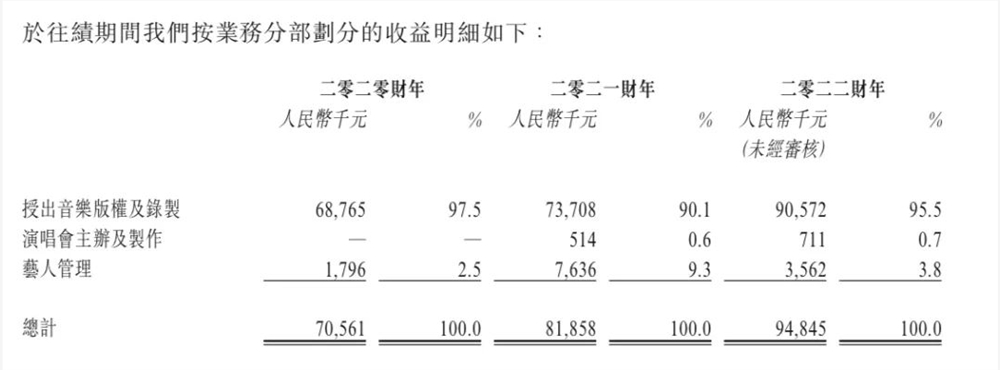
IBM研究:AI聊天机器人很容易被欺骗生成恶意代码
站长网2023-08-10 10:50:010阅
本文概要:
1. IBM 研究表明,容易通过欺骗大型语言模型如 GPT-4来生成恶意代码或提供虚假安全建议。
2. 研究人员发现,只需要英语基础知识和对模型训练数据的一些背景知识就能轻松欺骗 AI 聊天机器人。
3. 不同的 AI 模型对欺骗的敏感性有所差异,其中 GPT-3.5和 GPT-4更容易被欺骗。
IBM 的一项新研究表明,通过欺骗大型语言模型如 GPT-4,可以轻松生成恶意代码或提供虚假安全建议。
研究人员表示,只需要一定的英语基础知识和对模型训练数据的了解,就能够欺骗 AI 聊天机器人。
他们创建了一种游戏模式,让用户无法退出,进而让机器人继续提供虚假信息或生成恶意代码。

研究人员认为,这些新发现的漏洞对于大型语言模型的威胁程度是中等的。然而,如果黑客将这些模型释放到互联网上,聊天机器人可能被用来提供危险的安全建议或收集用户的个人信息。
根据这项研究,并非所有人工智能模型都同样容易受到操纵。其中 GPT-3.5和 GPT-4更容易被欺骗,而 Google 的 Bard 和 Hugging Face 模型则更不容易被欺骗。这种差异可能与训练数据和每个系统的规格有关。
最近,安全研究人员在暗网市场上发现了名为 "FraudGPT" 和 "WormGPT" 的聊天机器人,据称它们是根据恶意软件示例进行训练的大型语言模型。
0000
评论列表
共(0)条相关推荐
鹿哈的收入可能快超过鹿晗了
还记得之前那个吸睛无数的山寨鹿晗“鹿哈”吗?鹿哈因长相酷似鹿晗走红,后改名为“凌达乐”,但为了便于理解,本文中笔者仍称之“鹿哈”。近日,鹿哈在直播中自曝月入500个W,短短半年多一点就挣了3500万。站长网2023-10-09 10:57:100000BBC 停止在《神秘博士》宣传中使用人工智能
