没有大招的火山引擎,拿下70%大模型玩家
有没有在开发大模型?在学习。
什么时候发布大模型?没计划。
当被问起自研大模型,字节跳动副总裁杨震原口风甚严。但席卷全球的这场大模型竞逐战,没有人会主动放弃阵地。
最新线索,在上海露出端倪。
火山引擎对外的最新技术、产品发布动作中,我们发现:炼大模型的基础设施,不仅已经在字节内部运转,还到了能够对外输出“技术秘籍”的阶段。
直观的数字,更能说明情况:
抖音2022年最火特效「AI绘画」,就是在火山引擎机器学习平台上训练而成。在训练场景下,基于Stable Diffusion的模型,训练时间从128张A100训练25天,缩短到了15天,训练性能提升40%。
在推理场景下,基于Stable Diffusion的模型,端到端推理速度是PyTorch的3.47倍,运行时对GPU显存占用量降低60%。
而就在全球最大云厂商AWS宣布,加入大模型竞赛,并且定位是“中立平台”,会接入Anthoropic、StabilityAI等模型厂商的大模型之际,量子位也获悉:
火山引擎,也在以类似路径探索大模型的落地,做法是用“机器学习平台 算力”为大模型企业提供AI基础设施。火山引擎总裁谭待透露,国内几十家做大模型的企业,七成已经在火山引擎云上。
大模型企业为什么会选择火山引擎?我们和火山引擎机器学习总监吴迪聊了聊。
大模型趋势,写在云计算的最新技术里
在AI方面,此番火山引擎重点提到了两个平台:机器学习平台和推荐平台。
机器学习平台
其中,机器学习平台涉及当下科技圈最热的两个话题——庞大算力的调度问题,以及AI开发的效率问题。
先来看算力调度。
说到大模型时代,OpenAI首席执行官Sam Altman曾发表观点称,“新版摩尔定律很快就要到来,宇宙中的智能每18个月翻一倍”。
而这背后,模型训练开发所需要的算力规模,可想而知。
但用算力,实际上并不是一个纯堆硬件的事情。举个例子,如果机器学习框架跟底层的硬件是各自独立的一套,那在训练AI模型时,由于通信延迟、吞吐量等问题,训练效率就无法最大化。
简单来说,就是很多算力会在这个过程中被浪费掉。
解决方法,是软硬一体。
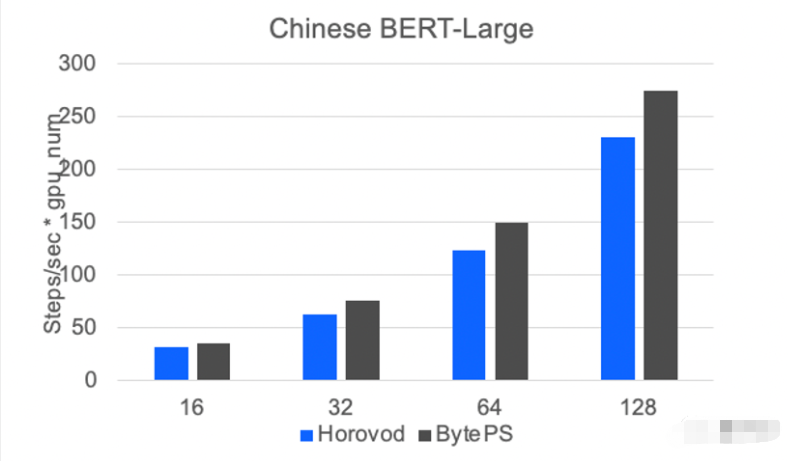
吴迪介绍,火山引擎的自研DPU,将算力层和平台层统一起来进行了整体优化。比如,将通信优化的算法直接写到网卡硬件中,以降低延迟、削减拥塞。
测试数据显示,火山引擎的通信框架BytePS,在模型规模越大时,收益会越高。
而在AI开发效率方面,火山引擎推出了Lego算子优化。
具体而言,这一框架可以根据模型子图的结构,采用火山引擎自研高性能算子,实现更高的加速比。
前文提到的抖音特效训练效率的提升,就得益于此:
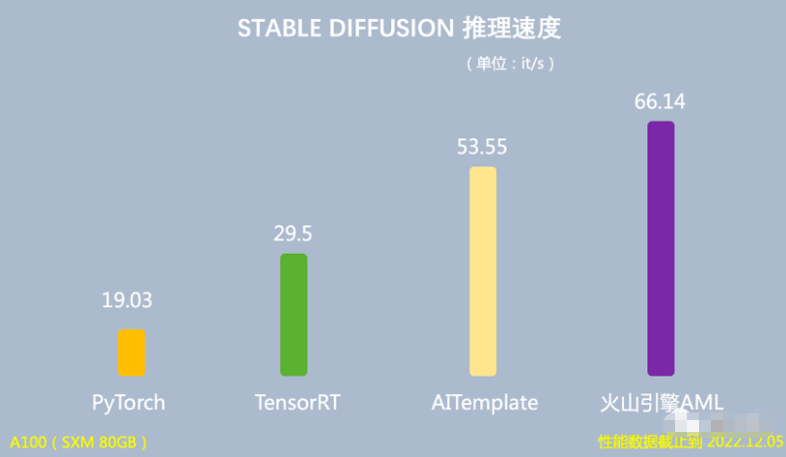
在推理场景下,使用Lego算子优化,可以将基于Stable Diffusion模型的端到端推理速度提升至66.14it/s,是PyTorch推理速度的3.47倍,运行时GPU显存占用量降低60%。
在训练场景下,在128张A100上跑15天,模型即可训练完成,比当时最好的开源版本快40%。
目前,火山引擎这一套机器学习平台,已经部署到了MiniMax的文本、视觉、声音三个模态大模型训练和推理场景中。
