英伟达发布 CALM 人工智能模型:能够生成 500 亿个身体动作
站长网2023-08-11 15:04:180阅
现在有了英伟达的新型 AI 语言模型 CALM(Conditional Adversarial Latent Models),理论上你可以借助它来创建自己的视频游戏角色。CALM 是一种用于训练可控虚拟角色(也就是视频游戏角色)的 AI 语言模型。
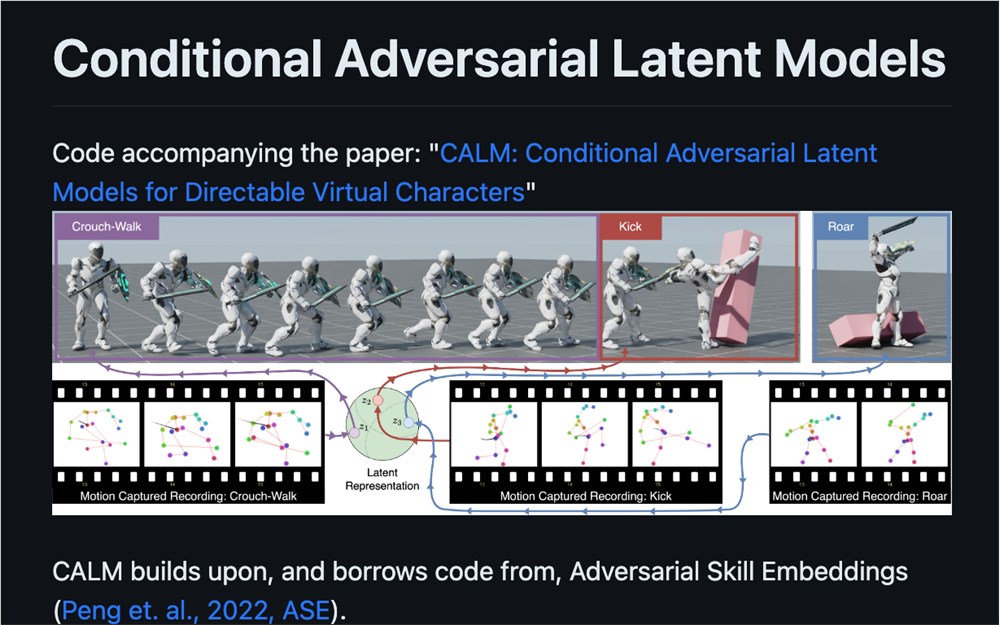
英伟达与以色列理工学院、巴伊兰大学和西蒙弗雷泽大学合作撰写了一篇详细介绍该模型结构和训练方法的论文。
CALM 在一个模拟现实中进行了连续 10 年的训练,相当于真实世界时间中的 10 天。经过这次训练,该模型能够生成 500 亿个身体动作。由 CALM 生成的角色是一个带有白纹样式的战士,他能够模仿并展示与行走、奔跑和挥剑等本能人类动作相关联的动作。
我们提出了条件对抗潜在模型 (CALM),这种方法可以为用户可控制互动虚拟角色生成多样化且直接性强的行为。通过使用仿真学习,CALM 学习到一种捕捉人类运动复杂性和多样性特征,并使得对角色运动具有直接控制能力的表示形式。该方法同时学习控制策略和运动编码器,后者可以在不仅仅是复制的情况下重构给定运动的关键特征。结果表明,CALM 学习到了一种语义化的运动表示形式,使得对生成的动作具有控制能力,并且可以进行高级任务训练时进行风格调节。一旦训练完成,角色就可以通过直观易用的界面来操控,类似于视频游戏中常见的方式。
你可以将 CALM 代码应用到自己的工作中来创建自己的视频游戏角色或类似 AI 模型。你可以在 GitHub 上找到相关代码。
GitHub:https://github.com/NVlabs/CALM
0000
评论列表
共(0)条相关推荐
鸿蒙星河版WPS来了!核心功能版本已交付:原生开发、无缝协同
快科技3月15日消息,WPS和华为今天官宣,鸿蒙星河版WPSOffice已完成核心功能版本交付。这是金山办公基于鸿蒙星河版(HarmonyOSNEXT)打造的原生应用,基于鸿蒙系统的生互联、原生流畅等特性专门开发。据介绍,鸿蒙星河版WPS不仅能在PC端更流畅运行,还能实现与手机、平板、智慧屏等多种设备之间的无缝流转和跨端协同,带来更智能便利的办公体验。站长网2024-03-15 16:47:400000全球最大规模、最全场景、最全产业!中国移动完成5G RedCap现网规模试验
快科技2月19日消息,今天,中国移动官方宣布,携手10余家合作伙伴率先完成全球最大规模、最全场景、最全产业的RedCap(5G轻量化)现网规模试验。同时中国移动还推动首批芯片、终端具备商用条件,RedCap端到端产业已全面达到商用水平。0000OpenAI、微软押注,大模型应用的尽头是AI Agent ?|对话面壁智能
你见过Agent们“吵架”么?“这个产品需要具备XX需求,为什么没有?”,“你提出的需求完全不合理,技术上达不到!”,现场顿时乱作一团,越来越多的“员工”也被卷进了这场大乱斗中。激烈的争吵声越过了屏幕外,面壁智能的测试人员通过后台日志,发现Agents正在上演一场“职场大戏”。站长网2023-11-16 14:04:060005微软重组 Xbox 游戏和营销团队:为人工智能和游戏的未来做好准备
站长网2023-10-27 10:03:300000华为发布ULTIMATE DESIGN非凡大师产品 华为WATCH黄金版
在今天的秋季全场景新品发布会上,华为常务董事、终端BGCEO、智能汽车解决方案BU董事长余承东发表了演讲。余承东宣布,华为发布全新超高端品牌ULTIMATEDESIGN非凡大师。他表示,历经多年沉淀,华为推出极致美学、极致工艺、极致创新的集大成者,从PORSCHEDESIGN到ULTIMATEDESIGN,品牌实现全面升级。站长网2023-09-25 15:38:240000