AI2发布大语言模型开源数据集Dolma 包含3万亿个token
站长网2023-08-25 10:54:080阅
文章概要:
1. AI2推出开源数据集Dolma,包含3万亿个token,来自各类网络内容、学术出版物等。
2. Dolma主要以英文文本为主,遵循开放许可,免费向研究人员开放。
3. Dolma作为开放语言模型OLMo的基础,OLMo计划2024年初发布。
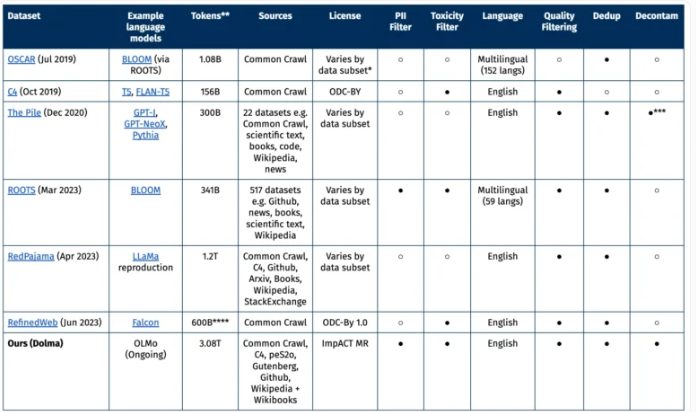
美国艾伦人工智能研究所(AI2)最近发布了一个名为Dolma的开源数据集,其包含了3万亿个token,这些词汇来自包括网络内容、学术出版物、代码和书籍等广泛的来源。Dolma是目前公开可用的同类数据集中最大的一个。

Dolma的数据将为AI2正在开发中的开放语言模型OLMo提供基础。OLMo的目标是成为“最好的开放语言模型”,计划于2024年初发布。为了开发OLMo,AI2构建了庞大的Dolma数据集。
Dolma第一个版本主要以英文文本为主。研究人员使用语言识别模型对数据进行筛选。为弥补少数语言方言的偏差,团队将模型判断为英文置信度50%以上的所有文本都包括在内。未来版本将会包括其他语言。
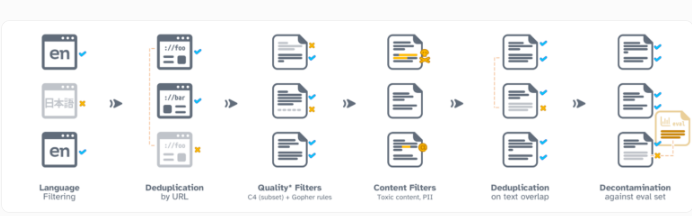
Dolma以开放许可的形式免费向研究人员开放。研究人员需要提供联系信息并同意Dolma的预期用途。同时建立机制允许根据要求删除个人数据。
Dolma的数据大部分来自非营利的Common Crawl项目收集的网络数据。此外还包含其他网络页面、学术文本、代码示例、书籍等。
在AI2看来,理想的数据集应该满足几个标准:开放性、代表性、规模和再现性。它还应该最大限度地减少风险,尤其是那些可能影响个人的风险。
项目网址:https://huggingface.co/datasets/allenai/dolma
0000
评论列表
共(0)条相关推荐
Ouroboros3D:通过3D感知实现图像到3D的生成
划重点:🔍Ouroboros3D是一个集成了多视角图像生成和3D重建的统一3D生成框架🔍通过递归扩散过程,Ouroboros3D实现了从图像到3D的生成🔍Ouroboros3D采用了基于扩散的多视角图像生成和3D重建方法站长网2024-06-06 17:20:590000腾讯混元最新图生视频模型!想动哪里点哪里,诸葛青睁眼原来长这样 | 开源
单击画面中的火箭,输入“发射”prompt,瞬间起飞!就连想要回收火箭,也只需要输入“Launchdown”,再轻轻一点击:马斯克看了都要自我怀疑一下,这火箭发射这么简单,自家星舰成功进入太空怎么那么难(开个小玩笑)??以上效果来自一个新的图生视频模型Follow-Your-Click,由腾讯混元、清华大学和香港科技大学联合推出。食用方法非常友好:站长网2024-03-17 17:42:110001户均网速491.5Mbps!中国宽带现状:百兆普及率94.8%、千兆用户占比近三成
中国电信市场最新动态根据中国信通院发布的数据,截至2024年7月末,中国基础电信企业移动数据流量业务收入为3817亿元人民币,同比下降2.1%。宽带网络普及率提升0000投行预测iPhone价格或飙升:美关税政策重创苹果供应链
快科技4月5日消息,据央视财经报道,美国总统特朗普宣布对等关税”方案后,苹果公司股价连续两个交易日遭遇重挫,市值大幅缩水。投行摩根士丹利测算,对华加征关税将使苹果每年增加约85亿美元的成本。分析人士称,如果苹果将关税成本全部转嫁给消费者,iPhone16ProMax的在美零售价将从现在的1599美元,上涨到2300美元(约合16750元人民币)。0000开源版「ChatGPT Plus」来了,能做数据分析、插件调用、自动上网,落地真实世界的智能体
OpenAIChatGPTPlus订阅付费功能强大,可以实现高阶「数据分析」(AdvancedDataAnalysis)、「插件调用」(Plugins)以及「自动网页浏览」(BrowsewithBing),能够作为日常生活中的重要生产力工具。可是因为商业原因而选择了闭源,研究者和开发者也只能使用而没有办法在其上面做任何的研究或改进。站长网2023-10-25 19:48:330000