拖拽下图像就能生成视频,中科大、微软等DragNUWA属实惊艳
随着 ChatGPT、GPT-4、LLaMa 等模型的问世,人们越来越关注生成式模型的发展。相比于日渐成熟的文本生成和图像生成,视频、语音等模态的 AI 生成还面临着较大的挑战。
现有可控视频生成工作主要存在两个问题:首先,大多数现有工作基于文本、图像或轨迹来控制视频的生成,无法实现视频的细粒度控制;其次,轨迹控制研究仍处于早期阶段,大多数实验都是在 Human3.6M 等简单数据集上进行的,这种约束限制了模型有效处理开放域图像和复杂弯曲轨迹的能力。
基于此,来自中国科学技术大学、微软亚研和北京大学的研究者提出了一种基于开放域扩散的新型视频生成模型 ——DragNUWA。DragNUWA 从语义、空间和时间三个角度实现了对视频内容的细粒度控制。本文共一作殷晟明、吴晨飞,通讯作者段楠。

论文地址:https://arxiv.org/abs/2308.08089
以拖动(drag)的方式给出运动轨迹,DragNUWA 就能让图像中的物体对象按照该轨迹移动位置,并且可以直接生成连贯的视频。例如,让两个滑滑板的小男孩按要求路线滑行:


还可以「变换」静态景物图像的相机位置和角度:


方法简介
该研究认为文本、图像、轨迹这三种类型的控制是缺一不可的,因为它们各自有助于从语义、空间和时间角度控制视频内容。如下图1所示,仅文本和图像的组合不足以传达视频中存在的复杂运动细节,这可以用轨迹信息来补充;仅图像和轨迹组合无法充分表征视频中的未来物体,文本控制可以弥补这一点;在表达抽象概念时,仅依赖轨迹和文本可能会导致歧义,图像控制可以提供必要的区别。

DragNUWA 是一种端到端的视频生成模型,它无缝集成了三个基本控件 —— 文本、图像和轨迹,提供强大且用户友好的可控性,从语义、空间和时间角度对视频内容进行细粒度控制。


为了解决当前研究中有限的开放域轨迹控制问题,该研究重点关注三个方面的轨迹建模:
使用轨迹采样器(Trajectory Sampler,TS)在训练期间直接从开放域视频流中采样轨迹,用于实现任意轨迹的开放域控制;
使用多尺度融合(Multiscale Fusion,MF)将轨迹下采样到各种尺度,并将其与 UNet 架构每个块内的文本和图像深度集成,用于控制不同粒度的轨迹;
采用自适应训练(Adaptive Training,AT)策略,以密集流为初始条件来稳定视频生成,然后在稀疏轨迹上进行训练以适应模型,最终生成稳定且连贯的视频。

实验及结果
该研究用大量实验来验证 DragNUWA 的有效性,实验结果展示了其在视频合成细粒度控制方面的卓越性能。
与现有专注于文本或图像控制的研究不同,DragNUWA 主要强调建模轨迹控制。为了验证轨迹控制的有效性,该研究从相机运动和复杂轨迹两个方面测试了 DragNUWA。
如下图4所示,DragNUWA 虽然没有明确地对相机运动进行建模,但它从开放域轨迹的建模中学习了各种相机运动。

为了评估 DragNUWA 对复杂运动的精确建模能力,该研究使用相同的图像和文本对各种复杂的拖动(drag)轨迹进行了测试。如下图5所示,实验结果表明 DragNUWA 能够可靠地控制复杂运动。

此外,DragNUWA 虽然主要强调轨迹控制建模,但也融合了文本和图像控制。研究团队认为,文本、图像和轨迹分别对应视频的三个基本控制方面:语义、空间和时间。下图6通过展示文本(p)、轨迹(g)和图像(s)的不同组合(包括 s2v、p2v、gs2v、ps2v 和 pgs2v)说明了这些控制条件的必要性。

