Refuel AI 推出专为数据标注和清洗设计的开源语言模型 RefuelLLM-2
Refuel AI 最近宣布推出两个新版本的大型语言模型(LLM),RefuelLLM-2和 RefuelLLM-2-small,这两个模型专为数据标注、清洗和丰富任务而设计,旨在提高处理大规模数据集的效率。
RefuelLLM-2的主要特点包括:
自动化数据标注:能够自动识别和标记数据中的关键信息,如分类数据和解析特定属性。
数据清洗:自动检测并修正数据中的错误或不一致性,例如拼写错误和格式问题。
数据丰富:根据现有数据自动补充缺失信息或提供额外上下文,增加数据的价值和可用性。
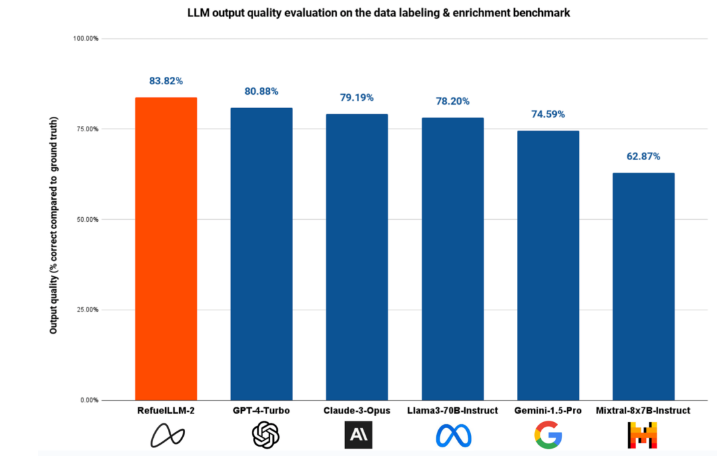
高准确率:在约30项数据标注任务的基准测试中,RefuelLLM-2以83.82%的准确率优于所有其他最先进的大型语言模型,包括 GPT-4-Turbo 和 Claude-3-Opus。
两款模型的比较:
RefuelLLM-2:基于 Mixtral-8x7B 模型,支持高达32K的最大输入上下文长度,适合处理长文本输入。
RefuelLLM-2-small:基于 Llama3-8B 模型,提供一个成本更低、运行更快的选项,同时保持高性能,支持高达8K的输入上下文长度。
训练细节:
两款模型都在超过2750个数据集上进行训练,涵盖分类、阅读理解、结构化属性提取和实体解析等任务。
训练方法:包括两个阶段,第一阶段专注于指令调整训练,第二阶段则加入更长上下文的输入,以提高模型在复杂数据处理任务中的表现。
性能提升:
两阶段训练方法使得 RefuelLLM-2在基本数据处理任务中表现出色,并能有效处理长上下文输入。
质量评估:
在长上下文数据集和非公开数据集的评估中,RefuelLLM-2和 RefuelLLM-2-small 均展现出良好的性能和泛化能力。
在置信度分数质量方面,RefuelLLM-2和 RefuelLLM-2-small 显示出比其他模型更好的置信度分数校准。
Refuel AI 的这一创新为数据标注和清洗领域带来了新的解决方案,有助于自动化和优化大规模数据处理流程。
playground:https://labs.refuel.ai/playground
模型下载:https://huggingface.co/refuelai/Llama-3-Refueled
年入千万的AI恋爱键盘,可能会让你的crush拉黑你
木讷直男如何三句话哄笑女神?社恐宅女如何一键生成千层套路?近几个月,一群号称“赛博恋爱军师”、“你的恋爱嘴替”的AI恋爱键盘应用,上线不久就创造了百万月活,狂揽千万营收,成为国内消费级AI应用领域当之无愧的“黑马”。据点点数据:Lovekey键盘(2024年2月上线):年收入3100万元人民币,月活用户244万。蜜小语(2024年6月上线):年收入2150万元人民币,月活235万。0000极氪汽车6月交付10620辆 同比增长146.9%
吉利控股旗下高端智能电动品牌极氪宣布,6月公司交付10620辆,同比增长146.9%,环比增长22.4%。截至目前,极氪品牌累计交付12万台。据悉,极氪品牌旗下有极氪001、极氪009、极氪X三款车型。站长网2023-07-02 10:12:390000和AI谈恋爱,掏空我钱包
今天是“520”,你会跟谁过节?你知道吗,已经有千万级别的用户拥有AI恋人了。提起AI恋人,不少人的第一印象是在2013年上映的电影《她》中,主人公西奥多爱上了人工智能系统创造出的虚拟助理莎曼莎,她的嗓音沙哑性感、性格善解人意。10年过去,剧情复刻进现实,越来越多年轻人和AI谈起了恋爱,在社交平台分享“人机之恋”的点滴日常。站长网2023-05-21 10:16:360000帅哥员工齐跳科目三,社会摇成了海底捞的新流量密码
“不是男模点不起,而是海底捞更有性价比。”最近,全国各地不少网友涌进海底捞的线下门店,就为了看海底捞的小哥哥跳一下科目三。手臂一甩、双腿一扭,再配上令人眼花缭乱的花手,一套丝滑小连招下来,镜头外尽是网友心满意足的欢笑声,如果恰好碰上帅气的小哥哥,网友们的笑声还得再高几度。站长网2023-11-24 15:29:200000