华为率先把大模型接入手机!小艺+大模型,智慧助手智商+++
好家伙,华为HarmonyOS接入大模型,智慧助手可以这么玩了吗?
只需一句中文指令,华为小艺就写出一封英文邮件:

可以把自己的照片用AI做成不同风格:

还能说一长串指令,让它自己创建复杂场景,大白话就能听得懂:
这就是华为HarmonyOS4中的全新小艺。
它是在华为盘古L0基座大模型的基础上,融入大量场景数据,对模型进行精调,最后炼成的一个L1层对话模型。
能搞定文本生成、知识查找、资料总结、智能编排、模糊/复杂意图理解等任务。
而且也可以调用各种APP服务,实现系统级的智能化体验。
所以,全新华为小艺,到底能做哪些事?
更聪明、更能干、更贴心
基于大模型能力,华为小艺这一次主要在三方面做了升级:
智慧交互
高效生产力
个性化服务
具体能力提升包括更自然语言对话、玩机知识问答、查找生活服务、对话识别屏幕内容、生成摘要文案图片等。
首先,智慧交互升级让对话、交互更自然流畅了。
华为小艺可以听懂大白话,理解模糊意图和复杂命令。
找不到最新的壁纸设置功能、也不知道功能名称,可以直接问:
那个可以根据天气实时变化的壁纸怎么换?

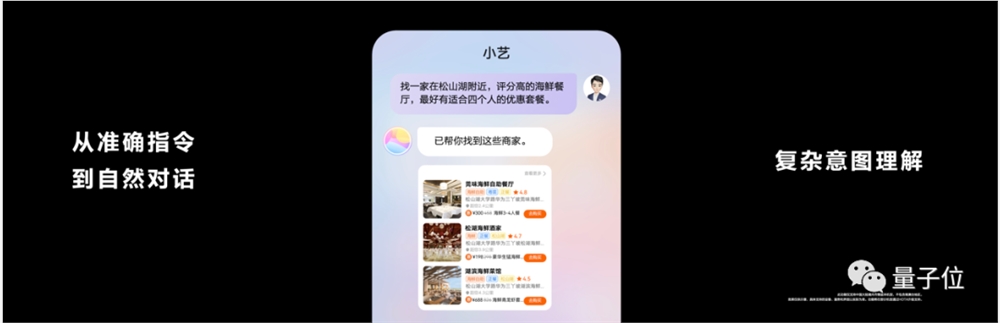
