3万亿的开放数据集AI2 Dolma发布
即使有许多公开的数据集,也缺乏足够的规模来训练最先进的模型。艾伦人工智能研究所的 Dolma 数据集旨在实现这一目标,以便研究人员能够在大规模上研究数据效应。该数据集的发布不仅为研究人员提供了更高质量和更大规模的数据,还为人工智能的发展开辟了新的可能性。
AI2Dolma 是一个开放的预训练数据集,包含3万亿个标记。它由 Allen AI 研究所创建,用于语言模型的预训练。该数据集的目标是推动大规模自然语言处理系统的研究,并提供一个透明和开放的平台。
项目地址:https://huggingface.co/datasets/allenai/dolma
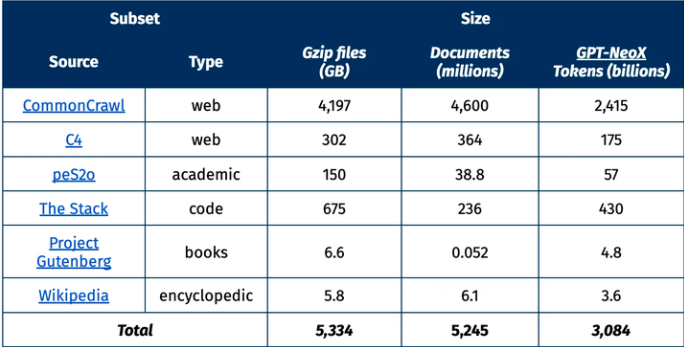
Dolma 数据集包含了来自各种来源的文本,如网络内容、学术出版物、代码、书籍和百科全书资料。该数据集的设计原则包括开放性、代表性、规模和可重现性。
Dolma 的创建过程包括数据处理步骤,如语言识别、质量过滤、去重复、风险缓解等。与闭源数据集相比,Dolma 采取了更多的透明度,提供了更多的信息和工具以便其他研究者进行研究和评估。Dolma 数据集已经发布,并在 AI2ImpACT 许可下可在 HuggingFace Hub 上下载使用。
特点:
1. 数据规模庞大:AI2Dolma 是迄今为止最大的开放数据集,包含了来自多个来源的3万亿个标记。这使得它成为训练大规模语言模型的理想选择。
2. 开放性:AI2Dolma 的目标是以透明和开放的方式构建语言模型。它的数据集和模型遵循 AI2ImpACT 许可证,可以供其他研究人员使用和研究,促进了整个研究社区的合作和发展。
3. 代表性:AI2Dolma 的数据集与其他语言模型数据集(无论是闭源还是开源)具有相似的来源和处理方式,确保了模型在广泛领域的能力和行为与其他语言模型一致。
4. 可复现性:AI2Dolma 的数据处理工具和方法都是开放可用的,其他研究人员可以复现和使用这些工具来创建自己的数据集。这种可复现性有助于推动研究的进展和结果的验证。
5. 风险控制:AI2Dolma 在数据处理过程中采取了一系列风险控制措施,包括个人信息的删除、有害内容的过滤等,以最大程度地降低数据使用可能带来的风险。
6. 其他语言支持:虽然 AI2Dolma 的第一个版本仅包含英文数据,但它的设计目标是支持多种语言。未来的版本可能会扩展到其他语言,从而满足不同语言背景下的研究需求。
微信新版本,几大实用功能更新
近日,微信发布了8.0.48测试版本。这次更新涉及到了视频号、朋友圈、静音、表情包等功能的变化,更新了很多比较实用的功能,快来和我们一起看看这些新变化。01视频号能投屏了新版本微信中,在视频号中出现了新功能:可直接进行投屏。具体操作为:视频号某一作品下,点击分享按钮,在分享的选项中选择「投屏」功能。点击「投屏」后,即可将视频号内容投屏到其他设备上。站长网2024-03-12 15:37:120000英伟达 CEO 黄仁勋:芯片制造是 AI 的「理想应用」 下一波浪潮是「具身人工智能」
英伟达创始人兼首席执行官黄仁勋周二在比利时安特卫普举行的ITFWorld2023半导体会议上表示,芯片制造是英伟达加速和人工智能计算的「理想应用」。他详细阐述了计算技术的最新进展如何加速「世界上最重要的产业」,并通过视频向来自半导体、科技和通信行业的领导人发表讲话。站长网2023-05-18 09:56:020000马斯克推出名为 Grok 的具有「叛逆倾向」的人工智能聊天机器人
特斯拉首席执行官马斯克最近推出了一款名为Grok的人工智能聊天机器人,该机器人受到《银河系漫游指南》的启发,具有「叛逆倾向」(rebelliousstreak)。尽管在上周警告说AI是「人类面临的最大威胁之一」,但马斯克表示,这款与ChatGPT竞争的聊天机器人将在测试后向他的X平台的高级订阅用户提供。站长网2023-11-06 09:08:130000市场监管总局修订出台禁止滥用知识产权排除、限制竞争行为规定
据国家市场监督管理总局消息,为鼓励创新,维护知识产权领域公平竞争的市场秩序,助力全国统一大市场建设和知识产权强国建设,结合近年来反垄断监管执法的新形势、新情况、新问题,市场监管总局修订出台了《禁止滥用知识产权排除、限制竞争行为规定》,将于2023年8月1日起正式施行。站长网2023-06-30 01:34:590001考勤打卡提醒异常!钉钉紧急修复 官方道歉:耽误大家准点下班了
快科技8月1日消息,今日晚间,钉钉官博发文,称今天下午17点30分,钉钉考勤打卡的提醒出现异常(实际打卡已成功,仅返回信息有延迟),经紧急处理,该异常已经于17点45分修复完毕。钉钉表示:耽搁大家准点下班万分抱歉!(下次就算崩也尽量在上班的时候崩)”。有网友调侃道,我以为我们公司崩了,原来是你崩了”点了多次,还以为是自己网络有问题,原来是你”。站长网2023-08-01 21:35:010000