学术党狂喜,Meta推出OCR神器,PDF、数学公式都能转
我们平时在阅读论文或者科学文献时,见到的文件格式基本上是 PDF(Portable Document Format)。据了解,PDF 成为互联网上第二重要的数据格式,占总访问量的2.4%。
然而,存储在 PDF 等文件中的信息很难转成其他格式,尤其对数学公式更是显得无能为力,因为转换过程中很大程度上会丢失信息。就像下图所展示的,带有数学公式的 PDF,转换起来就比较麻烦。

现在,Meta AI 推出了一个 OCR 神器,可以很好的解决这个难题,该神器被命名为 Nougat。Nougat 基于 Transformer 模型构建而成,可以轻松的将 PDF 文档转换为 MultiMarkdown,扫描版的 PDF 也能转换,让人头疼的数学公式也不在话下。

论文地址:https://arxiv.org/pdf/2308.13418v1.pdf
项目主页:https://facebookresearch.github.io/nougat/
Nougat 不但可以识别文本中出现的简单公式,还能较为准确地转换复杂的数学公式。

公式中出现的上标、下标等各种数学格式也分的清清楚楚:

Nougat 还能识别表格:
扫描产生畸变的文本也能处理:

不过,Nougat 生成的文档中不包含图片,如下面的柱状图:
看到这,网友纷纷表示:(转换)效果真是绝了。

方法概述
本文架构是一个编码器 - 解码器 Transformer 架构,允许端到端的训练,并以 Donut 架构为基础。该模型不需要任何 OCR 相关输入或模块,文本由网络隐式识别。该方法的概述见下图1。
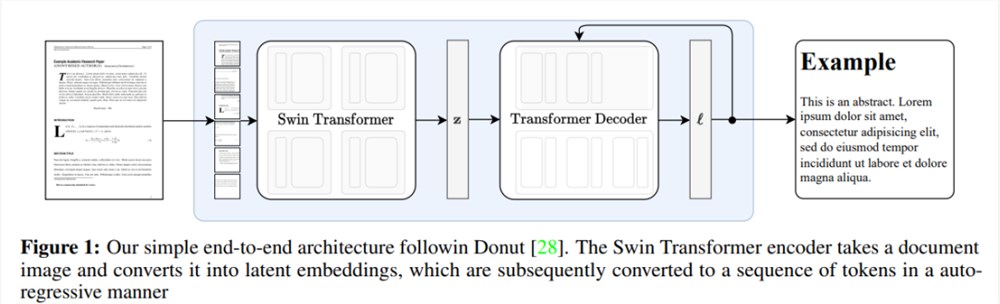
该研究用到了2个 Swin Transformer ,一个参数量为350M,可处理的序列长度为4096,另一参数量为250M,序列长度为3584。在推理过程中,使用贪婪解码生成文本。
在图像识别任务中,使用数据增强技术来提高泛化能力往往是有益的。由于本文只研究数字化的学术研究论文,因此需要使用一些变换来模拟扫描文件的不完美和多变性。这些变换包括侵蚀、扩张、高斯噪声、高斯模糊、位图转换、图像压缩、网格变形和弹性变换 。每种变换都有固定的概率应用于给定的图像。这些变换在 Albumentations 库中实现。在训练过程中,研究团队也会通过随机替换 token 的方式,对实际文本添加扰动。

每种变换的效果概览
数据集构建与处理
据研究团队所知,目前还没有 PDF 页面和相应源代码的配对数据集,因此他们从 arXiv 上开放获取的文章中创建了自己的数据集。为了数据多样性,数据集中还包括 PubMed Central (PMC) 开放访问非商业数据集的一个子集。预训练期间,还加入了部分行业文档库 (IDL)。
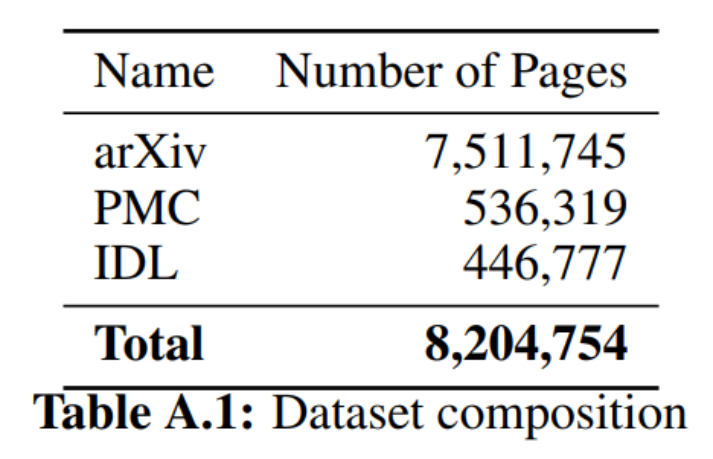
表1数据集构成
在处理数据集的过程中,研究团队也将不同来源的数据进行了合适的处理,下图展示了他们对 arXiv 文章进行源代码收集并编译 PDF 的过程。详细内容请阅读全文。

