Meta 停止披露用于训练巨型生成式 AI 模型 Llama 2 的数据来源
版权问题引发大规模的生成式人工智能争议,Meta 试图以不公开训练数据的方式规避争议。

周二,社交媒体巨头 Meta 发布了一款名为 Llama 2 的庞大新模型,但在研究论文中几乎没有透露使用了哪些数据。「新的公开可用的在线数据,」Meta 的研究人员在论文中写道,几乎没有其他信息。
这是不同寻常的。迄今为止,人工智能行业一直对模型的训练数据持开放态度。原因在于:这种强大的技术必须被理解,其输出必须尽可能地可解释和可追溯,以便研究人员在出现问题时可以进行修复。训练数据对这些模型的性能至关重要。
例如,原始的 Transformer 研究论文揭示了用于训练的详细数据。其中包括来自WSJ 的约 40,000 个句子。
Meta 在今年二月发布第一版 LLaMA 时,论文中列出了所有的训练数据。它包括一堆图书和 Common Crawl 数据集,这是一个自 2008 年以来积累的庞大互联网副本,存储在亚马逊的云端,随时可以下载。该数据集占 Meta 用于训练 LLaMA 的信息的三分之二以上。
而在过去五个月里,出版商、作家和其他创作者突然意识到他们的作品被用于训练所有这些人工智能模型。他们并没有被征求许可。
已经有一系列诉讼挑战了科技公司使用这些信息训练 AI 模型的权利。Sarah Silverman的投诉可能是迄今为止最有名的一个。
对于大型科技公司来说,他们知道这是一个风险。微软作为产业领导者 OpenAI 的支持者,最近在其季度 SEC 文件中增加了这个风险因素。微软在四月份增加的新部分中强调了版权作为知识产权法的重要组成部分。
谷歌,作为另一个人工智能领域的领导者,不愿为在线内容付费,因为这会削弱其高盈利的商业模式。谷歌的高级法律顾问 Halimah DeLaine Prado 表示,美国法律「支持使用公共信息来创造新的有益用途」,这一观点在法庭上可能占上风。
而 Meta 似乎已经认定,在这个新法律问题得到解决之前,不告诉任何人使用了哪些数据是一个安全的做法。
此外,Meta 可能还有其他原因保持沉默。Lamini AI 创业公司的 CEO Sharon Zhou 提出了一些理论,包括最具争议的一点:Meta 在规避法律责任,公司想要保留将 Llama 2 复制的能力,也有可能是因为整理所有元数据是很费时的工作,所以 Meta 可能会在合适的时候发布训练数据的细节。
对此,Meta 表示,他们将发布模型权重和起始代码,以供开发者使用,并强调他们致力于负责任和道德的开发生成式 AI 产品,确保他们的政策符合不同背景的要求和不断变化的社会期望。
Stability AI一高管因版权争议辞职 反对公司未经许可使用版权作品
**划重点:**1.🚫StabilityAI高管辞职,指责公司认为可在培训产品时使用他人创作而不需许可。2.🤝AI公司主张“公平使用”,认为无需原创内容所有者的许可。3.🎼高管辞职者强调希望全球采取“需获得创作者许可”的伦理道路。站长网2023-11-17 17:14:590002Hinton揭秘Ilya成长历程:Scaling Law是他学生时代就有的直觉
2003年夏天的一个周日,AI教父Hinton在多伦多大学的办公室里敲代码,突然响起略显莽撞的敲门声。门外站着一位年轻的学生,说自己整个夏天都在打工炸薯条,但更希望能加入Hinton的实验室工作。Hinton问,你咋不预约呢?预约了我们才能好好谈谈。学生反问,要不就现在吧?站长网2024-05-27 16:34:330000华硕子公司发布福尔摩斯大模型Formosa Foundation Model
根据华硕官方消息,华硕旗下子公司台智云(TWS)在AIHPCconAI超算年会上发布了企业级大型语言模型——“福尔摩斯大模型”(FormosaFoundationModel)。“福尔摩斯大模型”共有1760亿个参数,可以与ChatGPT的GPT-3.5模型相媲美,支持多国语言。站长网2023-05-22 09:11:220001新能源汽车开门红:1月销量、渗透率创同期历史新高
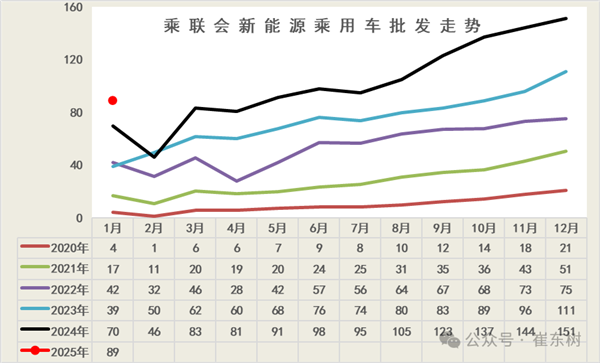
快科技2月15日消息,根据乘联会秘书长崔东树最新撰文,2025年1月新能源乘用车批发销量达到89万辆,同比增长27%,超越同期历史最高水平。1月传统车厂家批发同比下降13%,而新能源车零售同比上升27%,增速差距40个点,燃油车压力较大。与此同时,新能源汽车渗透率也创历年1月最高水平,1月新能源车厂商批发渗透率41.5%,较2024年1月提升9个百分点。站长网2025-02-16 10:48:120000央视新闻启动鸿蒙原生应用开发 余承东亲临现场
在央视新闻新媒体2024年创新节目片单发布会上,央视新闻客户端宣布推出全新的10.0版本,并计划发布鸿蒙原生应用,进一步拓宽其技术边界和应用场景。此次发布会上,华为消费者业务CEO余承东亲临现场,为鸿蒙系统站台,并阐述了鸿蒙系统如何为产业带来新机遇。余承东强调,鸿蒙系统已拥有全栈自研技术,其内核超越了传统系统,更适应全场景设备的多样化需求。站长网2024-02-07 14:03:110000