4G显存低配畅玩AIGC!ControlNet作者新作登顶GitHub热榜,小白点3次就出图
玩AI画画,现在终于不用担心被老黄刀法“背刺”了!
只需要一块4年前的GTX1650(显存4GB),AI出图效果堪比当前最好的开源模型SDXL。这是最近在GitHub上连续数日霸榜TOP1的新项目Fooocus,三天标星破4k,ControlNet作者出品。
在它横空出世之前,大伙儿要想顺利跑Stable Diffusion最新的XL模型,怎么也得上16G显存的4060ti(12G显存的原生3060跑起来非常勉强)。
与其他开源AI工具不同,Fooocus“聚焦于生成本身”,不仅硬件要求低,而且上手简单,十分小白友好——
全过程无需调整任何参数,点点鼠标,3步就能生成一张图像。
△图源推特@Photogenic Weekend
有网友直呼“这简直就是Stable Diffusion和Midjourney的集大成”:
跟手动调参说再见吧!离线、开源且免费,只需提示词和图片,就能让魔法涌现!

还有网友感叹:即使是小白,也能很好地发挥出Stable Diffusion XL模型的效果呢。

那么,这个全新的图像AI工具,实际生成效果如何?我们上手试了试。
Colab半分钟出图,效果比肩SD
从运行界面来看,Fooocus一共有一百多种内置风格可供选择。

△图源推特@camenduru
至于效率,Fooocus出图也是非常快。在Colab中,速度优先模式下每画一张图大概只需半分钟:

日志显示的时间是绘制时间,不过之前还有个文本解析的过程,总共耗时大约是40秒:

△画面经过加速处理
那就先让它画个漫画试试,来看看AI视角下的“马扎大战”会是什么样子。(可不是这个马扎哈)
由于用AI直接生成人像,手部的处理还是存在一些问题,所以我们干脆让马斯克和扎克伯格都戴上了手套:
效果好像还不错。不知道他们有没有什么赌注,不过不妨让输的人来女装一下。
最终两人“握手言和”,这一珍贵画面也被摄影师记录了下来,整体画面是不是有那味了?
“马扎之战”结束之后,老马乖乖地回到公司,卖起了特斯拉。
忽略LOGO的话,海报的设计感也还蛮在线的。
其实Fooocus的每个内置风格都很有趣,所以不妨再来看看这些不同风格的整活图片:
在模仿著名作品方面,有赛博朋克版、塞尔达版、Minecraft版,甚至是宝可梦版本的马斯克可供观赏。
至于其他的艺术形式,还有像素和Lowpoly风格,以及黏土人和剪纸版本……
当然例子是举不完的,更多的风格读者朋友们可以自己去体验。
各位大画家是不是已经按耐不住想要试试了?我们马上就来介绍Fooocus的玩法!
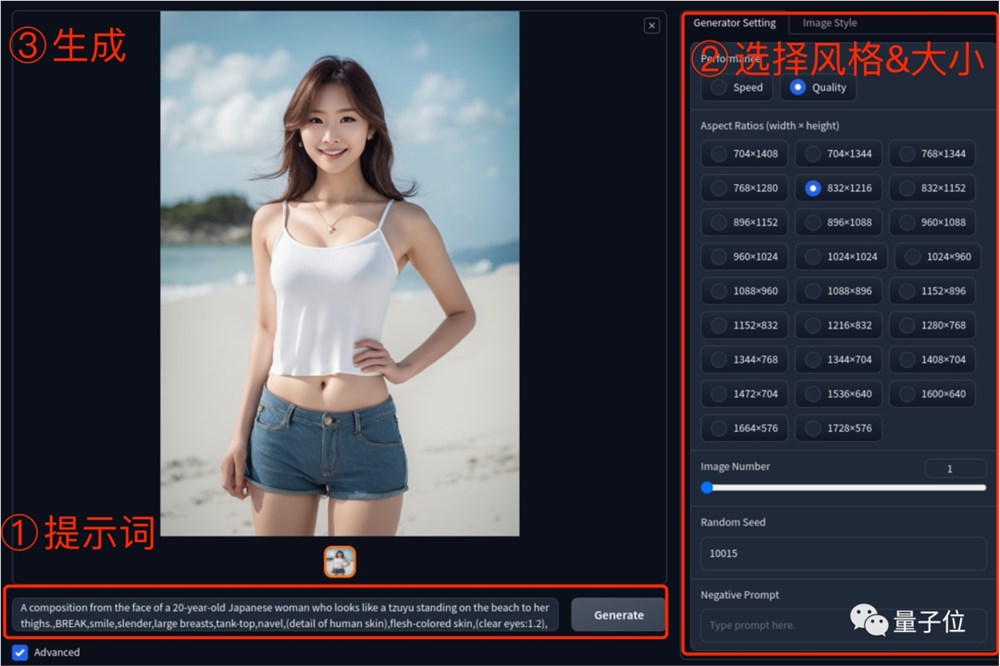
Fooocus的界面是酱婶儿的,可以说是十分有九分简洁:
如果只是尝个鲜,没有特殊要求的话,这一个提示框完全足够了。
因为作者已经把很多复杂技巧内化到了程序当中,调参这些操作不再需要手动完成。