MiniMax联合创始人杨斌说,依托火山引擎机器学习平台,MiniMax研发了超大规模的大模型训练平台,高效支撑着三个模态大模型每天千卡以上的常态化稳定训练。在并行训练上实现了99.9%以上的可用性。除了训练以外,MiniMax也同步自研了超大规模的推理平台,目前拥有近万卡级别的GPU算力池,稳定支撑着每天上亿次的大模型推理调用。
有稳健的大模型基础设施,MiniMax从零开始自主完整地跑通了大模型与用户交互的迭代闭环,实现从月至周级别的大模型迭代速度,和指数级的用户交互增长。MiniMax和火山引擎一起为大模型训练搭建了高性能计算集群,一起致力于提升大模型训练的稳定性,保证了千卡训练的任务稳定运行数周以上。
从今年开始,MiniMax又和火山引擎在网络和存储上进行了更深入的优化合作,实现更低的网络延迟,将带宽利用率提升了10%以上。
吴迪坦言,“软硬一体、通信优化、算子优化都不是新概念,火山引擎机器学习平台也没有特别牛、特别超前的大招。我们靠的就是务实严谨地不断把细节做扎实,把重要技术锤炼到位,这样才能赢得客户的信任。”
推荐平台
机器学习平台之外,这次在自家看家本领——推荐系统上,火山引擎对外拿出了推荐系统全套解决方案:从物料管理,到召回排序,再到效果分析、A/B测试和模型算法,都可以开箱即用。
而作为产业界近年来落地最为成功的AI应用之一,在推荐领域,深度学习模型越来越大、越做越深的趋势,也早已显现其中。
吴迪介绍,由于推荐是一个高度定制化的场景,每个人的兴趣、画像都有单独的embedding,因此大规模稀疏模型很重要。
同时,由于真实世界在时刻变化,因此背后又存在一重实时训练的挑战。
这都对传统的深度学习框架提出了很大的挑战。
为此,火山引擎不仅将以上工程实现进行封装,推出了基于TensorFlow的机器学习训推一体框架Monolith,还拿出了针对智能推荐的高速GPU训练和推理引擎——Monolith Pro。
值得关注的是,Monolith Pro覆盖的场景包括:
针对关键场景的超大模型,使用高密度GPU进行超高速训练;
覆盖更多场景的模型,混合使用CPU GPU高速训练。
吴迪进一步解释说,推荐模型需要做大做深,才能对众多事物之间的关联有更好的理解——这一点,如今已经在GPT引发的一系列现象上得到充分验证。
因此在现在这个时间点,对于任何正在开展推荐广告业务的公司而言,高价值的数据是一方面,另一方面,找到训练更强、更大、更实时模型的方法,对整个系统进行智能化升级,已经到了一个关键期。


所以,Monolith Pro又具体能实现怎样的效果?吴迪透露,基于Monolith Pro,抖音内部的某重要广告场景,原本一次广告训练需要15个月样本,训练时间为60小时,现在只需要5小时就能完成。
工程师可以做到上午启动训练,下午就能开A/B测试了(笑)。
大模型改写云计算规则
由ChatGPT而起,在海内外一波波大模型的发布中被推至高潮,一场新的技术变革已然势不可挡。
云计算,作为一个早已深深与AI关联的业务,站立桥头,也最早面临着规则被重新改写的境况。
随着大模型能解决越来越多下游任务,如何用大模型,又成为了新的问题:无论是训练还是推理,大模型都需要很强的基础设施支持。
云计算成为了最便捷的上车途径。同时,云厂商们也势必要面向大模型,重塑自身云产品的面貌。
吴迪认为,作为一项技术,未来大模型会是百花齐放的局面。丰富的需求会催生出若干成功的模型提供商,深入满足千行百业的业务需求。