或者是一个复杂的命令,包含多个要求的那种:
找一家松山湖附近,评分高的海鲜餐厅,最好有适合四个人的优惠套餐。
小艺也能调用服务找到满足要求的餐厅。
同时小艺也具备多模态能力,能理解图像内容。这样原本需要用户自己看完再手动操作的步骤,也能交给小艺了。
比如让它看一张邀请函,然后说:
导航去图上的地址。
它能够提取出图上地址信息,并调用地图服务导航。

或者是把邀请函中的联系信息保存,可以看到它能够很好理解图像中的文本信息。

更进一步,现在还能通过小艺进行复杂任务编排,不用咱们自己手动反复设置了。
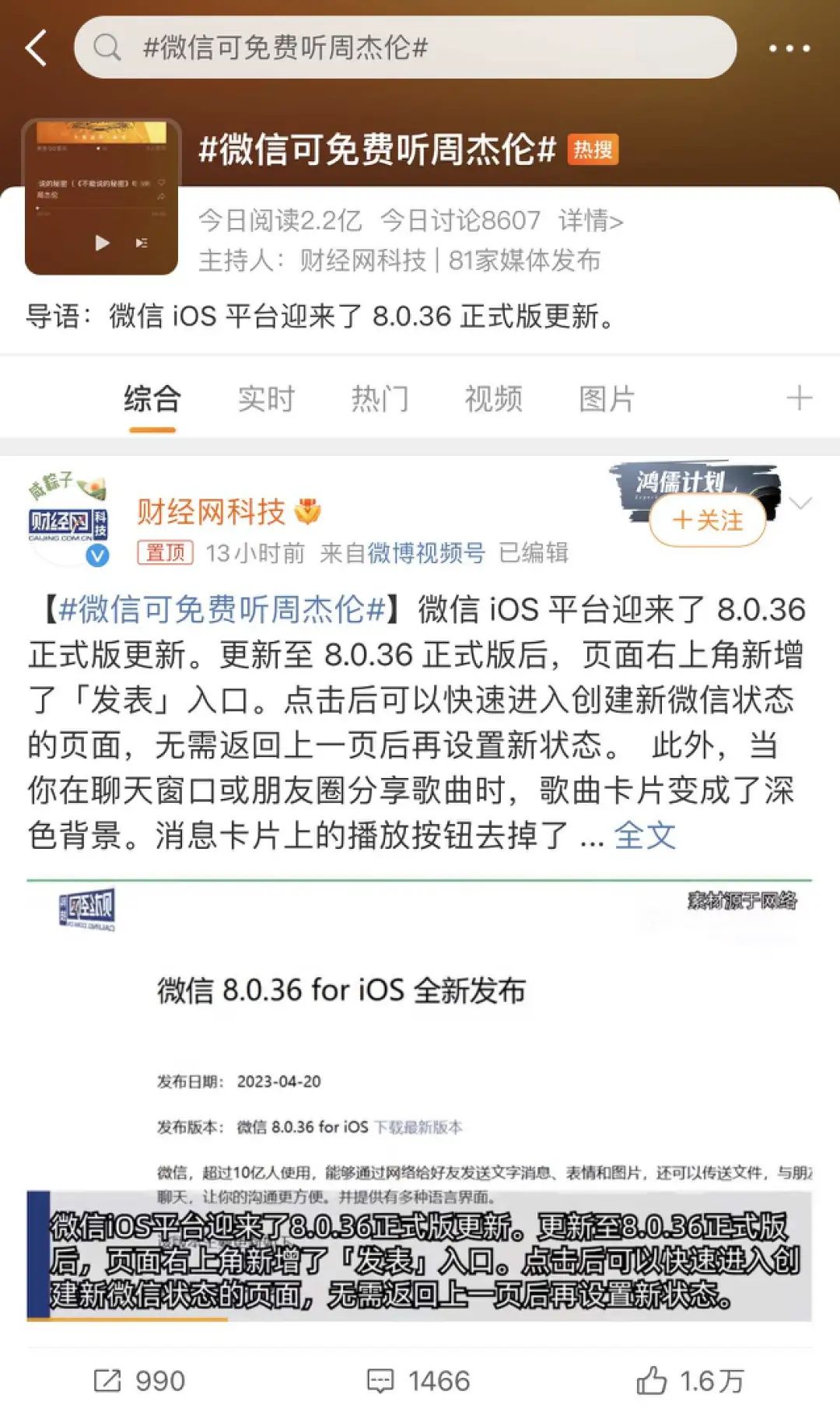
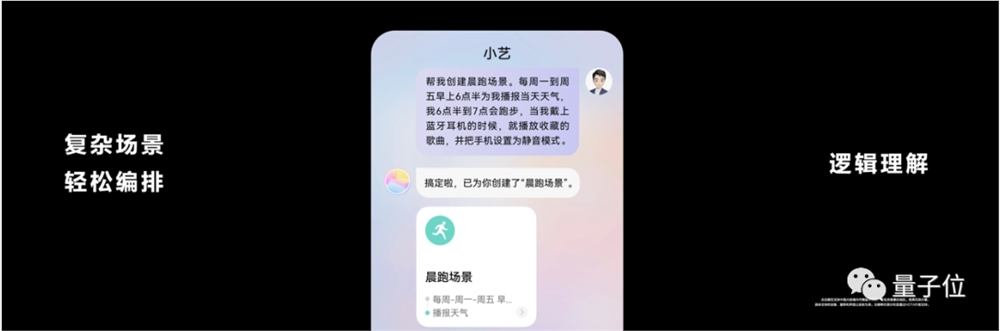
比如可以让它设置一个晨跑场景:
帮我创建晨跑场景。每周一到周五早上6点半为我播报当天天气。当我戴上蓝牙耳机的时候,就播放收藏的歌曲,并把手机设为静音模式。
小艺能够听懂这一长串要求,再去调用不同功能。并且可以基于手机状态(是否连接蓝牙耳机),来自行判断是否要执行某些操作。
其次,得益于大模型等能力加持,现在小艺可提供更高效的生产力工具。
帮你看、读、写都没问题。
比如给它看一篇英文文章,然后提问这篇文章中讲了什么?