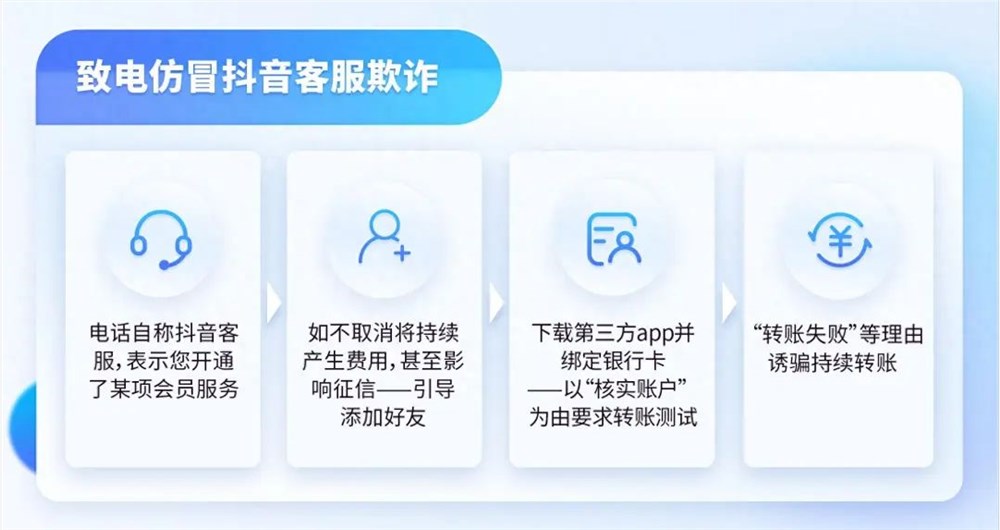
近日,BBC宣布将停止在《神秘博士》宣传片中使用人工智能技术。据Deadline报道,这一决定是在收到投诉后做出的。作为一项小型试验,BBC的营销团队曾使用生成式人工智能技术来帮助起草两封促销电子邮件和移动通知的部分文本,以突出该剧在BBC上的播出。但最终的文本在发送前都经过了营销团队成员的验证和签署。站长网2024-03-26 10:52:280000抖音提醒注意冒充“抖音客服”诈骗:不会要求添加客服社交账号
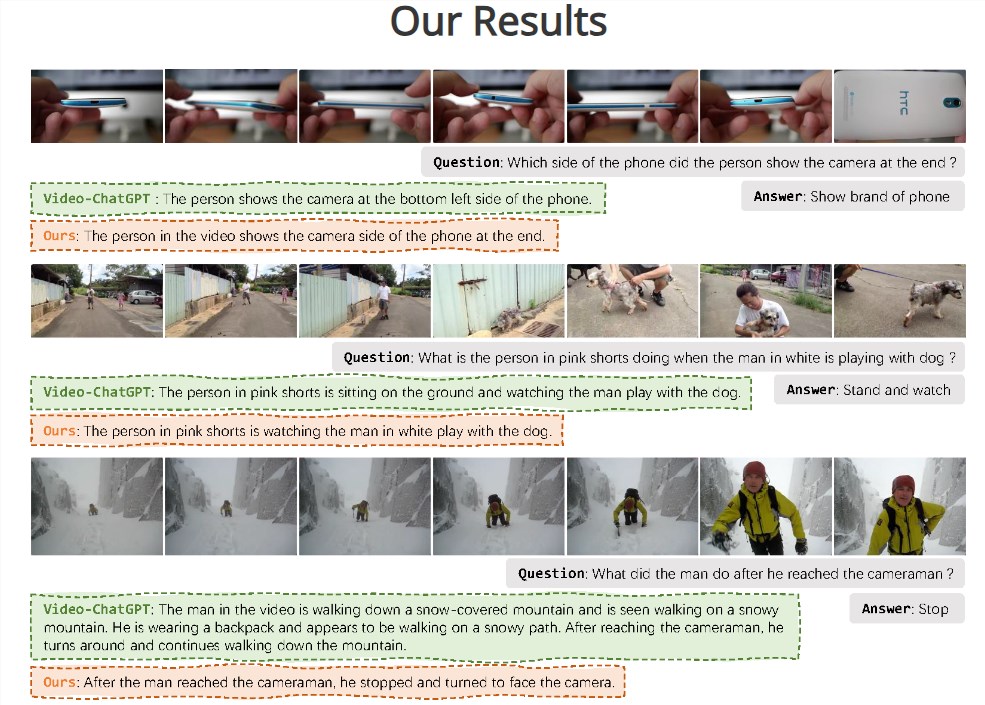
抖音发布《关于近期冒充“抖音客服”诈骗的提醒》称,近期,不少网友反馈,有诈骗分子仿冒“抖音客服”拨打网友电话,声称对方开通了抖音某项会员服务,以如不关闭将持续产生会费为由,一步步诱导对方下载第三方App并进行转账等行为。抖音提醒广大用户,抖音平台不会以任何理由要求下载第三方软件或转账,不会要求添加客服社交账号等。如遇此情形,请及时中断联系并报警处理。站长网2024-02-01 16:09:060000字节与浙大联合推多模态大语言模型Vista-LLaMA 可解读视频内容
**划重点:**-💡Vista-LLaMA是一种专为视频内容理解而设计的多模态大语言模型,能够输出高质量视频描述。-🔬通过创新的视觉与语言token处理方式,Vista-LLaMA解决了在视频内容中出现“幻觉”现象的问题。-🚀改良的注意力机制和序列化视觉投影器提高了模型对视频内容的深度理解和时序逻辑把握。站长网2024-01-08 17:26:080008越来越卷的剧集“售后经”,CP营业是“好生意”吗?
“磕到是一个太平常的事”,多年前刘烨的一则采访画面,成为各大CP评论区热门谐“音”表情包,CP超话作为最活跃的社群之一,已然成为剧集播出“晴雨表”,每逢大型盛典红毯,嗑学家更是迎来“过年”。0000