Meta 更新帮助资源中心:加入「生成式 AI 数据主体权利」表单
站长之家(ChinaZ.com) 8月31日消息:Facebook 用户现在可以删除一些个人信息,这些信息可能会被公司用于训练生成式人工智能模型。

Meta 本周在其网站上更新了 Facebook 帮助中心资源部分,添加了一个名为「生成式 AI 数据主体权利」的表单,允许用户「提交与第三方信息有关的请求,这些信息被用于生成式 AI 模型的训练」。
随着生成式 AI 技术在科技领域取得突破,各家公司正在创建更复杂的聊天机器人,将简单的文本转化为复杂的回答和图像。Meta 为人们提供了访问、修改或删除其个人数据的选项,这些数据包含在公司用于训练其大型语言和相关 AI 模型的各种第三方数据来源中。
在表单上,Meta 将第三方信息称为「在互联网上公开可用或经过许可的来源获取的数据」。公司表示,这种信息可以代表「数十亿条数据」之一,用于训练生成式 AI 模型,这些模型使用预测和模式来创建新内容。
在一篇关于其如何使用数据进行生成式 AI 的相关博文中,Meta 表示除了从其他提供者获取许可数据外,还会收集来自网络的公开信息。例如,博客文章可能包含个人信息,如某人的姓名和联系方式,Meta 说道。
该表单并未考虑用户在 Meta 拥有的平台上的活动,无论是 Facebook 评论还是 Instagram 照片,因此公司有可能使用此类自家数据来训练其生成式 AI 模型。
一位 Meta 发言人表示,公司最新的 Llama 2 开源大语言模型「未经过 Meta 用户数据的训练,我们尚未在系统上推出任何生成式 AI 消费者功能。」
「根据人们所在的地区,他们可能能够行使数据主体权利,反对将某些数据用于训练我们的 AI 模型,」发言人补充道,这涉及到美国以外的各种数据隐私规定,这些规定赋予消费者更多控制权,限制科技公司如何使用他们的个人数据。
与包括微软、OpenAI 和 Google 母公司 Alphabet 在内的许多科技同行一样,Meta 收集大量第三方数据来训练其模型和相关的 AI 软件。
「为了训练有效的模型以实现这些进展,需要从公开可用和经过许可的来源获取大量信息,」Meta 在博文中表示。公司补充道,「使用公开信息和许可数据符合我们的利益,我们承诺在使用这些信息的法律依据方面保持透明。」
然而,最近一些数据隐私倡导者对于聚合大量公开可用信息用于训练 AI 模型的做法提出了质疑。
上周,英国、加拿大、瑞士等国的数据保护机构联合致信 Meta、Alphabet、TikTok 母公司字节跳动、X(以前称为 Twitter)、微软等公司,涉及数据爬取和保护用户隐私的问题。
这封信旨在提醒社交媒体和科技公司,他们仍需遵守全球各地的各项数据保护和隐私法律,「以保护其网站上可访问的个人信息,免受数据爬取的影响,尤其是要确保他们遵守全球各地的数据保护和隐私法律。」
该团体在声明中表示:「个人也可以采取措施保护其个人信息免受数据爬取的影响,社交媒体公司在帮助用户以保护隐私的方式使用其服务方面也有一定的责任。」
以下是如何删除用于训练生成式 AI 模型的部分 Facebook 数据的步骤:
访问 Meta 关于生成式 AI 的隐私政策页面上的「生成式 AI 数据主体权利」表单。
点击「在此了解更多并提交请求」链接。
从 Meta 提供的三个选项中选择「最能描述您的问题或异议的选项」。
第一个选项允许人们访问、下载或更正从第三方来源获取的用于训练生成式 AI 模型的个人信息。选择第二个选项,他们可以删除从这些第三方数据来源获取的用于训练的任何个人信息。第三个选项适用于「有其他问题的人」。
在选择了三个选项之一后,用户需要通过安全验证测试。但有一些用户评论说,由于软件错误,他们无法完成表单的填写。
硬气如Temu,还在强啃日本这块硬骨头?
一位投资人在播客中透露,拼多多的人效比能达到千万元。这家公司的做事效率真的太强了,这很难不让人爱屋及乌,重新评估Temu的可能性。而Temu自己也十分大胆,不止上线第二年就给自己定下150亿美金GMV目标,更是立下第三年(2024)翻倍到300亿美金GMV的flag。站长网2023-12-01 09:19:380000国产模型人均「第一」太假?字节扣子模型广场竞技,全民投票!
【新智元导读】每家国产大模型都说自己是第一,该信谁的?最近,字节推出了扣子模型广场,全体国产LLM开启大混战!你一票,我一票,谁是第一,大众说了算。投票连小朋友都能参与,模型生态从此彻底从黑盒到白盒。只有打开黑盒,大模型应用生态才能从玄学变科学。从厉害到能用,关键一步是确定性在过去的半年里,笔者在北京拜访了一百多位人工智能应用开发者,其中最年长的是80多岁的张老。站长网2024-06-14 16:36:2100003299元起冲击高端!Redmi K70 Pro发布:2K国产屏 国产定制相机
快科技11月29日消息,今晚Redmi带来了首次冲击高端的旗舰机型RedmiK70Pro。该机代表着Redmi有史以来最强堆料水平,包括性能、外观、屏幕、影像等各方面,将开启Redmi下一个十年之路。首先看外观方面,这次RedmiK70Pro采用了小米14上备受好评的直边直屏方案,且取消屏幕支,边框仅有1.6mm,机身宽度仅有74.9mm,中框为金属材质。站长网2023-11-29 22:07:240000纽约市长用AI生成多语言进行电话推广引争议
划重点:-纽约市长亚当斯通过人工智能工具向市民发送多语言电话推广活动,其中包括西班牙语、意第绪语、普通话、广东话和海地克里奥尔语。-亚当斯因在电话中用自己的声音宣传活动,而实际上不懂这些语言,引发伦理争议。-批评者称这是伦理不当,但亚当斯辩称这是为了能够与讲其他语言的市民交流。站长网2023-10-18 21:24:270000小米首款钛合金旗舰!小米14 Pro钛金属特别版降价:6099元
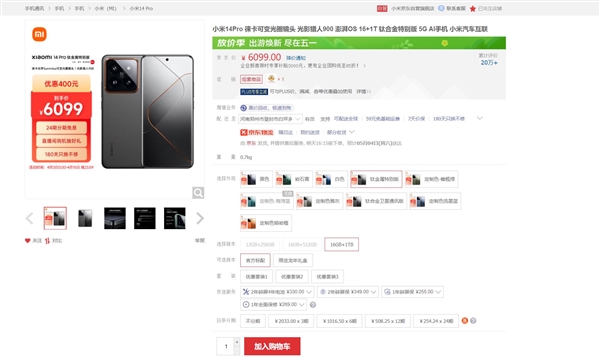
快科技5月3日消息,小米京东自营店显示,小米14Pro钛金属特别版五一降价促销,到手价为6099元(16GB1TB)。这是小米旗下首款采用钛合金的旗舰手机,钛金属具有其他材料无法比拟的优点。由于其独特的物理和化学性质,钛金属被广泛应用于航天、医疗、高端运动装备等领域,具有轻质、高强度、抗腐蚀等特点。站长网2024-05-03 22:33:580000