亚马逊 CEO 解释将如何在人工智能竞赛中与微软、谷歌竞争
站长之家(ChinaZ.com)7月7日消息:亚马逊首席执行官安迪·贾西(AndyJassy)认为,这家零售和云计算巨头目前还不应该被排除在人工智能竞赛之外。在接受CNBC的采访中,贾西对亚马逊在人工智能方面落后于微软和谷歌的观点提出挑战,并将其比作「实质周期」之前的「炒作周期」。站长网2023-07-08 17:00:550000百度文库智能文档助手开启内测,这AI也太能写了吧!
作为一名靠码字为生的文字编辑,卡文算是我在工作过程中遇到的最为烦恼的事了。经常会遇到一种情况:大脑是清醒的,注意力是集中的,文章本在按照事前规划的提纲逐步撰写着,可突然出现了一个节点,或者因为遇到知识盲区、抑或表达能力遇到瓶颈,一阵子就只能看着屏幕上的空白段落发呆……“文思泉涌”似乎只存在于传说中,这种“如鲠在喉”的“卡文”感觉,每一个文字工作者应该都不陌生。站长网2023-05-26 12:07:210005OpenAI联合创始人Reid Hoffman认为Sam Altman回归将使公司变得更好
**划重点:**1.🗣️**ReidHoffman支持SamAltman:**OpenAI联合创始人ReidHoffman表示,他对SamAltman再次领导人工智能公司感到高兴,认为公司会因此变得更好。2.🤯**震惊的董事会反应:**Hoffman离开OpenAI董事会后,他对其他曾共事的董事会成员对SamAltman的信任感到震惊,尤其是在公司最近的混乱局面中。站长网2023-12-07 09:40:510000大模型生成提速2倍!单GPU几小时搞定微调,北大数院校友共同一作丨开源
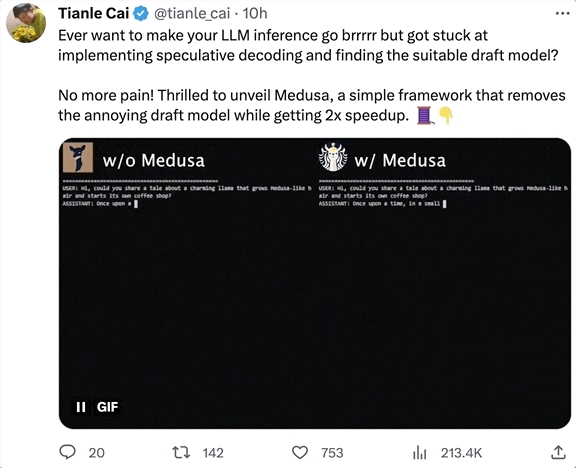
只需给大模型“加点小零件”,推理速度立刻提升2倍!不需要额外训练一个模型,也不需要对计算硬件做优化,单张A100最快几小时就能微调完成。这项新研究名叫Medusa(美杜莎),来自普林斯顿、UIUC、CMU和康涅狄格大学,FlashAttention作者TriDao也在其中。目前,它已经成功部署到伯克利70亿参数的“骆马”Vicuna中,后续还会支持其他大模型,已经登上GitHub热榜:站长网2023-09-18 09:05:520000大模型开山鼻祖!InstructGPT发布两周年了
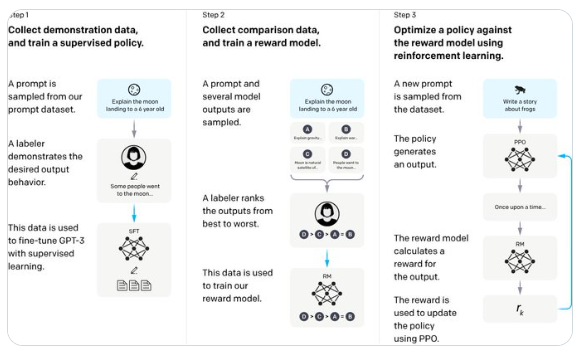
今天是InstructGPT发布两周年的纪念日,它是现代大语言模型的开山鼻祖。JimFan介绍了InstructGPT的重要性并且说了几条关于InstructGPT非常有意思的点。还展示了InstructGPT中非常经典的三步LLM训练方法的图片,我也顺便让GPT-4解释了一下也顺便放在下面。站长网2024-01-29 10:20:240000