小艺就能用中文做出通俗简洁的解释。

如果用户过去让它记住过一些信息,也能调用出来生成相应内容。
过几天就要约David见面聊项目了,结合上次会议记的信息,写一份英文会议预约邮件。

包括开头提到的,小艺也能利用AI视觉能力,将照片创作成多种风格。
最后,作为智慧助手,小艺现在支持更加个性化服务,也能更懂你。
可以当记事本、备忘录使用,一些小事都能通过口头完成记录。

华为表示,所有记忆内容都是在用户授权下完成,会充分保护用户隐私。
此外小艺建议如今也可以感知到更多用户的高频场景,能主动提供一站式的智慧组合建议,省去很多自己手动查找的过程。
比如在出境旅游的场景下,出发前小艺能实时提醒最新汇率、兑换外币、帮助用户即时获取目的地游玩攻略;到达目的地后,还能提醒行李转盘信息、一键开启境外流量、快速获取实时翻译工具等。
据介绍,全新小艺智慧场景增加3倍,POI数量提升了7倍,能够覆盖核心餐饮购物门店、商圈、机场高铁站等场景。
总结来看,全新小艺不仅获得了最新的AIGC能力,还改善了手机语音助手过去经常被诟病的一些短板。
如没有记忆力、对话呆板、听不懂大白话等……
这一切当然得益于大模型的加持,不过小艺具体是怎么做的?
小艺拥抱大模型
小艺依托的底层模型是华为盘古系列。
今年7月,华为正式发布盘古大模型3.0,并提出3层模型架构。
L0:基础大模型,包括自然语言、视觉、多模态、预测、科学计算;
L1:N个行业大模型,比如政务、金融、制造、矿山、气象等;
L2:更细化场景的模型,提供“开箱即用”的模型服务
其中L0层基础大模型最大版本包含1000亿参数,预训练使用了超3万亿tokens。
小艺正是在华为盘古L0基座大模型的基础上,针对终端消费者场景构建了大量的场景数据,并对模型进行精调,最后炼成的L1层对话模型。

在精调中,小艺加入了覆盖终端消费者的主流数据类型,如对话、旅游攻略、设备操控、吃穿住行等。
这能很好覆盖普通用户日常对话的知识范围,并且可以增强模型对话过程中的事实性、实时性以及安全合规等。
不过众所周知,大模型因为规模大的特性,在部署和快速响应上都很有挑战。
部署方面,华为正在不断增强大模型端云协同的能力,端侧大模型可以先对用户请求和上下文信息做一层预处理,再将预处理后的request请求到云侧。
这样做的好处是,既能发挥端侧模型响应快的优势,又能通过云端模型来提升问答和响应质量,同时也能更进一步保护用户隐私数据。
而在降低推理时延上,华为小艺做了系统性工程优化,包含从底层芯片、推理框架、模型算子、输入输出长度等全链路。
通过对各个模块时延进行拆解,研发团队明确了各部分优化目标,利用算子融合、显存优化、pipeline优化等方式降低时延。