直接在下面的框中输入Prompt,点击生成按钮就可以坐等出图了。
(默认一次出两张图,尺寸为1152×896,风格为cinematic default,速度优先)
如果需要高级设置,就把左下角的Advanced勾上,配置信息会出现在页面右侧,分为三个标签:

可以调整的内容包括尺寸、数量、风格、性能等等。
如果你是专业级玩家,还可以选择模型版本,甚至调整LoRA参数。
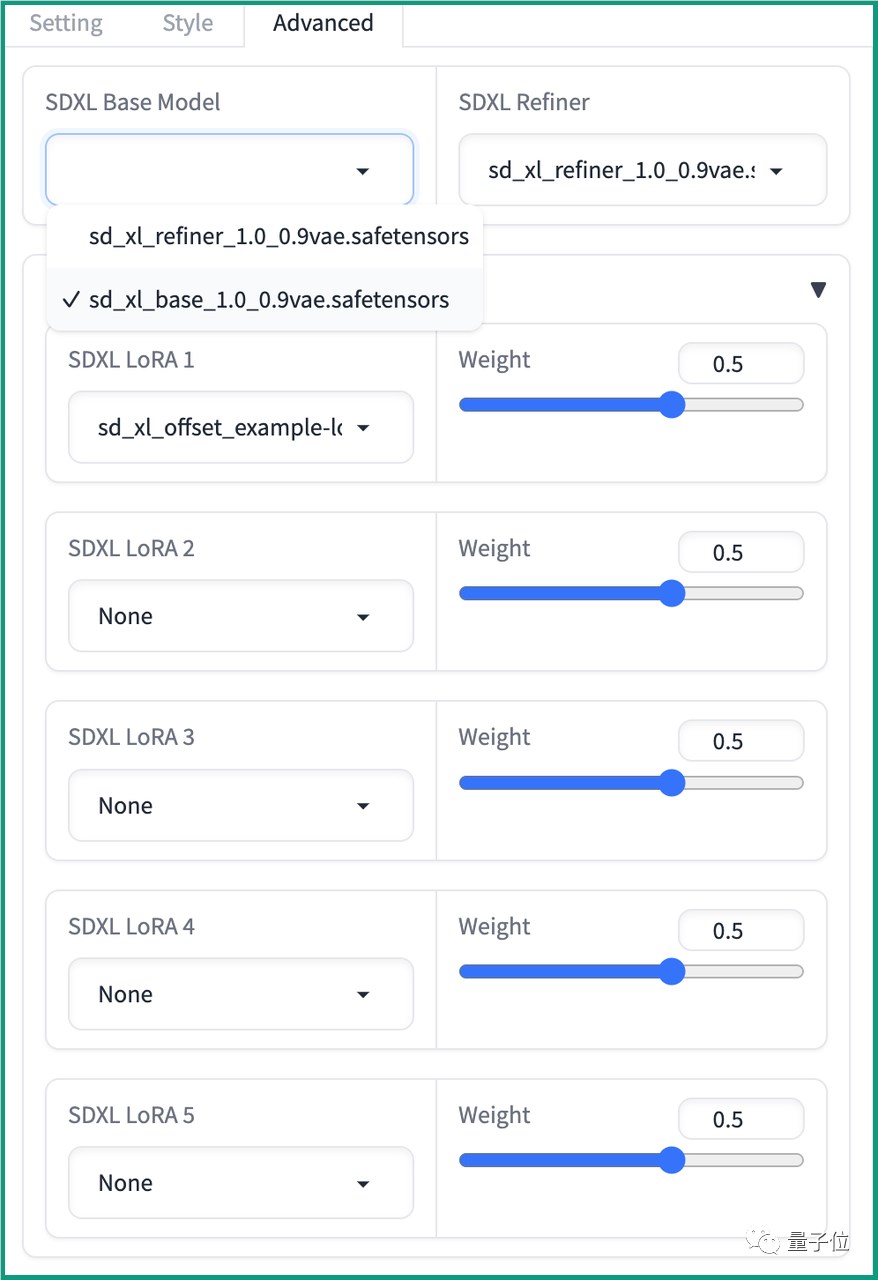
此外,还有调整锐利度这种高端玩法。
对于相同的内容,下面这张动图展示了锐利度从2到10再到20的变化。可以看出,随着锐利度增大,画面的细节也越来越丰富:
不过,对于Fooocus是否支持中文,我们也试了一下,很遗憾现在还不行。
比如我们输入提示词“苹果”,结果画出来的是个妹子。
这……难道是想说“You’re the apple of my eyes”?
现在你大概已经知道Fooocus的玩法了,那么又该怎么配置呢?
如果你有带英伟达显卡的Windows设备,那么可以用开箱即用的版本。(大概这已经是老黄第114514次赢麻了)
同时,硬件需要满足最低配置要求——4GB显存 8GB内存。
先从这里直接下载:
https://github.com/lllyasviel/Fooocus/releases/download/release/Fooocus_win64_1-1-10.7z
解压好之后,双击run.bat运行,系统会自动下载模型并部署,等配置完成就可以用了。

Linux版本的配置要求和Windows一样,不过配置流程要复杂些。