与此同时,大模型的应用也面临若干基础问题:
基础大模型可能还需要用更多高质量数据,做进一步的增量学习和finetune,才能真正在产业中落地应用。整个流程需要更为敏捷和易用。
大模型将成为大数据时代的“中央处理器”,它能够控制插件、接口,以及更丰富的下游模型。大模型需要这些“手”和“脚”,才能进入我们生活的方方面面。
随着大模型应用的增多,数据安全和信任将成为产业关注的焦点。
推理效率。大模型的训练成本高昂,但长期来看,全社会投入在大模型推理上的开销将逐渐超过训练成本。在微观上,能以更低单位成本提供大模型相关服务的公司,将获得竞争优势。
但可以肯定的是,大模型改造各行各业的浪潮已至。
有人正面迎战,有人从更底层的问题出发,尝试破解新的问题和挑战。
共同点是,大模型的潮头来得迅猛激烈,但在第一线迎接风暴的,从来不是没有准备之人。
现在,到了检验真正AI能力和积累的时刻。至少在与大模型相伴相生的云计算领域,精彩才刚刚开幕。
—完—
公众号上线新功能!个人微信可以直接写文章发表了!
这两天,微信灰度上线了一个新功能“我的公众号”。点击个人微信号首页中的“公众号”,进入“公众号列表”(即原先的订阅号列表界面),点击右上角“人像图标”,新增了一个新版块“我的公众号”。在该版块中有多个新功能,可以点击“发图文”和“写文章”,直接创作内容,保存草稿,发表内容,并且可以查看互动和私信消息。0000900万人观看解清帅直播带货 同情的流量池能否装下变现的野心?
这两年舆论和关注度有一个统一的代名词叫做“流量”,当流量落在普通人身上时往往能带来命运的改变。因此趁着流量还在,开直播做带货已经成为社会常态。早前的张同学,去年的郑女士,今年的桃子老师、黄老师,都在关注度还不错的时候切入了直播带货业务。最近,又一位“名人”加入直播带货行列,他就是刚刚因“千万富翁”寻子被大家关注的解清帅。0000亚马逊APP测试新AI功能,不仅能解答产品问题还能逗你笑
划重点:🤖亚马逊在iOS和Android移动应用中测试新的AI功能,允许用户就产品提出具体问题。💡AI工具可解答关于产品的实际问题,还能回答更富创意的查询,如写一首关于雪地靴的圣诞颂歌。🚀该功能仍在测试阶段,目前只有一些用户可以使用。站长网2024-01-18 14:59:470000低俗擦边!抖音下架《世界首富是我爹》等209部违规微短剧
快科技12月11日消息,今日,抖音安全中心”公众号发布抖音关于打击违规微短剧的公告”,公告称,平台11月累计下架违规微短剧209部。据了解,11月下架的违规短剧包括《摊牌了,世界首富是我爹》《美女们把我包围了》《重生之职场狂人》等。这些短剧违规原因包括存在宣扬拜金主义、展现浮夸奢靡生活、宣扬不良婚恋观、价值导向不良、内容低俗等违规情况。部分违规微短剧账号公示如下:站长网2024-12-11 20:27:040000快手治理作弊搬运行为 7月处罚违规账号400余个
快手发布《关于作弊搬运行为的处罚公告》称,近期,平台在巡检中发现,部分账号存在“借助作弊搬运手段,不当获取平台流量”的行为,此类行为与平台鼓励原创理念相悖。针对此类违规行为,平台开展了专项治理。2023年7月,平台已处罚违规账号400余个。快手称,违规行为包含但不限于以下类型:1、将搬运的他人视频与自己视频拼接,以达成变现目的;站长网2023-08-04 08:32:130000