同时prompt长度和输出长度也会影响大模型推理速度。
在这方面,华为针对不同场景的prompt和输出格式做了逐字分析和压缩,最终实现推理时延减半。
从整体技术架构来看,华为小艺和大模型的融合,不是简单对聊天、AIGC、回复等任务进行增强,而是以大模型为核心,进行了系统级增强。
换言之,就是让大模型成为系统的“大脑”。
其底层逻辑是:将用户的任务分配给合适的系统,各个系统各司其职,同时在复杂场景上增强体验。
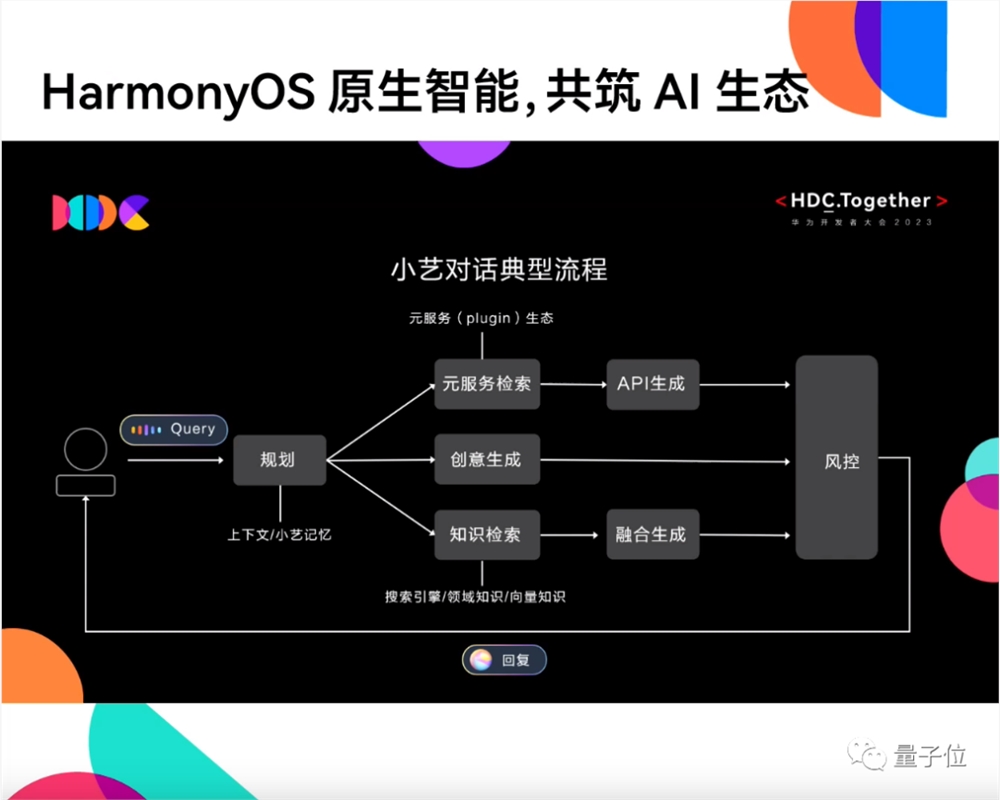
具体来看小艺的典型对话流程,一共可分为三步:
第一步,接收用户问题,基于上下文理解/小艺记忆的能力,分析问题该如何处理。
第二步,根据请求类型调用不同能力,包括元服务检索、创意生成、知识检索。
如果用户发起的请求涉及到元服务,比如他询问附近有哪些可以聚会的餐厅,这就涉及到了美食APP服务的调用,系统需要API生成,最后由服务方基于推荐机制给出响应。
如果用户询问的是知识问题,比如问盘古大模型有多少参数。这时系统会调用搜索引擎、对应领域知识、向量知识进行查询,然后融合生成答案。
如果用户的请求是生成式任务,那么大模型自身能力即可给出回复。
最后一步,所有生成的回答会经过风控评估,再返还给用户。
除此之外,小艺在细节上也做了更进一步的把控,进行了一系列底层开发,以确保问答、执行任务的效果。
可以来看数据方面。
小艺从2017年起在HarmonyOS上线后,对普通用户的对话习惯已经有了一定积累。在此之上,华为又构建了大量不同类型表达的语料库,尽可能覆盖更多文字和口语表达,让大模型在预训练阶段中就能精通各种表达。
为了能更好评估提升小艺能力,华为构建了一个完整测试数据集。
这不仅能评测现有开放大模型能力,也能基于评测结果指导小艺在数据和能力上的构建。
想让小艺掌握工具调用,挑战性也很高。
设备控制需要大模型生成长达数百个token的复杂格式文本,其中不能出现任何格式错误,否则中控系统将无法解析和对接。
为了让大模型能达到如此生成标准,华为一方面用prompt摸清楚大模型的“脾气”,同时加强大模型的代码能力,进而增强模型的格式遵从能力,最终实现了格式几乎百分百遵从。
而针对复杂场景,小艺的方式是先利用大模型能力充分学习和理解工具场景,再进行推理。
据了解,团队优化模型设备控制效果从完全不可用,提升为可用度超8成。
加之原生HarmonyOS也使得优化现有API成为可能,通过这种反向适配,也能更好发挥大模型特长。
面向全场景、不局限于手机端
所以,为什么是华为能如此迅速将大模型能力部署到智慧助手上?