源文件被转换成 HTML,然后再转换成 Markdown。
研究团队根据 PDF 文件中的分页符分割 markdown 文件,并将每个页面栅格化为图像以创建最终配对的数据集。在编译过程中,LaTeX 编译器自动确定 PDF 文件的分页符。由于他们不会为每篇论文重新编译 LaTeX 源文件,因此必须将源文件分割成若干部分,分别对应不同的页面。为此,他们使用 PDF 页面上的嵌入文本,并将其与源文本进行匹配。
但是,PDF 中的图形和表可能并不对应于它们在源代码中的位置。为了解决这个问题,研究团队使用 pdffigures2在预处理步骤中删除这些元素。将识别出的字幕与 XML 文件中的字幕进行比较,根据它们的 Levenshtein 距离进行匹配。一旦源文档被拆分为单独的页面,删除的图形和表就会重新插入到每一页的末尾。为了更好地匹配,他们还使用 pylatexence -library 将 PDF 文本中的 unicode 字符替换为相应的 LaTeX 命令。
词袋匹配:首先,研究团队使用 MuPDF 从 PDF 中提取文本行,并对其进行预处理,删除页码和页眉 / 页脚。然后使用词袋模型与 TF-IDF 向量化器和线性支持向量机分类器。将模型拟合到以页码为标签的 PDF 行。然后,他们将 LaTeX 源代码分成段落,并预测每个段落的页码。理想情况下,预测将形成阶梯函数,但在实践中,信号将有噪音。为了找到最佳边界点,他们采用类似于决策树的逻辑,并最小化基于 Gini 不纯度的度量:
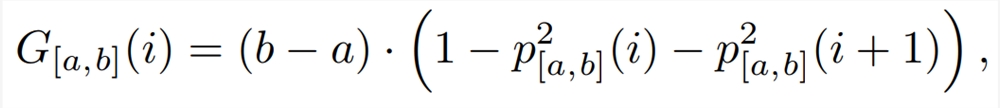
其中

