专家呼吁:Deepfake检测工具须考虑深色肤色群体 避免偏见
站长网2023-08-19 15:28:180阅
本文概要:
1. 担心训练数据集中的偏见会导致少数族裔承受欺诈、诈骗和虚假信息的压力。
2. 大部分深度伪造检测器是基于依赖于用于训练的数据集的学习策略。然而,这些检测方法并不总是适用于深色肤色的人群。
3. 缺乏对所有种族、口音、性别、年龄和肤色的包容性训练集可能会导致偏见。
专家警告说,为应对日益严重的深度造假(看起来逼真的虚假内容)威胁而开发的检测工具必须使用包含较深肤色的训练数据集,以避免偏见。
目前大多数Deepfake深度伪造检测器都基于依赖于训练数据集的学习策略,并利用人眼无法察觉的迹象进行检测,例如监测血液流动和心率。

然而,这些检测方法并不总是适用于深色肤色的人群,如果训练集中不包含所有种族、口音、性别、年龄和肤色的样本,就会存在偏见的问题。
专家们担心这种偏见将会导致对少数群体进行深度伪造的欺诈、诈骗和虚假信息的增加。为了解决这个问题,深度伪造检测工具需要使用视觉线索,如血液流动和心率检测,但由于深色肤色在视频流中很难提取心率,这些工具对少数群体的表现会较差。
因此,需要建立新的数据集,并使用更具代表性的肤色范围来训练机器学习模型,以确保包容性和准确性。然而,目前世界上还没有规定相应的监管措施,这导致偏见在新技术中仍然存在和复制。
为了解决这个问题,哈佛大学社会学教授兼谷歌客座研究员埃利斯·蒙克 (Ellis Monk) 开发了蒙克肤色量表。它是一种比科技行业标准更具包容性的替代尺度,并且将提供比可用于数据集和机器学习模型更广泛的肤色。专家们呼吁建立更具包容性的训练集和标准化的测量方法,以解决深度伪造检测工具的偏见问题。
0000
评论列表
共(0)条相关推荐
亚马逊用比 GPT-4 多两倍的参数训练 Olympus 人工智能模型
在大型语言模型(LLMs)领域,科技巨头之间的竞争愈发激烈,这些模型是像OpenAI的ChatGPT这样的工具的AI技术基础。根据路透社内部消息人士的消息,亚马逊正计划推出自己的产品,投入巨资训练其自己的名为「Olympus(奥林匹斯)」的模型,以对抗ChatGPT和谷歌的Bard。站长网2023-11-09 11:12:380000苹果 iPhone 16 或回归与 iPhone 12 一样的垂直摄像头布局
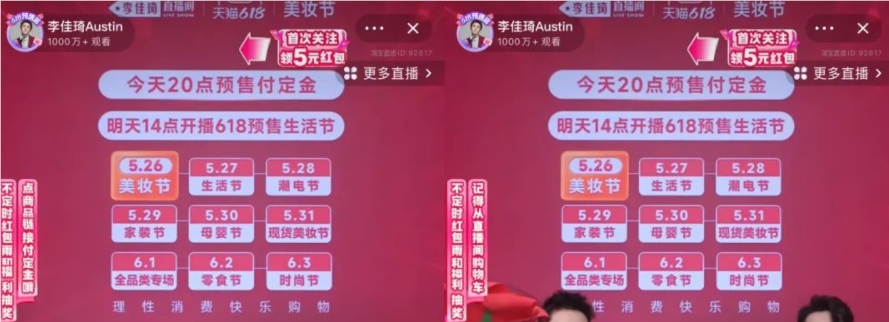
根据Twitter账号@URedditor分享的信息,低端iPhone16型号的后置摄像头镜头将采用垂直排列。这种设计变化很可能也会应用于iPhone16Plus。iPhone14垂直摄像头布局站长网2023-05-23 11:58:480001直击618开局:李佳琦稳定发挥,辛巴杠上榴莲,小红书明星主播奇袭
李佳琦在直播间敲响锣鼓,今年618大促正式拉开帷幕。“10万了,疯了”“好夸张,太夸张了”……5月26日预售当晚,面对刚上链接就被爆买的多个产品,连李佳琦本人都发出感慨。预售倒计时的李佳琦和助播团据新榜编辑部不完全统计,整场直播累计上架338个单品链接,至少30个单品的销量超过10万件,19个单品直接库存售罄,按照商品页面显示的成交价格来算累计销售额预估超44亿元。站长网2023-05-27 14:48:330001动视暴雪CEO年前离职 微软游戏业务负责人将接任
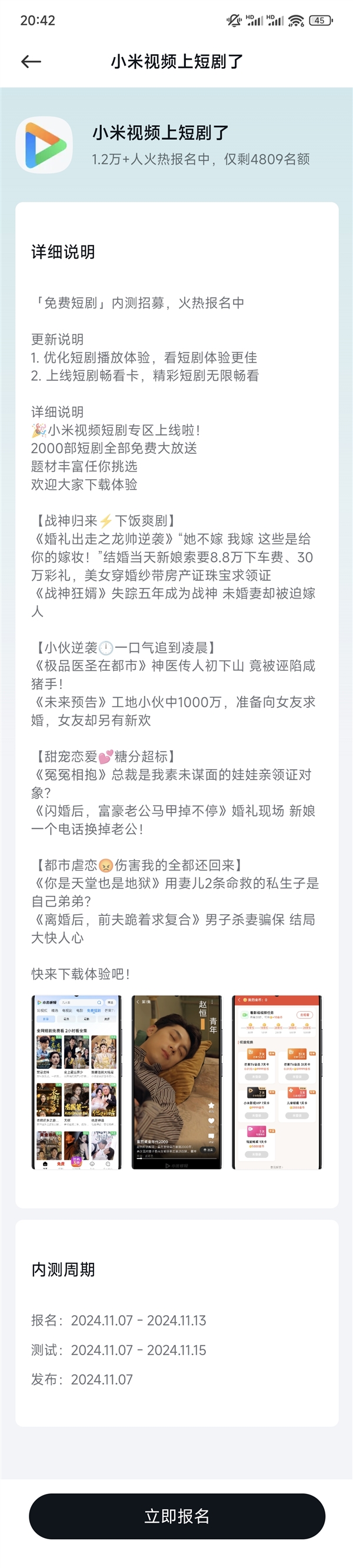
动视暴雪的首席执行官鲍比・科蒂克将于12月29日正式卸任,而微软游戏业务首席执行官菲尔・斯宾塞将负责监管动视暴雪。据内部电子邮件显示,大部分中层领导并没有变动,但首席传播官LuluMeservey和暴雪King副董事长HumamSakhnini将在未来几个月离开公司。0000小米视频免费短剧内测招募来了:2000部短剧免费看
小米视频推出免费短剧专区内测,优化播放体验,上线畅看卡报名日期:2024年11月7日-2024年11月13日测试时间:2024年11月7日-2024年11月15日小米视频已上线短剧分区,汇聚爱奇艺、一览、七彩剧院等多渠道的短剧资源。目前上线的剧集类型包括战神逆袭、甜宠恋爱、都市剧等。小米视频App仅限小米手机使用,整合了爱奇艺、芒果TV等视频平台的内容。站长网2024-11-14 16:30:240000