在底层基础研发的积累和攻关必不可少,不过还有一点值得关注——
华为选择了从实际场景做切入,来确定该如何让大模型和智慧助手乃至整个操作系统做结合。
用华为自己的话来说就是:
Talk is cheap. Show me the Demo.
而以上展示的诸多体验,也都来自于华为研发团队成员日常感知到的场景。
比如有人习惯上下班开车路上获取新闻,对于太长资讯只能看不方便听,所以在华为小艺中出现了资讯总结的功能。
还有人发现自己在写购物评论、生日祝福的时候总是词穷,所以华为小艺提供了文案生成功能。
而这种对场景体验的关注,是HarmonyOS的天生优势。
从诞生起,HarmonyOS便没有局限于手机端,而是面向多种终端、全场景。
如今已经打造出“1 8 N”全场景生态。
华为小艺现在也已部署在了1 8设备上,未来将结合全场景设备的业务形态,逐步把拥有大模型能力的小艺部署到消费者全场景体验之上。

而小艺作为一个AI驱动的智慧助手,从诞生起也在不断集成各种AI能力,如AI字幕、小艺朗读等。其背后研发团队,也始终关注AI与智慧助手的更多可能。
据透露,去年团队便留意到百亿规模的预训练模型结合prompt提示技术,已经可以带来非常不错的文本理解和生成能力了,并能在闲聊、问答、任务式对话上有应用。
随着最新一轮AI趋势爆发,RLHF给大模型带来显著提升,产业落地的大门正式开启。
今年生成式AI趋势发生以来,诸多应用都选择接入大模型能力、内置智慧助手。
但华为作为全球最懂操作系统的厂商之一,选择从更底层切入,用大模型来重塑OS。
更底层,意味着更彻底、更全面。
但对于研发来说,挑战也更大。
这不仅需要足够坚实的模型底座,还需要进行系统级的融合优化,同时也对场景理解、用户需求感知提出要求。
对应来看:华为是最早具有大模型能力的国内厂商之一;构建全栈AI开发能力;HarmonyOS覆盖7亿 设备……
由此,也就不难理解为什么华为小艺会快速接入大模型能力,让HarmonyOS4成为如今首个全面接入大模型的操作系统。
而作为全球最受关注的操作系统之一,HarmonyOS率先拥抱大模型,或许也会开启一种新范式,让人人打开手机就能体验大模型能力,不再局限于想象之中。
目前,华为已公布小艺测试计划:
全新小艺将在今年8月底开放邀请测试,并于晚些时候在搭载HarmonyOS4.0及以上的部分机型通过OTA升级体验,具体升级计划稍晚公布。
感兴趣的童鞋,可以来蹲蹲看~
微信音频放大招:免费听周杰伦,下一步做播客
