佳实践:
缓存粒度:尽可能在最细粒度的级别缓存,以最大限度地提高重用性。
# 缓存单个句子而不是整个段落
缓存。设置(“sentence_key”,“cached_sentence”)
缓存回收策略:实施与应用程序需求相匹配的缓存回收策略。
# 设置缓存驱逐策略为LRU(最近最少使用)
cache.set_eviction_policy( "LRU" )
监控和日志记录:始终监控缓存命中和未命中,以了解缓存的有效性。
# 监控缓存命中和未命中情况
cache_hits,cache_misses = cache.get_stats()
接下来看看如何将GPTCache与LLM集成:
第一步是封装现有的LLM调用;
def get_llm_response ( query ):
# 检查响应是否在缓存中
cached_response = cache.get(query)
if cached_response:
return cached_response
# 否则,从LLM获取响应
llm_response = llm.get_response(query)
# 缓存响应
缓存。设置(查询,llm_response)
返回llm_response
第二步是测试和验证,以确保满足性能和成本目标。
# 测试缓存机制
assert get_llm_response( "test_query" ) == get_llm_response( "test_query" )
最后,GPTCache集成的一些高级技巧:
异步缓存:在高并发环境下,异步缓存可以是救星。
import asyncio
async def async_get_llm_response ( query ):
# 检查响应是否在缓存中
cached_response = wait cache.async_get(query) if cached_response: return cached_response # 否则,从 LLM获取响应llm_response = wait llm.async_get_response(query) # 缓存响应等待cache.async_set(查询,llm_response)返回llm_response
缓存版本控制:当LLM模型更新时,可以使缓存失效。版本控制可以帮助实现这一点。
# 将版本控制添加到缓存键中
cache_key = f" {query} _v {llm_version} "
# 使用版本化键进行缓存
。设置(cache_key,llm_response)
批量缓存:有时,您可能希望一次缓存多个项目。GPTCache支持批量操作。
# 批量设置缓存中的项
cache.bulk_set({ "key1" : "value1" , "key2" : "value2" })
缓存过期:对于实时性数据,设置缓存项过期时间可能很有用。
# 设置缓存的有效期为60秒
。设置(“键”,“值”,ttl=60)
AI搜索Perplexity来了,谷歌搜索真正有了对手
要说在互联网世界中什么才是“王冠顶上的明珠”,或许就非搜索引擎莫属了,毕竟在太平洋两岸也分别造就了百度和谷歌这两大巨头的基业长青。如此美妙的生意自然从来都不缺乏挑战者,国内市场有360、搜狗,海外也有Bing、雅虎,以及DuckDuckGo。而随着AI大模型的爆发,AI赋能搜索引擎更是成为了业界的新潮流。站长网2024-01-21 10:35:390000Refuel AI 推出专为数据标注和清洗设计的开源语言模型 RefuelLLM-2
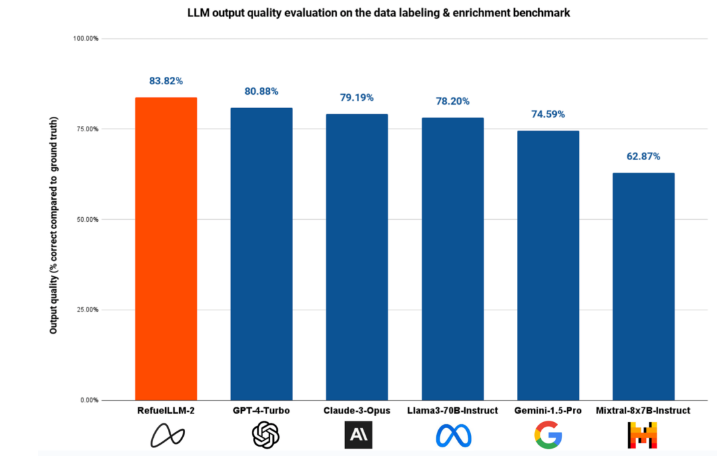
RefuelAI最近宣布推出两个新版本的大型语言模型(LLM),RefuelLLM-2和RefuelLLM-2-small,这两个模型专为数据标注、清洗和丰富任务而设计,旨在提高处理大规模数据集的效率。RefuelLLM-2的主要特点包括:自动化数据标注:能够自动识别和标记数据中的关键信息,如分类数据和解析特定属性。站长网2024-05-13 15:53:380000直击618开局:李佳琦稳定发挥,辛巴杠上榴莲,小红书明星主播奇袭
李佳琦在直播间敲响锣鼓,今年618大促正式拉开帷幕。“10万了,疯了”“好夸张,太夸张了”……5月26日预售当晚,面对刚上链接就被爆买的多个产品,连李佳琦本人都发出感慨。预售倒计时的李佳琦和助播团据新榜编辑部不完全统计,整场直播累计上架338个单品链接,至少30个单品的销量超过10万件,19个单品直接库存售罄,按照商品页面显示的成交价格来算累计销售额预估超44亿元。站长网2023-05-27 14:48:33000195%的印度IT领导者预计生成式AI将很快发挥重要作用
文章概要:1.印度IT领导者有95%的人相信生成AI很快会在他们的组织中发挥重要作用而增长。但是,领导者仍持谨慎态度,82%的人担心生成式AI的伦理问题。2.74%的印度IT组织难以满足业务的需求,而91%的人预计未来18个月内需求还会增长。为此,95%的印度IT领导者表示,他们越来越专注于提高运营效率。3.只有40%的印度IT组织能满足它们收到的所有应用开发请求。站长网2023-08-26 16:14:300000Silobreaker推AI威胁情报助手:协助组织迅速应对风险
划重点:🔍SilobreakerAI将加速威胁情报团队的情报报告生成,帮助组织更快地评估和减少风险。🔍该工具集成到Silobreaker情报平台,基于分析师内容创建的人工智能,提供准确可靠的见解。🔍SilobreakerAI增强了威胁情报功能,简化开源情报数据的处理,还包括自定义仪表板和数据提取功能。站长网2023-11-06 16:50:480000