(如果有Jupyter,也可以参考Colab中用到的note文件)
首先要安装好环境依赖:
gitclonehttps://github.com/lllyasviel/Fooocus.gitcdFooocuscondaenvcreate-fenvironment.yamlcondaactivatefooocuspipinstall-rrequirements_versions.txt
然后下载模型文件,存储到指定目录:

△具体请参见GitHub页面
当然,也可以让系统自动下载模型:
pythonlaunch.py
如果你在用Mac,或者硬件配置不满足要求,也可以用Colab直接运行。
(传送门:https://colab.research.google.com/github/lllyasviel/Fooocus/blob/main/colab.ipynb)
不过,还是要吐槽的是,Colab版本会时不时宕几次机,不是自动停止就是内存溢出……

如果想在Mac或A卡电脑上更丝滑地运行Fooocus,可以再等等作者的更新。
整体来看,Fooocus的出图效果不错,如果提示词选择好的话,甚至可以当Stable Diffusion来用,关键是硬件配置要求也不高。
这究竟是怎么实现的?
来自ControlNet作者最新项目
架构设计上,Fooocus主要分为两部分:交互界面和AI模型。
其中,交互界面参考了两个项目,分别是stable-diffusion-webui和ComfyUI。
stable-diffusion-webui主要是交互界面的前端设计:

ComfyUI则兼具Stable Diffusion的GUI和后端设计:

至于AI模型,能看出是用了Stable Diffusion新的SDXL模型:

这是也目前Stable Diffusion最好用的版本之一,生成效果相比之前的1.5版本有不少改进。
不过,虽然Fooocus的模型和UI设计都有参考现成Stable Diffusion开源项目,但作者在制作时,融入了不少自己的优化设计,使得模型跑起来更加丝滑。
例如,作者仔细在Fooocus中采用了自己设计的k扩散采样(advanced k-diffusion sampling)方法,能提升采样连续性,减少性能损失、提升采样效率;
此外,作者还仔细调整了采样器(Sampler)的参数,并在原版基础上修改增加了一些包括电影风格在内的新设定。
之所以给Fooocus加上LoRA选项,是因为作者测试发现,加上LoRA(权重设置小于0.5)的SDXL模型,效果几乎总是比不加LoRA的SDXL模型更好。
开发出Fooocus这个项目的作者名叫Lvmin Zhang,2021年本科毕业于东吴大学,目前在斯坦福大学读博。
他做过的几个项目,包括ControlNet和style2paints在内,几乎个个都爆火:

现在,最新的这个项目Fooocus,看起来同样很受欢迎。
在社交媒体上,已经有网友自发整出了Fooocus版不同风格的提示词合集Excel。
如果不知道生成什么样的图片,参考这个文档内的提示词就行:

你想好要用Fooocus生成什么样的图像了吗?
项目地址:
https://github.com/lllyasviel/Fooocus
参考链接:
[1]https://twitter.com/lvminzhang/status/1690118840326524928
[2]提示词合集:https://docs.google.com/spreadsheets/d/1AF5bd-fALxlu0lguZQiQVn1yZwxUiBJGyh2eyJJWl74/edit
[3]https://twitter.com/narrativenavi/status/1691235126045552645
[4]https://twitter.com/kiyoshi_shin
—完—
重启与OpenAI的谈判,苹果为iOS 18的AI找“备胎”
如果说在AI大模型崭露头角的2023年,苹果方面的做法是观望,那么到了2024年,他们显然已经不再认为这一轮人工智能浪潮是“AI炒作”(AIhype)了。继此前300亿参数规模的MM1模型亮相后,苹果又在不久前在AI开源社区HuggingFace放出了自研的开源“小模型”OpenELM。站长网2024-05-04 12:36:240000高斯绘画工具开源 可用于艺术创作和机器学习研究
高斯绘画器是一个使用三维高斯斑点绘制图像的框架。它基于高斯斑点渲染技术,可以以非常逼真的方式渲染和重建图像。该项目提供了一个使用Python编写的开源实现,可以用于艺术创作和机器学习研究。项目地址:https://github.com/ReshotAI/gaussian-painters站长网2023-09-05 10:38:080000StyleMamba:一种高效的文本驱动图像风格转换的ai模型
划重点:⭐StyleMamba是一种用于文本驱动图像风格转移的有效框架,使用文本提示来指导风格化过,同时保持原始图像内容。⭐️该研究团队提出了两种独特的损失函数,二阶方向损和掩码损失,以确保图像与文本提示之间的局部和全局风格一致性。⭐️StyleMamba的效果经过多项测试和定性分析确认,优于当前基线方法的性能。站长网2024-05-11 18:13:410000谷歌 DeepMind 首席执行官:人工智能风险类似于气候危机,世界不能拖延应对
站长网2023-10-25 09:12:210000微软发布声音克隆技术Personal Voice 提供1分钟样本即可生成AI语音
微软近日发布了一项名为PersonalVoice的新技术,该技术可以克隆用户的声音,并且能够复制出与原声音完全一致的人工智能语音。用户只需提供1分钟的语音样本,PersonalVoice就能在几秒钟内生成相应的AI语音。站长网2023-11-17 11:17:140002