谁能想到,微信竟让数亿网友“薅”到了周杰伦的羊毛。4月20日,微信更新了iOS8.0.36版本,其中最引人关注的莫过于可以在微信免费收听QQ音乐各种付费歌曲,直接让#微信可免费听周杰伦#这一话题登上了微博热搜,截至目前阅读量超过2.2亿次。实际上,不只是音乐,微信还支持用户收听类似播客内容。此次将触角伸向音频,是其发力图文、视频、直播多个领域之后,补足自身内容板块的又一重要动作。站长网2023-04-23 09:21:500000OpenAI再遭作家起诉侵权,要求法院阻止其“非法商业行为”
据路透社报道,美国人工智能公司OpenAI最近再遭一批作家起诉,指控其在训练ChatGPT聊天机器人时,未经授权使用了他们的受版权保护作品。这些作家包括获得普利策奖的作家迈克尔·沙伯恩(MichaelChabon)、戏剧家大卫·亨利·黄(DavidHenryHwang)等。站长网2023-09-12 09:52:180000黄仁勋:希望NVIDIA拥有5万名员工 配备1亿个AI助手
作为AI领域的领军企业,NVIDIA及其掌舵人黄仁勋始终走在创新的最前沿。黄仁勋对企业的未来充满信心,近期大胆提出未来将雇佣5万名员工的目标。目前,NVIDIA全球员工人数约为1.2万,其中硅谷约有5000人。若要实现5万名员工的目标,企业需要增加超过三倍的员工规模。除了对外提供AI解决方案外,黄仁勋也注重AI在企业内部的应用。他希望未来公司每个部门都配备数百万个AI助手,助力高效运作。0000全国首个“空地协同”智慧物流中心启用:跨城快递3小时送达
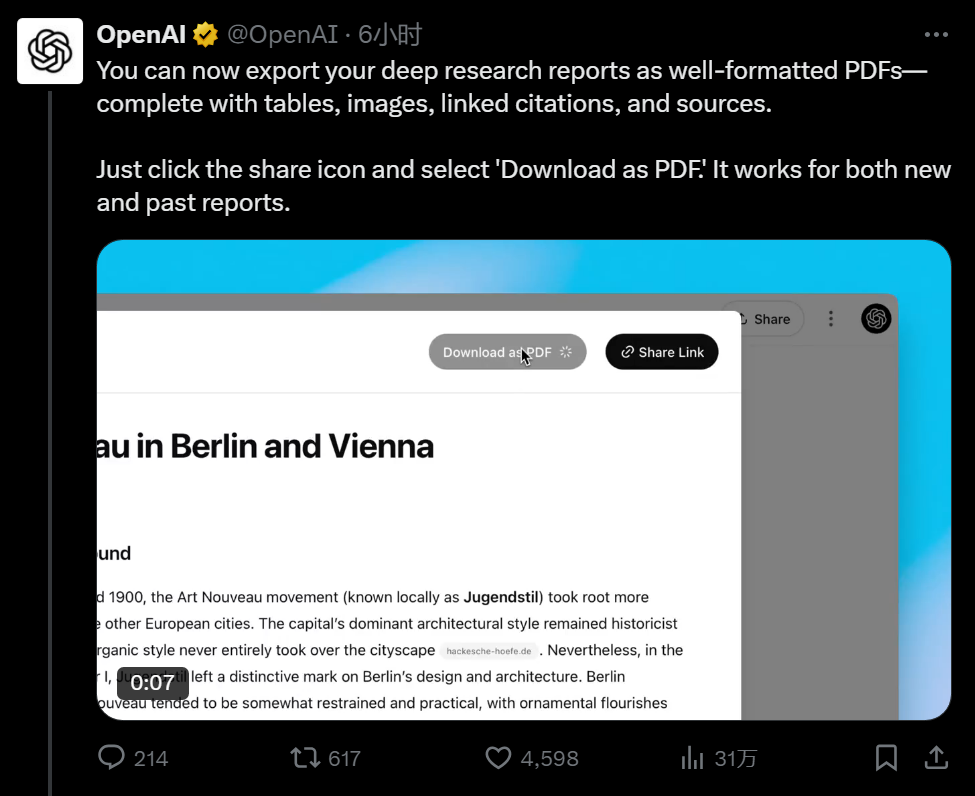
快科技2月14日消息,全国首个空地协同”智慧物流运营中心-丰翼宝安低空智慧物流运营中心今天正式启用。据了解,该运营中心位于深圳市宝安区新安街道,主体为二层钢结构建筑,占地900平方米,集无人机起降平台、物流交互设施、通讯网络等自动化智能化设备于一体。第一层为顺丰速运智慧网点,配置分拣机、皮带机、分拣台等智能设备。0000ChatGPT深度研究新增“PDF导出”功能,格式完整保留
OpenAI为其深度研究(Deepresearch)推出了一项新的PDF导出功能,让用户能够下载表格、图像以及可点击引文均完整保留的综合研究报告。这一看似不起眼的更新表明,随着人工智能研究助理市场竞争的加剧,该公司对企业客户的关注度日益加深。站长网2025-05-13 13:56:510000