是在区间 [a,b] 中选择具有预测页码 i 的元素的概率,该区间描述了哪些段落 (元素) 被考虑用于分割。
区间 [a, b] 的最佳拆分位置 t 为:
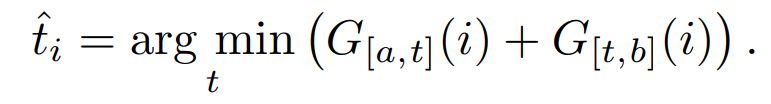
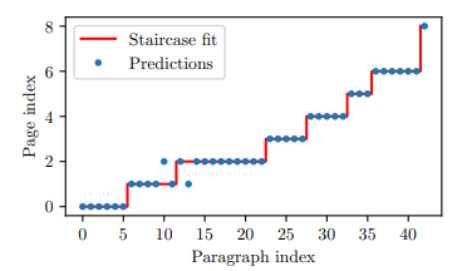
搜索过程从所有段落开始,对于后续的每个分页,搜索区间的下界设置为前一个分页位置。
模糊匹配:在第一次粗略的文档分割之后,研究团队尝试找到段落中的准确位置。通过使用 fuzzysearch 库,将预测分割位置附近的源文本与嵌入的 PDF 文本的前一页的最后一个句子和下一页的第一个句子进行比较,就可以达到这个目的。如果两个分隔点在源文本中的相同位置,则认为换页是准确的,得分为1。另一方面,如果分割位置不同,则选择具有最小归一化 Levenshtein 距离的分割位置,并给出1减距离的分数。要包含在数据集中,PDF 页面的两个分页符的平均得分必须至少为0.9。如此一来,所有页面的接受率约为47%。
实验
实验中用到的文本包含三种类别:纯文本、数学表达式以及表格。
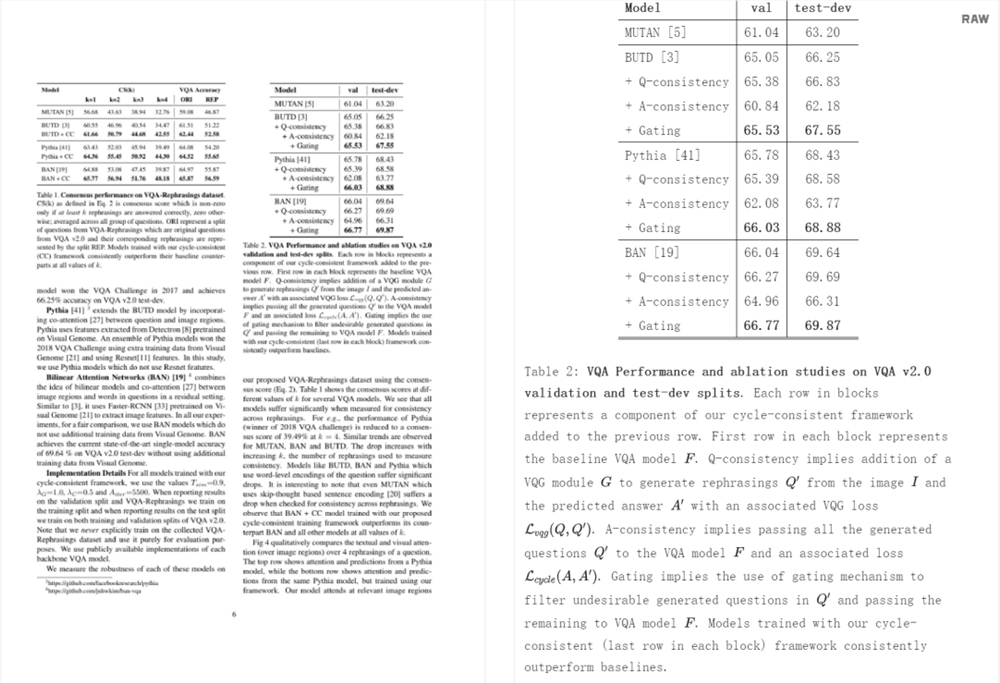
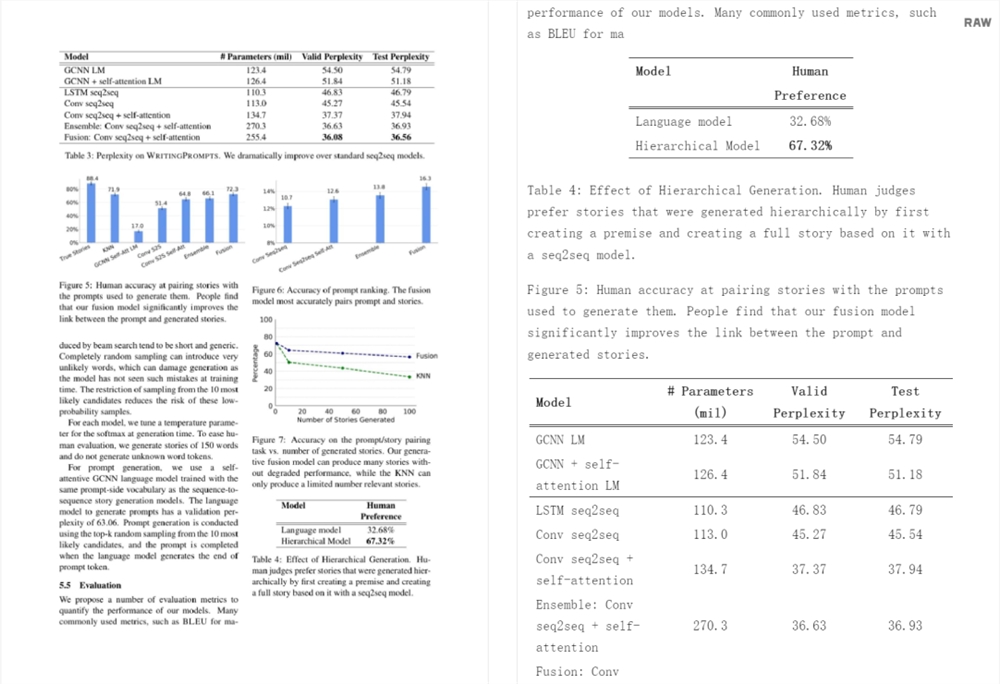
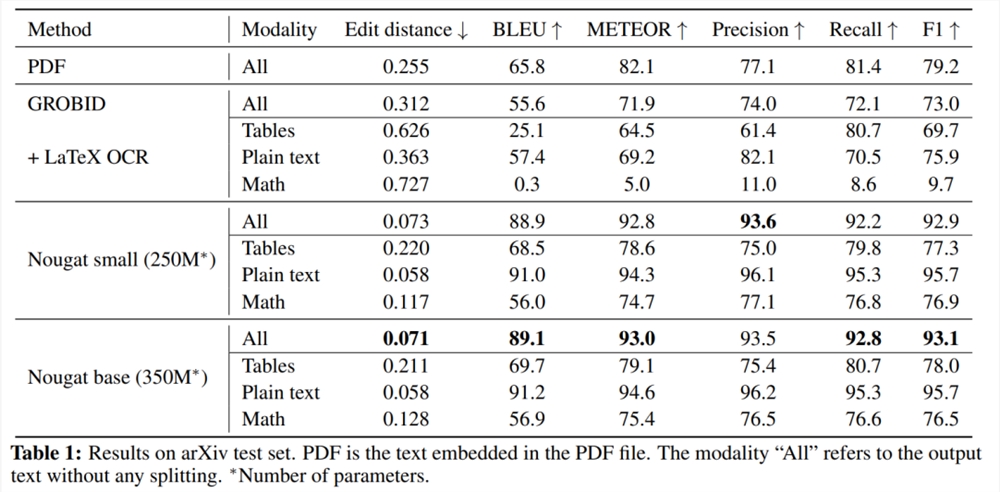
结果如表1所示。Nougat 优于其他方法,在所有指标中取得最高分,并且具有250M 参数模型的性能与350M 参数模型相当。
下图为 Nougat 优对一篇论文的转换结果:

Meta 表示,Nougat 在配备 NVIDIA A10G 显卡和24GB VRAM 机器上可并行处理6个页面,生成速度在很大程度上取决于给定页面上的文本量。在不进行任何推理优化的情况下,基础模型每批次平均生成时间为19.5s(token 数≈1400),与经典方法(GROBID10.6PDF/s )相比速度还是非常慢的,但 Nougat 可以正确解析数学表达式。
iPhone14和 iPhone15用户现在可使用 Verizon 的路边援助服务
苹果今天宣布,iPhone14和iPhone15用户现在可以使用Verizon的路边援助服务。该服务由Allstate旗下的SignatureMotorClub运营,可在没有移动连接的地区提供帮助。要使用该服务,您需要运行iOS17.2或更高版本,并使用VerizonSIM卡。您可以通过iPhone上的“设置”应用访问该服务。0000Midjourney Alpha新功能!已生成图片参数支持点击回填到提示词输入框
MidjourneyAlpha迎来全新功能!如果你已经成功生成1万张图片,你将直接获得权限。全新的生成用户界面比之前的测试版本更加便捷,所有参数都以可视化图像的形式呈现,包括图片比例等。截图自归藏X账号此外,你还能够直接使用资源库中的图片作为垫图,使整个生成过程更加流畅。如果想了解自己生成了多少张图片,只需输入/info命令,一切尽在掌握。站长网2023-12-13 11:50:500001我们尝试用AI创作了一条圣诞动画(附ChatGPT+Pika等制作流程全记录)
最近,AI视频生成领域可以说是迎来了一波小爆发,前有明星产品RunwayGen2,后有黑马Pika1.0爆火,随着越来越多的玩家和产品涌入AI视频赛道,视频创作的门槛似乎越来越低了。例如,今年圣诞节就有不少网友用Pika1.0整活,生成了各种脑洞大开的AI圣诞老人。话不多说,下面请看圣诞老人的多重人生🔽正在开圣诞摇滚专场的🎅🏻:站长网2023-12-25 18:52:230002特斯拉同意支付600万美元 结束一场有关太阳能电池的集体诉讼
据CNBC报道,特斯拉同意支付刚刚超过600万美元,以解决客户提起的集体诉讼,这些客户在同意在自己家中安装太阳能屋顶系统后,面临了2021年的突然价格上涨。特斯拉太阳能屋顶以前被称为特斯拉“太阳能玻璃”。首席执行官埃隆·马斯克于2016年首次推广该系统,作为一种屋顶太阳能产品,可以产生电量,为业主节省用电开支。站长网2023-07-12 16:23:460000百度吉利发布“极越”汽车机器人品牌 将搭载文心一言等 AI 能力
昨日,百度、吉利战略合作升级,旗下汽车机器人品牌“极越”发布。据介绍,极越是吉利控股集团旗下高端智能汽车机器人品牌,致力于打造智能化领先的汽车机器人,以高阶智驾、智舱产品和创新数字化服务,为用户创造标杆级智能科技出行体验“极越”品牌的正式发布,标志着“汽车机器人战略合作项目”向高端智能汽车量产迈出实质性一步。“极越”品牌旗下首款车型正式命名为“极越01”站长网2023-08-15 08:33:070001