清华发布SmartMoE:支持用户一键实现 MoE 模型分布式训练
清华大学计算机系 PACMAN 实验室发布了一种稀疏大模型训练系统 SmartMoE,该系统支持用户一键实现 Mixture-of-Experts(MoE)模型的分布式训练,并通过自动搜索并行策略来提高训练性能。
论文地址:https://www.usenix.org/system/files/atc23-zhai.pdf
项目地址:https://github.com/zms1999/SmartMoE
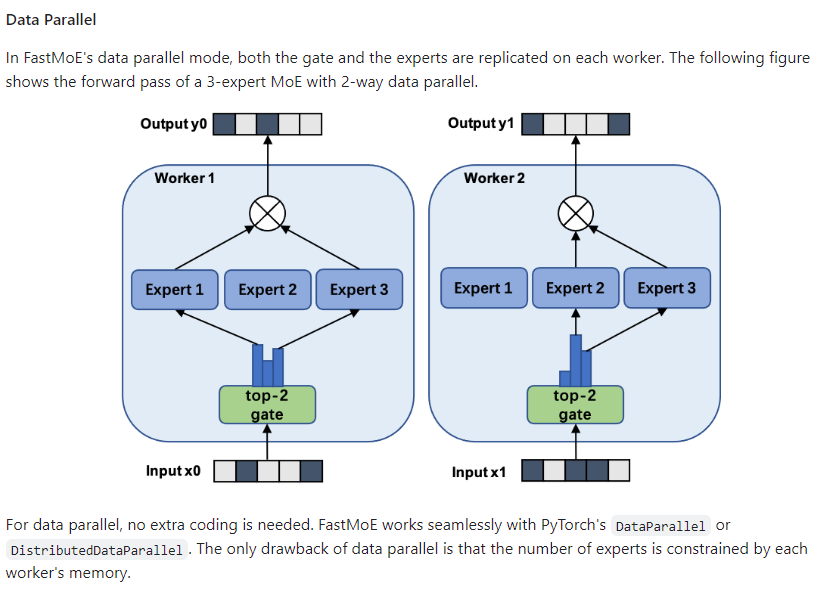
MoE 是一种模型稀疏化技术,通过将小模型转化为多个稀疏激活的小模型来扩展模型参数量。然而,传统的专家并行技术在训练 MoE 模型时存在性能问题,因为稀疏激活模式导致节点间不规则的 all-to-all 通信增加延迟和计算负载不均。

为了解决这些问题,SmartMoE 系统设计了专家放置策略和自动并行算法。通过对常用并行策略的支持和动态负载均衡,SmartMoE 系统在性能测试中表现出较高的加速比。
该系统的特点包括:
支持常用并行策略:SmartMoE 系统对数据并行、流水线并行、模型并行和专家并行等四种并行策略进行了全面的支持,并允许用户任意组合这些策略。
专家放置策略:为了处理 MoE 模型的动态计算负载,SmartMoE 系统设计了专家放置策略,根据当前负载调整专家的放置顺序,实现节点间的负载均衡。
两阶段自动并行算法:为了提高 MoE 模型复杂混合并行策略的易用性,SmartMoE 系统设计了一套轻量级且有效的两阶段自动并行算法。这个算法将自动并行搜索过程分为训练开始前的搜索和训练过程中的动态调整两个阶段,以减少搜索的开销。
高性能:在性能测试中,SmartMoE 在不同模型结构、集群环境和规模下都表现出优异的性能。相较于之前的 FasterMoE 系统,SmartMoE 能够实现高达1.88倍的加速比。
总之,SmartMoE 是一种可以一键实现高性能 MoE 稀疏大模型分布式训练的系统,具有支持多种并行策略、专家放置策略和两阶段自动并行算法的特点。通过这些特点,SmartMoE 系统能够提高 MoE 模型的易用性和训练性能,助力 MoE 大模型的发展。
苹果在英国推出iPhone的轻触支付 支持iPhone XS以上机型
据macrumors消息,苹果公司宣布在英国推出了iPhone上的TaptoPay(轻触支付)功能,让该国的独立卖家、小商户和大型零售商可以使用iPhone作为支付终端。这项功能于2022年2月推出,允许兼容的iPhone通过ApplePay、无接触式信用卡和借记卡以及其他数字钱包接受支付,只需要一部iPhone,无需额外的硬件或信用卡机。站长网2023-07-14 01:57:490000年入百亿美金追平TikTok,Meta家的短视频这次真行了?
报告显示,Meta第三季度营收为341.46亿美元,较去年同期的277.14亿美元增长23%;净利润为115.83亿美元,较去年同期的43.95亿美元同比大增164%。站长网2023-10-27 20:45:570002vivo与蔡司签署全新联合研发扩展协议 开发更出色影像
站长之家(ChinaZ.com)5月9日消息:vivo宣布与全球光学巨头蔡司再度携手,共同签署了一份全新的联合研发扩展协议,旨在深化双方在移动光学领域的合作,共同探索影像技术的创新与突破。站长网2024-05-09 16:45:180000靠AIGC翻身,又遇比特币大涨,蔡文胜的美图「赌赢」了?
有这样一家曾因“炒币”亏损而上热搜的公司,在兜兜转转尝试无数赛道数年、亏损近20亿元后,转身发现自己一直守着的主营业务,在AI能力的加持之下,居然是这么大的一座金矿......3月15日,美图公司发布其2023年年度报告,财报显示,公司2023年营收收入约26.96亿元,同比增长29.27%,净利润为3.78亿元,同比增长301.8%。站长网2024-03-18 10:40:220000大厂离职博主,卷向海外
离开大厂的离职博主,走上了带年轻人走进大厂的道路。90后离职博主小羚就是其中之一,因为入局早,小羚曾享受过离职博主的红利,靠为粉丝提供简历修改和职业规划等服务,月收入近万元。但伴随着越来越多离职大厂人涌入,离职博主的流量密码逐渐失效。小羚所在的职场咨询赛道也迎来了更多抢食者,客单价越卷越低,赚钱越来越难。0000