视觉语言模型BLIVA:让AI更擅长阅读图像中的文本 懂得看路牌和食品包装
文章概要:
1. BLIVA是一种视觉语言模型,擅长读取图像中的文本。
2. BLIVA结合了InstructBLIP的学习查询嵌入和LLaVA的编码修补嵌入。
3. BLIVA在多个数据集上表现优异,可用于识别路牌、食品包装等场景。
BLIVA 是一种视觉语言模型,擅长读取图像中的文本,使其在许多行业的现实场景和应用中发挥作用。
加州大学圣地亚哥分校的研究人员开发了 BLIVA,这是一种视觉语言模型,旨在更好地处理包含文本的图像。视觉语言模型 (VLM) 通过合并视觉理解功能来扩展大型语言模型 (LLM),以回答有关图像的问题。
这种多模态模型在开放式视觉问答基准方面取得了令人印象深刻的进展。一个例子是 OpenAI 的GPT-4,它的多模式形式可以在用户提示时讨论图像内容,尽管此功能目前仅在“Be my Eyes”应用程序中可用。
然而,当前系统的一个主要限制是处理带有文本的图像的能力,这在现实场景中很常见。
BLIVA 结合了 InstructBLIP 和 LLaVA
视觉语言模型通过合并视觉理解功能来扩展大型语言模型,以回答有关图像的问题。
BLIVA结合了两种互补的视觉嵌入类型。一种是Salesforce InstructBLIP提取的学习查询嵌入,用于关注与文本输入相关的图像区域;另一种是受Microsoft LLaVA启发提取的编码修补嵌入,直接从完整图像的原始像素修补中获得。
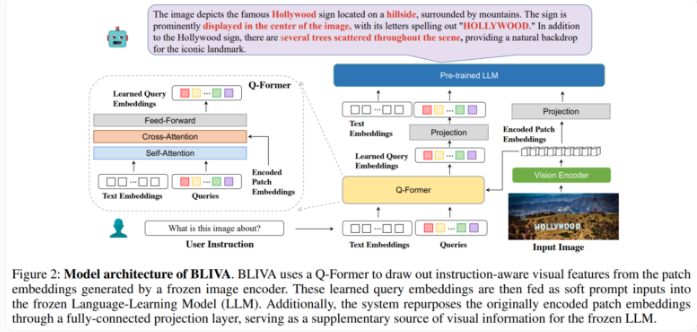
研究人员表示,这种双重方法允许BLIVA同时利用针对文本定制的精炼查询嵌入,以及捕捉更多视觉细节的更丰富的编码修补。
BLIVA 使用大约550,000个图像标题对进行了预训练,并使用150,000个视觉问答示例调整了指令,同时保持视觉编码器和语言模型冻结。
在多个数据集上,BLIVA的表现明显优于InstructBLIP等其他模型。例如,在OCR-VQA数据集上,BLIVA的准确率达到65.38%,而InstructBLIP只有47.62%。

研究人员认为这证明了多嵌入方法对广泛的视觉理解的益处。BLIVA还在YouTube视频缩略图数据集上取得了92%的准确率。BLIVA识读图像文本的能力可应用于许多行业,如识别路牌、食品包装等。BLIVA有望改善现实世界中的多种应用。
项目网址:https://huggingface.co/datasets/mlpc-lab/YTTB-VQA
限时免费!Adobe Firefly AI即将登陆Vision Pro,用户可在现实空间中创造个性化图像
近日,Adobe宣布在其VisionPro平台中将推出全新的AI应用——FireflyAI,为用户提供更加创新的视觉体验。据报道,这一新应用专门为头显的visionOS系统打造,允许用户在VisionPro中生成的图像在现实空间中移动并放置到墙壁、桌子等物品上,创造出多样的环境效果。站长网2024-02-04 16:57:460000比特币ATM诈骗激增10倍!2024年上半年损失达6500万美元
最近,美国联邦贸易委员会(FTC)发布了一份报告,揭示了比特币ATM诈骗案件的惊人增长。从2020年到2023年,这种骗局造成的损失竟然从1200万美元激增到1.14亿美元,而仅在2024年的上半年,受害者的损失就已经达到了6500万美元。你没听错,这个数字是前几年的10倍还多,令人咋舌。站长网2024-09-05 16:50:410000英特尔通过替代产品规避英伟达在大语言模型领域的主导地位
近年来,随着人工智能的广泛应用,底层计算芯片的需求不断增加。与传统CPU相比,GPU更适合此类任务,因为它们提供了更好的性能,并在AI计算市场上抢得先机。站长网2023-07-14 00:35:500001国服回归有戏!曝网易、暴雪分手一年后“复合”
快科技12月25日消息,据36氪”报道,过去一段时间,暴雪与国内多家游戏厂商洽谈了国服回归”事宜,最终选择与网易重新牵手合作。据悉,11月底,有报道称暴雪已在和包括网易、腾讯在内的多家游戏厂商谈判国服回归事宜,但目前尚未有确定的合作方和具体回归时间2023年1月24日零点,我们见证了可能是游戏史上最大规模的停服事件暴雪中国战网”服务器正式关闭,长达25年的暴雪中国业务戛然而止。0000盘点年度AI假新闻:山寨的AI顶流们,骗了爸妈一整年
“你可以在网上看到很多话,一句是我说的,还有千万句都是我说的。”——鲁迅或许还有一些,是AI说的。过去,很多假新闻可能是通过传统剪辑工具进行后期修改的,而现在,生成式AI正在成为虚假信息传播的主力军。大量虚假照片、视频、GIF图充斥着互联网。0000











